 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Feed-forward Reconstruction Models as Latent Encoders for 3D Generative Models
Jan 04, 2025



Recent AI-based 3D content creation has largely evolved along two paths: feed-forward image-to-3D reconstruction approaches and 3D generative models trained with 2D or 3D supervision. In this work, we show that existing feed-forward reconstruction methods can serve as effective latent encoders for training 3D generative models, thereby bridging these two paradigms. By reusing powerful pre-trained reconstruction models, we avoid computationally expensive encoder network training and obtain rich 3D latent features for generative modeling for free. However, the latent spaces of reconstruction models are not well-suited for generative modeling due to their unstructured nature. To enable flow-based model training on these latent features, we develop post-processing pipelines, including protocols to standardize the features and spatial weighting to concentrate on important regions. We further incorporate a 2D image space perceptual rendering loss to handle the high-dimensional latent spaces. Finally, we propose a multi-stream transformer-based rectified flow architecture to achieve linear scaling and high-quality text-conditioned 3D generation. Our framework leverages the advancements of feed-forward reconstruction models to enhance the scalability of 3D generative modeling, achieving both high computational efficiency and state-of-the-art performance in text-to-3D generation.
Diffusion Sampling with Momentum for Mitigating Divergence Artifacts
Jul 20, 2023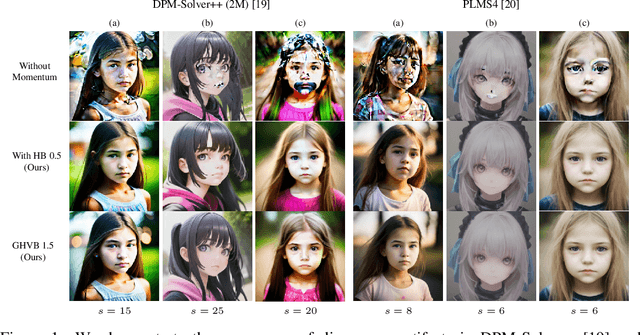
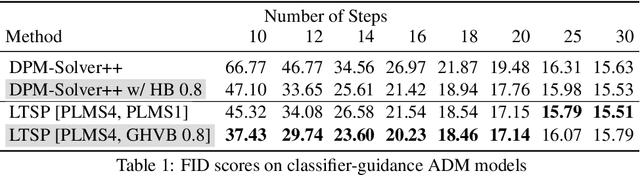
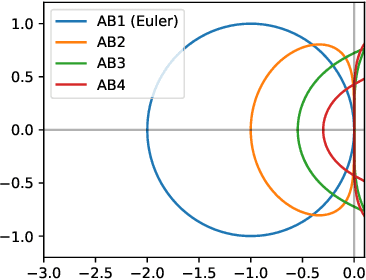
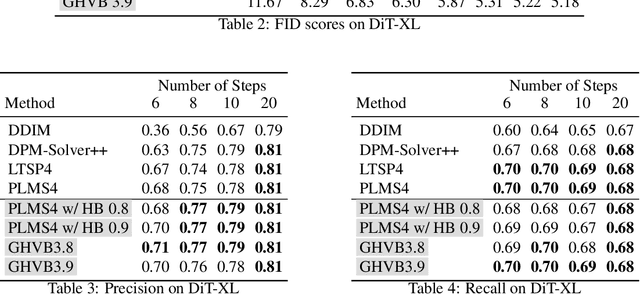
Despite the remarkable success of diffusion models in image generation, slow sampling remains a persistent issue. To accelerate the sampling process, prior studies have reformulated diffusion sampling as an ODE/SDE and introduced higher-order numerical methods. However, these methods often produce divergence artifacts, especially with a low number of sampling steps, which limits the achievable acceleration. In this paper, we investigate the potential causes of these artifacts and suggest that the small stability regions of these methods could be the principal cause. To address this issue, we propose two novel techniques. The first technique involves the incorporation of Heavy Ball (HB) momentum, a well-known technique for improving optimization, into existing diffusion numerical methods to expand their stability regions. We also prove that the resulting methods have first-order convergence. The second technique, called Generalized Heavy Ball (GHVB), constructs a new high-order method that offers a variable trade-off between accuracy and artifact suppression. Experimental results show that our techniques are highly effective in reducing artifacts and improving image quality, surpassing state-of-the-art diffusion solvers on both pixel-based and latent-based diffusion models for low-step sampling. Our research provides novel insights into the design of numerical methods for future diffusion work.
Accelerating Guided Diffusion Sampling with Splitting Numerical Methods
Jan 27, 2023



Guided diffusion is a technique for conditioning the output of a diffusion model at sampling time without retraining the network for each specific task. One drawback of diffusion models, however, is their slow sampling process. Recent techniques can accelerate unguided sampling by applying high-order numerical methods to the sampling process when viewed as differential equations. On the contrary, we discover that the same techniques do not work for guided sampling, and little has been explored about its acceleration. This paper explores the culprit of this problem and provides a solution based on operator splitting methods, motivated by our key finding that classical high-order numerical methods are unsuitable for the conditional function. Our proposed method can re-utilize the high-order methods for guided sampling and can generate images with the same quality as a 250-step DDIM baseline using 32-58% less sampling time on ImageNet256. We also demonstrate usage on a wide variety of conditional generation tasks, such as text-to-image generation, colorization, inpainting, and super-resolution.
Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
Dec 01, 2021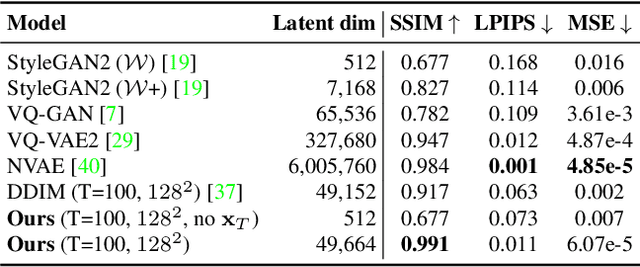
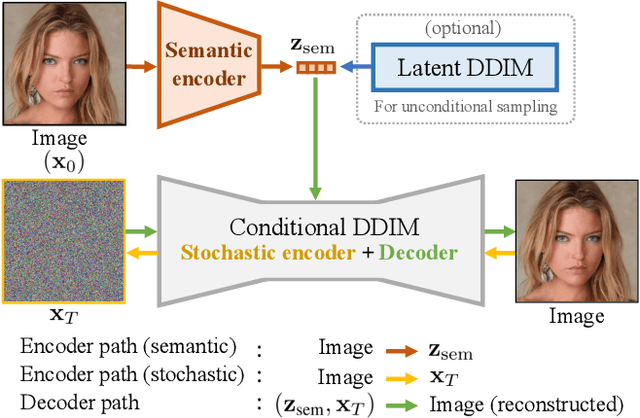
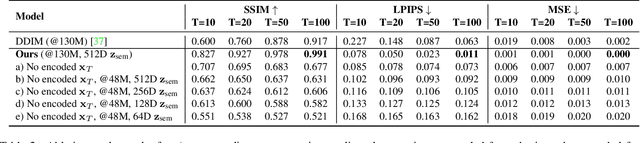

Diffusion probabilistic models (DPMs) have achieved remarkable quality in image generation that rivals GANs'. But unlike GANs, DPMs use a set of latent variables that lack semantic meaning and cannot serve as a useful representation for other tasks. This paper explores the possibility of using DPMs for representation learning and seeks to extract a meaningful and decodable representation of an input image via autoencoding. Our key idea is to use a learnable encoder for discovering the high-level semantics, and a DPM as the decoder for modeling the remaining stochastic variations. Our method can encode any image into a two-part latent code, where the first part is semantically meaningful and linear, and the second part captures stochastic details, allowing near-exact reconstruction. This capability enables challenging applications that currently foil GAN-based methods, such as attribute manipulation on real images. We also show that this two-level encoding improves denoising efficiency and naturally facilitates various downstream tasks including few-shot conditional sampling. Please visit our project page: https://Diff-AE.github.io/
NeX: Real-time View Synthesis with Neural Basis Expansion
Mar 09, 2021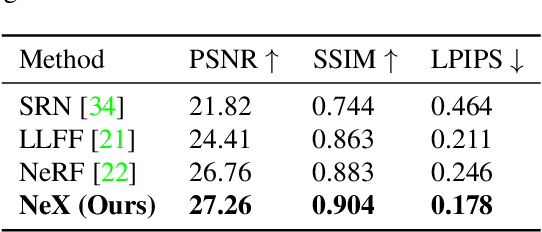
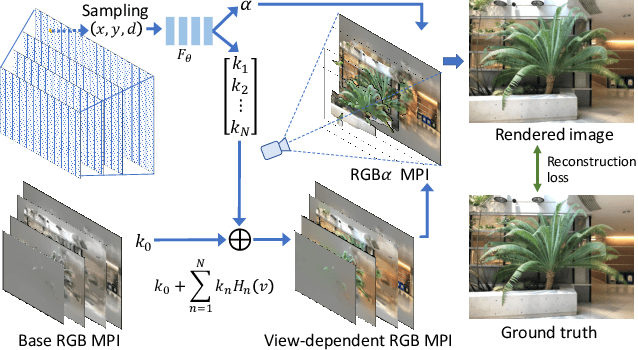


We present NeX, a new approach to novel view synthesis based on enhancements of multiplane image (MPI) that can reproduce next-level view-dependent effects -- in real time. Unlike traditional MPI that uses a set of simple RGB$\alpha$ planes, our technique models view-dependent effects by instead parameterizing each pixel as a linear combination of basis functions learned from a neural network. Moreover, we propose a hybrid implicit-explicit modeling strategy that improves upon fine detail and produces state-of-the-art results. Our method is evaluated on benchmark forward-facing datasets as well as our newly-introduced dataset designed to test the limit of view-dependent modeling with significantly more challenging effects such as rainbow reflections on a CD. Our method achieves the best overall scores across all major metrics on these datasets with more than 1000$\times$ faster rendering time than the state of the art. For real-time demos, visit https://nex-mpi.github.io/