 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Large Language Models into Tiny and Effective Students using pQRNN
Jan 21, 2021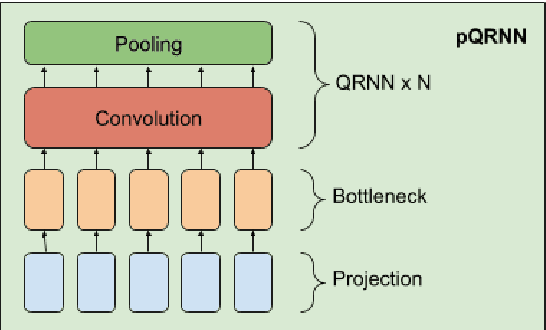
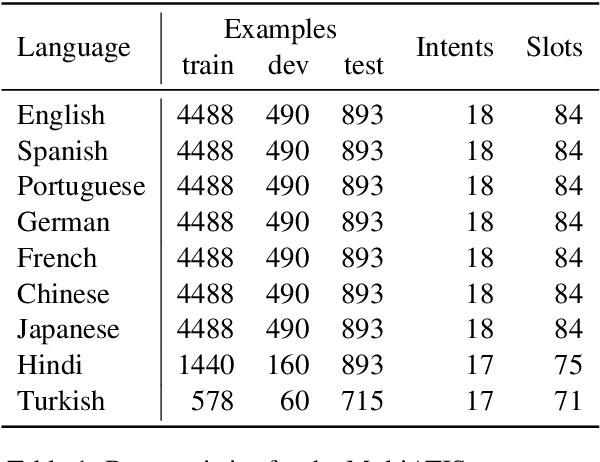
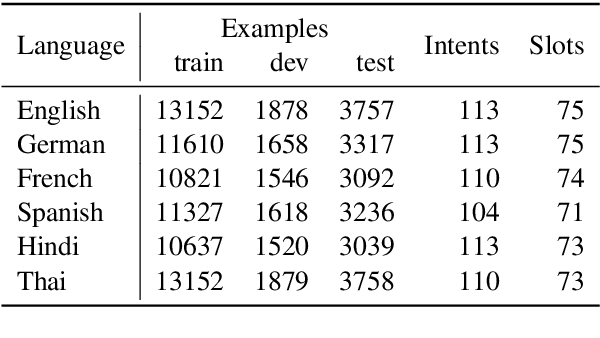
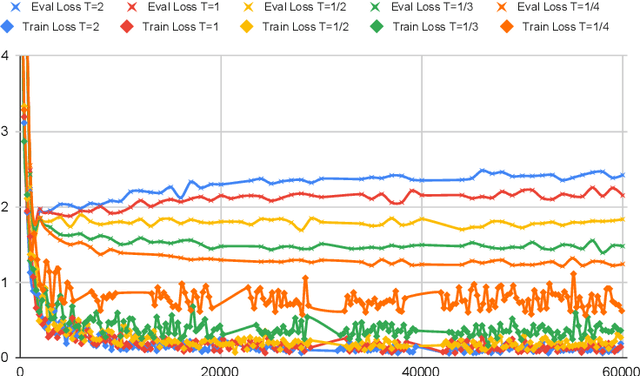
Large pre-trained multilingual models like mBERT, XLM-R achieve state of the art results on language understanding tasks. However, they are not well suited for latency critical applications on both servers and edge devices. It's important to reduce the memory and compute resources required by these models. To this end, we propose pQRNN, a projection-based embedding-free neural encoder that is tiny and effective for natural language processing tasks. Without pre-training, pQRNNs significantly outperform LSTM models with pre-trained embeddings despite being 140x smaller. With the same number of parameters, they outperform transformer baselines thereby showcasing their parameter efficiency. Additionally, we show that pQRNNs are effective student architectures for distilling large pre-trained language models. We perform careful ablations which study the effect of pQRNN parameters, data augmentation, and distillation settings. On MTOP, a challenging multilingual semantic parsing dataset, pQRNN students achieve 95.9\% of the performance of an mBERT teacher while being 350x smaller. On mATIS, a popular parsing task, pQRNN students on average are able to get to 97.1\% of the teacher while again being 350x smaller. Our strong results suggest that our approach is great for latency-sensitive applications while being able to leverage large mBERT-like models.
Parametric annealing: a stochastic search method for human pose tracking
May 02, 2012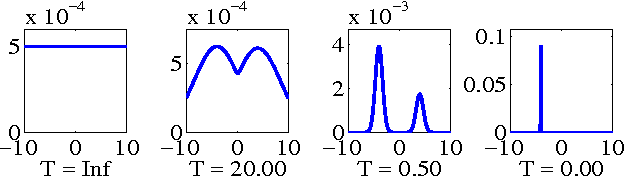

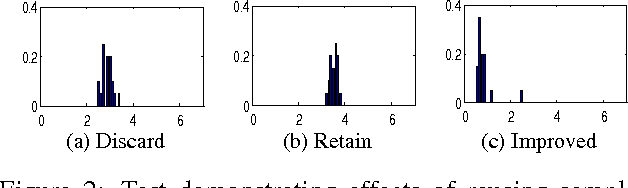
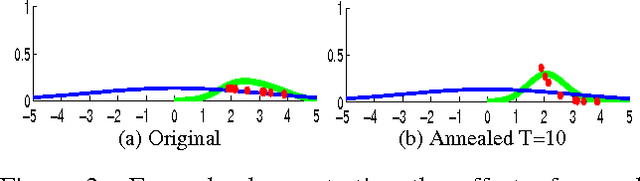
Model based methods to marker-free motion capture have a very high computational overhead that make them unattractive. In this paper we describe a method that improves on existing global optimization techniques to tracking articulated objects. Our method improves on the state-of-the-art Annealed Particle Filter (APF) by reusing samples across annealing layers and by using an adaptive parametric density for diffusion. We compare the proposed method with APF on a scalable problem and study how the two methods scale with the dimensionality, multi-modality and the range of search. Then we perform sensitivity analysis on the parameters of our algorithm and show that it tolerates a wide range of parameter settings. We also show results on tracking human pose from the widely-used Human Eva I dataset. Our results show that the proposed method reduces the tracking error despite using less than 50% of the computational resources as APF. The tracked output also shows a significant qualitative improvement over APF as demonstrated through image and video results.