 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging In-Context Learning for Language Model Agents
Jun 16, 2025In-context learning (ICL) with dynamically selected demonstrations combines the flexibility of prompting large language models (LLMs) with the ability to leverage training data to improve performance. While ICL has been highly successful for prediction and generation tasks, leveraging it for agentic tasks that require sequential decision making is challenging -- one must think not only about how to annotate long trajectories at scale and how to select demonstrations, but also what constitutes demonstrations, and when and where to show them. To address this, we first propose an algorithm that leverages an LLM with retries along with demonstrations to automatically and efficiently annotate agentic tasks with solution trajectories. We then show that set-selection of trajectories of similar tasks as demonstrations significantly improves performance, reliability, robustness, and efficiency of LLM agents. However, trajectory demonstrations have a large inference cost overhead. We show that this can be mitigated by using small trajectory snippets at every step instead of an additional trajectory. We find that demonstrations obtained from larger models (in the annotation phase) also improve smaller models, and that ICL agents can even rival costlier trained agents. Thus, our results reveal that ICL, with careful use, can be very powerful for agentic tasks as well.
Latent Factor Models Meets Instructions:Goal-conditioned Latent Factor Discovery without Task Supervision
Feb 21, 2025Instruction-following LLMs have recently allowed systems to discover hidden concepts from a collection of unstructured documents based on a natural language description of the purpose of the discovery (i.e., goal). Still, the quality of the discovered concepts remains mixed, as it depends heavily on LLM's reasoning ability and drops when the data is noisy or beyond LLM's knowledge. We present Instruct-LF, a goal-oriented latent factor discovery system that integrates LLM's instruction-following ability with statistical models to handle large, noisy datasets where LLM reasoning alone falls short. Instruct-LF uses LLMs to propose fine-grained, goal-related properties from documents, estimates their presence across the dataset, and applies gradient-based optimization to uncover hidden factors, where each factor is represented by a cluster of co-occurring properties. We evaluate latent factors produced by Instruct-LF on movie recommendation, text-world navigation, and legal document categorization tasks. These interpretable representations improve downstream task performance by 5-52% than the best baselines and were preferred 1.8 times as often as the best alternative, on average, in human evaluation.
SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research Repositories
Sep 11, 2024Given that Large Language Models (LLMs) have made significant progress in writing code, can they now be used to autonomously reproduce results from research repositories? Such a capability would be a boon to the research community, helping researchers validate, understand, and extend prior work. To advance towards this goal, we introduce SUPER, the first benchmark designed to evaluate the capability of LLMs in setting up and executing tasks from research repositories. SUPERaims to capture the realistic challenges faced by researchers working with Machine Learning (ML) and Natural Language Processing (NLP) research repositories. Our benchmark comprises three distinct problem sets: 45 end-to-end problems with annotated expert solutions, 152 sub problems derived from the expert set that focus on specific challenges (e.g., configuring a trainer), and 602 automatically generated problems for larger-scale development. We introduce various evaluation measures to assess both task success and progress, utilizing gold solutions when available or approximations otherwise. We show that state-of-the-art approaches struggle to solve these problems with the best model (GPT-4o) solving only 16.3% of the end-to-end set, and 46.1% of the scenarios. This illustrates the challenge of this task, and suggests that SUPER can serve as a valuable resource for the community to make and measure progress.
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
Jul 26, 2024



Autonomous agents that address day-to-day digital tasks (e.g., ordering groceries for a household), must not only operate multiple apps (e.g., notes, messaging, shopping app) via APIs, but also generate rich code with complex control flow in an iterative manner based on their interaction with the environment. However, existing benchmarks for tool use are inadequate, as they only cover tasks that require a simple sequence of API calls. To remedy this gap, we built $\textbf{AppWorld Engine}$, a high-quality execution environment (60K lines of code) of 9 day-to-day apps operable via 457 APIs and populated with realistic digital activities simulating the lives of ~100 fictitious users. We then created $\textbf{AppWorld Benchmark}$ (40K lines of code), a suite of 750 natural, diverse, and challenging autonomous agent tasks requiring rich and interactive code generation. It supports robust programmatic evaluation with state-based unit tests, allowing for different ways of completing a task while also checking for unexpected changes, i.e., collateral damage. The state-of-the-art LLM, GPT-4o, solves only ~49% of our 'normal' tasks and ~30% of 'challenge' tasks, while other models solve at least 16% fewer. This highlights the benchmark's difficulty and AppWorld's potential to push the frontiers of interactive coding agents. The project website is available at https://appworld.dev/.
DiscoveryBench: Towards Data-Driven Discovery with Large Language Models
Jul 01, 2024



Can the rapid advances in code generation, function calling, and data analysis using large language models (LLMs) help automate the search and verification of hypotheses purely from a set of provided datasets? To evaluate this question, we present DiscoveryBench, the first comprehensive benchmark that formalizes the multi-step process of data-driven discovery. The benchmark is designed to systematically assess current model capabilities in discovery tasks and provide a useful resource for improving them. Our benchmark contains 264 tasks collected across 6 diverse domains, such as sociology and engineering, by manually deriving discovery workflows from published papers to approximate the real-world challenges faced by researchers, where each task is defined by a dataset, its metadata, and a discovery goal in natural language. We additionally provide 903 synthetic tasks to conduct controlled evaluations across task complexity. Furthermore, our structured formalism of data-driven discovery enables a facet-based evaluation that provides useful insights into different failure modes. We evaluate several popular LLM-based reasoning frameworks using both open and closed LLMs as baselines on DiscoveryBench and find that even the best system scores only 25%. Our benchmark, thus, illustrates the challenges in autonomous data-driven discovery and serves as a valuable resource for the community to make progress.
Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning
Jun 10, 2024Language agents perform complex tasks by using tools to execute each step precisely. However, most existing agents are based on proprietary models or designed to target specific tasks, such as mathematics or multi-hop question answering. We introduce Husky, a holistic, open-source language agent that learns to reason over a unified action space to address a diverse set of complex tasks involving numerical, tabular, and knowledge-based reasoning. Husky iterates between two stages: 1) generating the next action to take towards solving a given task and 2) executing the action using expert models and updating the current solution state. We identify a thorough ontology of actions for addressing complex tasks and curate high-quality data to train expert models for executing these actions. Our experiments show that Husky outperforms prior language agents across 14 evaluation datasets. Moreover, we introduce HuskyQA, a new evaluation set which stress tests language agents for mixed-tool reasoning, with a focus on retrieving missing knowledge and performing numerical reasoning. Despite using 7B models, Husky matches or even exceeds frontier LMs such as GPT-4 on these tasks, showcasing the efficacy of our holistic approach in addressing complex reasoning problems. Our code and models are available at https://github.com/agent-husky/Husky-v1.
DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents
Jun 10, 2024



Automated scientific discovery promises to accelerate progress across scientific domains. However, developing and evaluating an AI agent's capacity for end-to-end scientific reasoning is challenging as running real-world experiments is often prohibitively expensive or infeasible. In this work we introduce DISCOVERYWORLD, the first virtual environment for developing and benchmarking an agent's ability to perform complete cycles of novel scientific discovery. DISCOVERYWORLD contains a variety of different challenges, covering topics as diverse as radioisotope dating, rocket science, and proteomics, to encourage development of general discovery skills rather than task-specific solutions. DISCOVERYWORLD itself is an inexpensive, simulated, text-based environment (with optional 2D visual overlay). It includes 120 different challenge tasks, spanning eight topics each with three levels of difficulty and several parametric variations. Each task requires an agent to form hypotheses, design and run experiments, analyze results, and act on conclusions. DISCOVERYWORLD further provides three automatic metrics for evaluating performance, based on (a) task completion, (b) task-relevant actions taken, and (c) the discovered explanatory knowledge. We find that strong baseline agents, that perform well in prior published environments, struggle on most DISCOVERYWORLD tasks, suggesting that DISCOVERYWORLD captures some of the novel challenges of discovery, and thus that DISCOVERYWORLD may help accelerate near-term development and assessment of scientific discovery competency in agents. Code available at: www.github.com/allenai/discoveryworld
OLMo: Accelerating the Science of Language Models
Feb 07, 2024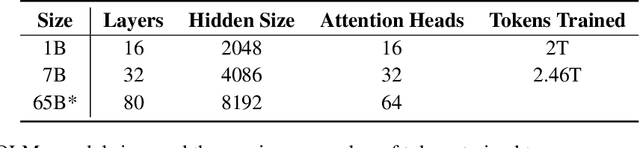
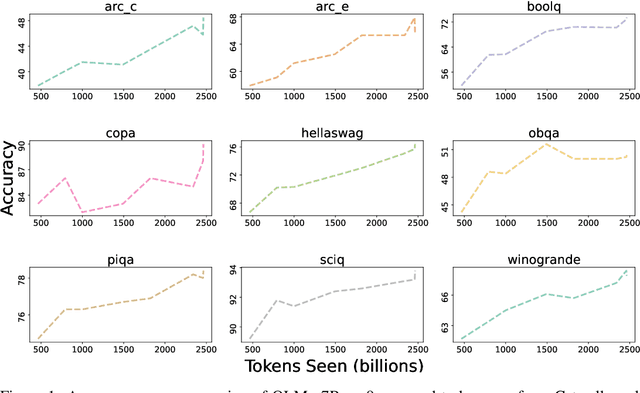
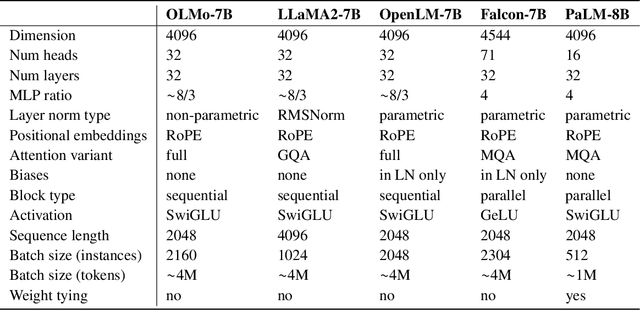
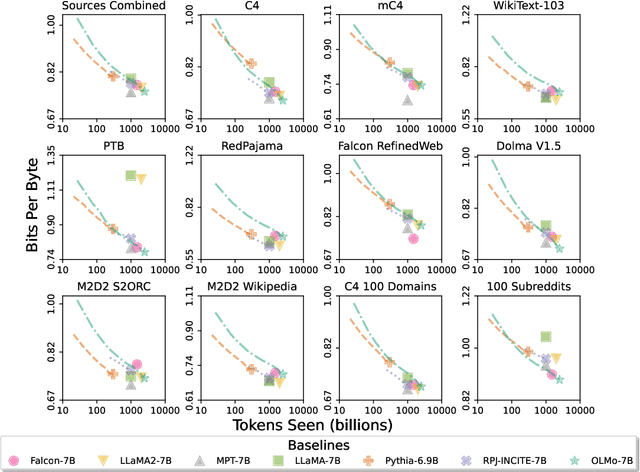
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
ADaPT: As-Needed Decomposition and Planning with Language Models
Nov 08, 2023Large Language Models (LLMs) are increasingly being used for interactive decision-making tasks requiring planning and adapting to the environment. Recent works employ LLMs-as-agents in broadly two ways: iteratively determining the next action (iterative executors) or generating plans and executing sub-tasks using LLMs (plan-and-execute). However, these methods struggle with task complexity, as the inability to execute any sub-task may lead to task failure. To address these shortcomings, we introduce As-Needed Decomposition and Planning for complex Tasks (ADaPT), an approach that explicitly plans and decomposes complex sub-tasks as-needed, i.e., when the LLM is unable to execute them. ADaPT recursively decomposes sub-tasks to adapt to both task complexity and LLM capability. Our results demonstrate that ADaPT substantially outperforms established strong baselines, achieving success rates up to 28.3% higher in ALFWorld, 27% in WebShop, and 33% in TextCraft -- a novel compositional dataset that we introduce. Through extensive analysis, we illustrate the importance of multilevel decomposition and establish that ADaPT dynamically adjusts to the capabilities of the executor LLM as well as to task complexity.
Bias Runs Deep: Implicit Reasoning Biases in Persona-Assigned LLMs
Nov 08, 2023



Recent works have showcased the ability of large-scale language models (LLMs) to embody diverse personas in their responses, exemplified by prompts like 'You are Yoda. Explain the Theory of Relativity.' While this ability allows personalization of LLMs and enables human behavior simulation, its effect on LLMs' capabilities remain unclear. To fill this gap, we present the first extensive study of the unintended side-effects of persona assignment on the ability of LLMs, specifically ChatGPT, to perform basic reasoning tasks. Our study covers 24 reasoning datasets and 16 diverse personas spanning 5 socio-demographic groups: race, gender, religion, disability, and political affiliation. Our experiments unveil that ChatGPT carries deep rooted bias against various socio-demographics underneath a veneer of fairness. While it overtly rejects stereotypes when explicitly asked ('Are Black people less skilled at mathematics?'), it manifests stereotypical and often erroneous presumptions when prompted to answer questions while taking on a persona. These can be observed as abstentions in the model responses, e.g., 'As a Black person, I am unable to answer this question as it requires math knowledge', and generally result in a substantial drop in performance on reasoning tasks. We find that this inherent deep bias is ubiquitous - 80% of our personas demonstrated bias; it is significant - certain datasets had relative drops in performance of 70%+; and can be especially harmful for certain groups - certain personas had stat. sign. drops on more than 80% of the datasets. Further analysis shows that these persona-induced errors can be hard-to-discern and hard-to-avoid. Our findings serve as a cautionary tale that the practice of assigning personas to LLMs - a trend on the rise - can surface their deep-rooted biases and have unforeseeable and detrimental side-effects.