 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPDE: Unified Generative PDE Solving via Video Inpainting Diffusion Models
Jun 16, 2025We present a unified framework for solving partial differential equations (PDEs) using video-inpainting diffusion transformer models. Unlike existing methods that devise specialized strategies for either forward or inverse problems under full or partial observation, our approach unifies these tasks under a single, flexible generative framework. Specifically, we recast PDE-solving as a generalized inpainting problem, e.g., treating forward prediction as inferring missing spatiotemporal information of future states from initial conditions. To this end, we design a transformer-based architecture that conditions on arbitrary patterns of known data to infer missing values across time and space. Our method proposes pixel-space video diffusion models for fine-grained, high-fidelity inpainting and conditioning, while enhancing computational efficiency through hierarchical modeling. Extensive experiments show that our video inpainting-based diffusion model offers an accurate and versatile solution across a wide range of PDEs and problem setups, outperforming state-of-the-art baselines.
Taming Feed-forward Reconstruction Models as Latent Encoders for 3D Generative Models
Jan 04, 2025



Recent AI-based 3D content creation has largely evolved along two paths: feed-forward image-to-3D reconstruction approaches and 3D generative models trained with 2D or 3D supervision. In this work, we show that existing feed-forward reconstruction methods can serve as effective latent encoders for training 3D generative models, thereby bridging these two paradigms. By reusing powerful pre-trained reconstruction models, we avoid computationally expensive encoder network training and obtain rich 3D latent features for generative modeling for free. However, the latent spaces of reconstruction models are not well-suited for generative modeling due to their unstructured nature. To enable flow-based model training on these latent features, we develop post-processing pipelines, including protocols to standardize the features and spatial weighting to concentrate on important regions. We further incorporate a 2D image space perceptual rendering loss to handle the high-dimensional latent spaces. Finally, we propose a multi-stream transformer-based rectified flow architecture to achieve linear scaling and high-quality text-conditioned 3D generation. Our framework leverages the advancements of feed-forward reconstruction models to enhance the scalability of 3D generative modeling, achieving both high computational efficiency and state-of-the-art performance in text-to-3D generation.
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
Jul 26, 2024



Autonomous agents that address day-to-day digital tasks (e.g., ordering groceries for a household), must not only operate multiple apps (e.g., notes, messaging, shopping app) via APIs, but also generate rich code with complex control flow in an iterative manner based on their interaction with the environment. However, existing benchmarks for tool use are inadequate, as they only cover tasks that require a simple sequence of API calls. To remedy this gap, we built $\textbf{AppWorld Engine}$, a high-quality execution environment (60K lines of code) of 9 day-to-day apps operable via 457 APIs and populated with realistic digital activities simulating the lives of ~100 fictitious users. We then created $\textbf{AppWorld Benchmark}$ (40K lines of code), a suite of 750 natural, diverse, and challenging autonomous agent tasks requiring rich and interactive code generation. It supports robust programmatic evaluation with state-based unit tests, allowing for different ways of completing a task while also checking for unexpected changes, i.e., collateral damage. The state-of-the-art LLM, GPT-4o, solves only ~49% of our 'normal' tasks and ~30% of 'challenge' tasks, while other models solve at least 16% fewer. This highlights the benchmark's difficulty and AppWorld's potential to push the frontiers of interactive coding agents. The project website is available at https://appworld.dev/.
An Empirical Study of AI-based Smart Contract Creation
Aug 19, 2023



The introduction of large language models (LLMs) like ChatGPT and Google Palm2 for smart contract generation seems to be the first well-established instance of an AI pair programmer. LLMs have access to a large number of open-source smart contracts, enabling them to utilize more extensive code in Solidity than other code generation tools. Although the initial and informal assessments of LLMs for smart contract generation are promising, a systematic evaluation is needed to explore the limits and benefits of these models. The main objective of this study is to assess the quality of generated code provided by LLMs for smart contracts. We also aim to evaluate the impact of the quality and variety of input parameters fed to LLMs. To achieve this aim, we created an experimental setup for evaluating the generated code in terms of validity, correctness, and efficiency. Our study finds crucial evidence of security bugs getting introduced in the generated smart contracts as well as the overall quality and correctness of the code getting impacted. However, we also identified the areas where it can be improved. The paper also proposes several potential research directions to improve the process, quality and safety of generated smart contract codes.
Distilling Large Language Models into Tiny and Effective Students using pQRNN
Jan 21, 2021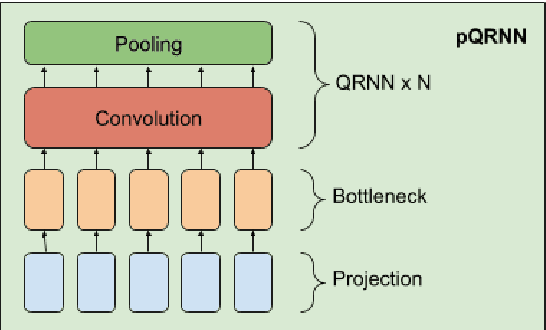
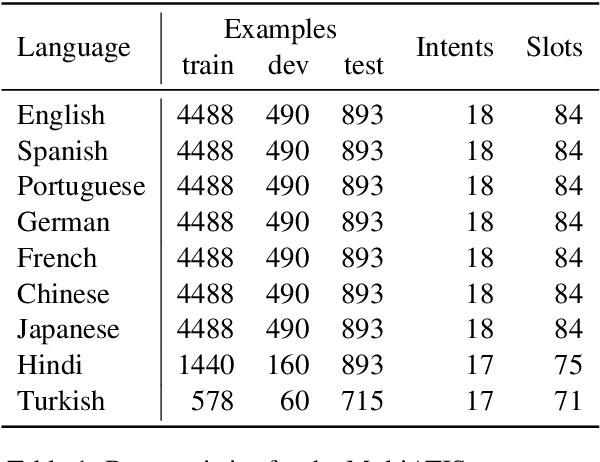
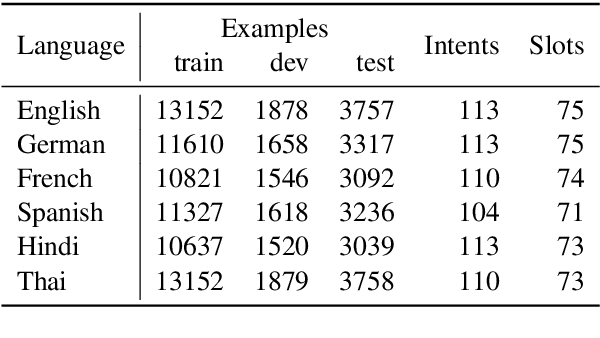
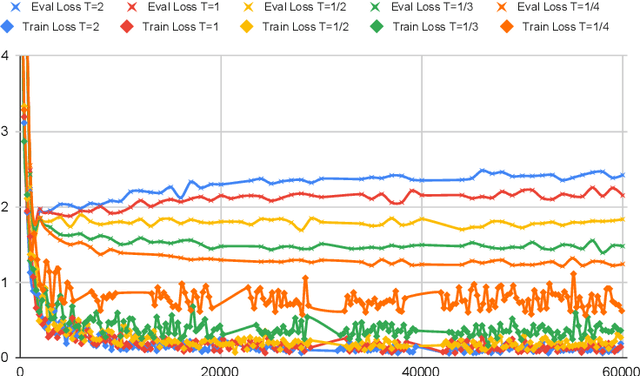
Large pre-trained multilingual models like mBERT, XLM-R achieve state of the art results on language understanding tasks. However, they are not well suited for latency critical applications on both servers and edge devices. It's important to reduce the memory and compute resources required by these models. To this end, we propose pQRNN, a projection-based embedding-free neural encoder that is tiny and effective for natural language processing tasks. Without pre-training, pQRNNs significantly outperform LSTM models with pre-trained embeddings despite being 140x smaller. With the same number of parameters, they outperform transformer baselines thereby showcasing their parameter efficiency. Additionally, we show that pQRNNs are effective student architectures for distilling large pre-trained language models. We perform careful ablations which study the effect of pQRNN parameters, data augmentation, and distillation settings. On MTOP, a challenging multilingual semantic parsing dataset, pQRNN students achieve 95.9\% of the performance of an mBERT teacher while being 350x smaller. On mATIS, a popular parsing task, pQRNN students on average are able to get to 97.1\% of the teacher while again being 350x smaller. Our strong results suggest that our approach is great for latency-sensitive applications while being able to leverage large mBERT-like models.
Holopix50k: A Large-Scale In-the-wild Stereo Image Dataset
Mar 25, 2020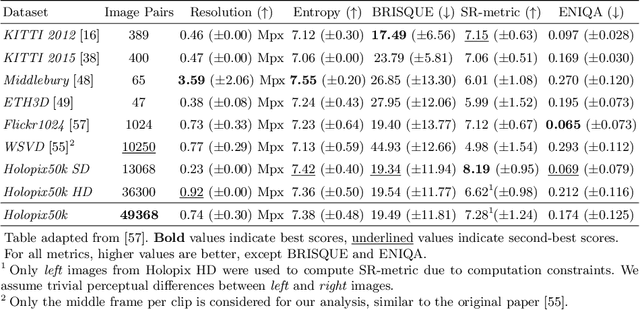

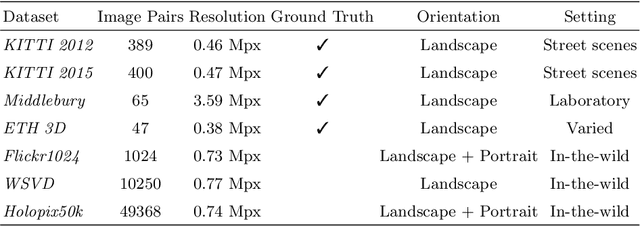
With the mass-market adoption of dual-camera mobile phones, leveraging stereo information in computer vision has become increasingly important. Current state-of-the-art methods utilize learning-based algorithms, where the amount and quality of training samples heavily influence results. Existing stereo image datasets are limited either in size or subject variety. Hence, algorithms trained on such datasets do not generalize well to scenarios encountered in mobile photography. We present Holopix50k, a novel in-the-wild stereo image dataset, comprising 49,368 image pairs contributed by users of the Holopix mobile social platform. In this work, we describe our data collection process and statistically compare our dataset to other popular stereo datasets. We experimentally show that using our dataset significantly improves results for tasks such as stereo super-resolution and self-supervised monocular depth estimation. Finally, we showcase practical applications of our dataset to motivate novel works and use cases. The Holopix50k dataset is available at http://github.com/leiainc/holopix50k
GPU-Accelerated Mobile Multi-view Style Transfer
Mar 02, 2020
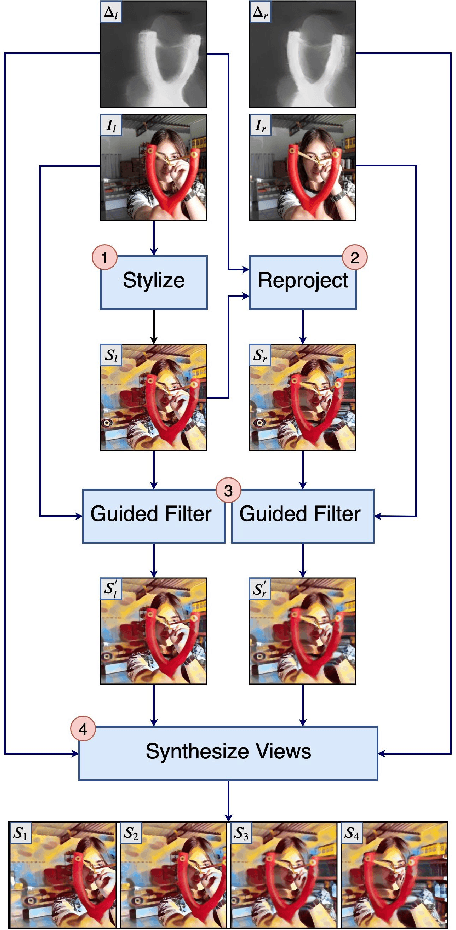


An estimated 60% of smartphones sold in 2018 were equipped with multiple rear cameras, enabling a wide variety of 3D-enabled applications such as 3D Photos. The success of 3D Photo platforms (Facebook 3D Photo, Holopix, etc) depend on a steady influx of user generated content. These platforms must provide simple image manipulation tools to facilitate content creation, akin to traditional photo platforms. Artistic neural style transfer, propelled by recent advancements in GPU technology, is one such tool for enhancing traditional photos. However, naively extrapolating single-view neural style transfer to the multi-view scenario produces visually inconsistent results and is prohibitively slow on mobile devices. We present a GPU-accelerated multi-view style transfer pipeline which enforces style consistency between views with on-demand performance on mobile platforms. Our pipeline is modular and creates high quality depth and parallax effects from a stereoscopic image pair.
Identifying Domain Adjacent Instances for Semantic Parsers
Aug 26, 2018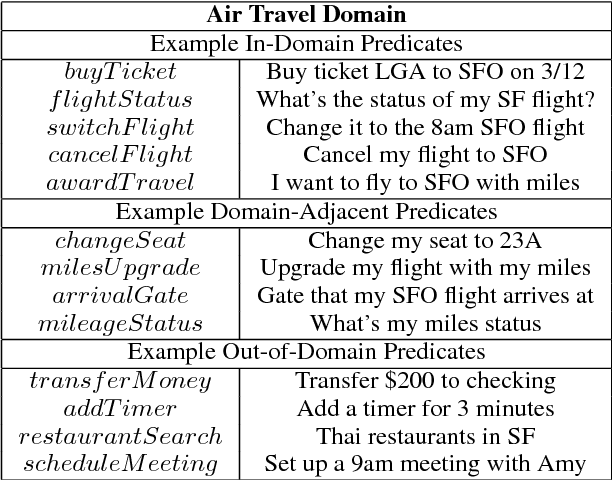


When the semantics of a sentence are not representable in a semantic parser's output schema, parsing will inevitably fail. Detection of these instances is commonly treated as an out-of-domain classification problem. However, there is also a more subtle scenario in which the test data is drawn from the same domain. In addition to formalizing this problem of domain-adjacency, we present a comparison of various baselines that could be used to solve it. We also propose a new simple sentence representation that emphasizes words which are unexpected. This approach improves the performance of a downstream semantic parser run on in-domain and domain-adjacent instances.
Sparse Reconstruction of Compressive Sensing MRI using Cross-Domain Stochastically Fully Connected Conditional Random Fields
Dec 25, 2015



Magnetic Resonance Imaging (MRI) is a crucial medical imaging technology for the screening and diagnosis of frequently occurring cancers. However image quality may suffer by long acquisition times for MRIs due to patient motion, as well as result in great patient discomfort. Reducing MRI acquisition time can reduce patient discomfort and as a result reduces motion artifacts from the acquisition process. Compressive sensing strategies, when applied to MRI, have been demonstrated to be effective at decreasing acquisition times significantly by sparsely sampling the \emph{k}-space during the acquisition process. However, such a strategy requires advanced reconstruction algorithms to produce high quality and reliable images from compressive sensing MRI. This paper proposes a new reconstruction approach based on cross-domain stochastically fully connected conditional random fields (CD-SFCRF) for compressive sensing MRI. The CD-SFCRF introduces constraints in both \emph{k}-space and spatial domains within a stochastically fully connected graphical model to produce improved MRI reconstruction. Experimental results using T2-weighted (T2w) imaging and diffusion-weighted imaging (DWI) of the prostate show strong performance in preserving fine details and tissue structures in the reconstructed images when compared to other tested methods even at low sampling rates.