 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecom-Renorm-Merge: Model Merging on the Right Space Improves Multitasking
May 29, 2025In the era of large-scale training, model merging has evolved into a tool for creating multitasking models efficiently. It enables the knowledge of models to be fused, without the need for heavy computation as required in traditional multitask learning. Existing merging methods often assume that entries at identical positions in weight matrices serve the same function, enabling straightforward entry-wise comparison and merging. However, this assumption overlooks the complexity of finetuned neural networks, where neurons may develop distinct feature compositions, making direct entry-wise merging problematic. We present Decom-Renorm-Merge (DRM), a simple yet effective approach that leverages Singular Value Decomposition to decompose and coordinate weight matrices into an aligned joint space, where entry-wise merging becomes possible. We showcase the effectiveness of DRM across various settings ranging from smaller encoder-based such as ViT and DeBERTa, encoder-decoder-based such as T5, and larger decoder-based such as Llama3.1-8B. Our experimental results show that DRM outperforms several state-of-the-art merging techniques across full finetuning and low-rank adaptation settings. Moreover, our analysis reveals renormalization as the crucial component for creating a robust and even joint space for merging, significantly contributing to the method's performance.
Visual Jenga: Discovering Object Dependencies via Counterfactual Inpainting
Mar 27, 2025This paper proposes a novel scene understanding task called Visual Jenga. Drawing inspiration from the game Jenga, the proposed task involves progressively removing objects from a single image until only the background remains. Just as Jenga players must understand structural dependencies to maintain tower stability, our task reveals the intrinsic relationships between scene elements by systematically exploring which objects can be removed while preserving scene coherence in both physical and geometric sense. As a starting point for tackling the Visual Jenga task, we propose a simple, data-driven, training-free approach that is surprisingly effective on a range of real-world images. The principle behind our approach is to utilize the asymmetry in the pairwise relationships between objects within a scene and employ a large inpainting model to generate a set of counterfactuals to quantify the asymmetry.
Optimizing Diffusion Noise Can Serve As Universal Motion Priors
Dec 19, 2023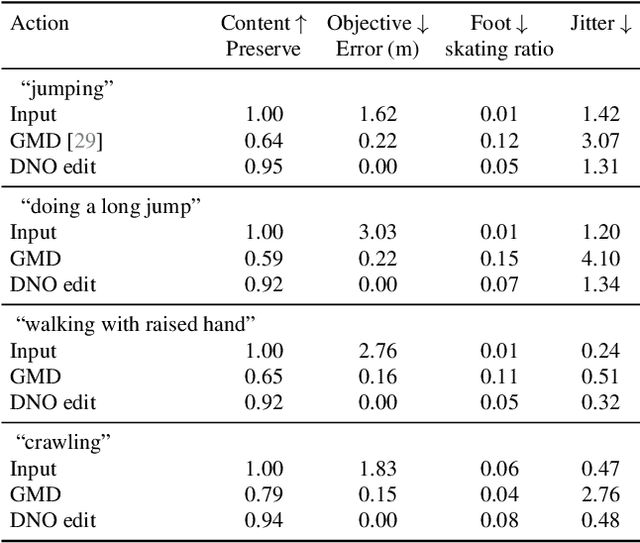
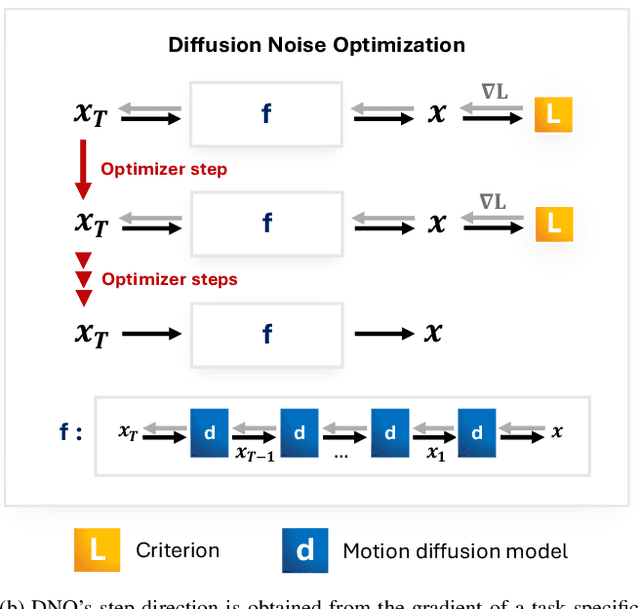
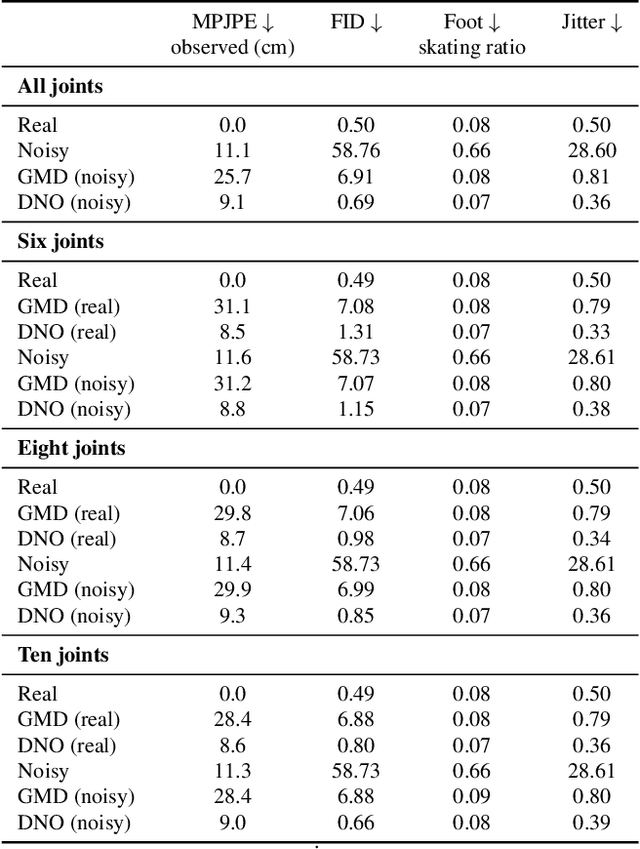

We propose Diffusion Noise Optimization (DNO), a new method that effectively leverages existing motion diffusion models as motion priors for a wide range of motion-related tasks. Instead of training a task-specific diffusion model for each new task, DNO operates by optimizing the diffusion latent noise of an existing pre-trained text-to-motion model. Given the corresponding latent noise of a human motion, it propagates the gradient from the target criteria defined on the motion space through the whole denoising process to update the diffusion latent noise. As a result, DNO supports any use cases where criteria can be defined as a function of motion. In particular, we show that, for motion editing and control, DNO outperforms existing methods in both achieving the objective and preserving the motion content. DNO accommodates a diverse range of editing modes, including changing trajectory, pose, joint locations, or avoiding newly added obstacles. In addition, DNO is effective in motion denoising and completion, producing smooth and realistic motion from noisy and partial inputs. DNO achieves these results at inference time without the need for model retraining, offering great versatility for any defined reward or loss function on the motion representation.
GMD: Controllable Human Motion Synthesis via Guided Diffusion Models
May 21, 2023



Denoising diffusion models have shown great promise in human motion synthesis conditioned on natural language descriptions. However, it remains a challenge to integrate spatial constraints, such as pre-defined motion trajectories and obstacles, which is essential for bridging the gap between isolated human motion and its surrounding environment. To address this issue, we propose Guided Motion Diffusion (GMD), a method that incorporates spatial constraints into the motion generation process. Specifically, we propose an effective feature projection scheme that largely enhances the coherency between spatial information and local poses. Together with a new imputation formulation, the generated motion can reliably conform to spatial constraints such as global motion trajectories. Furthermore, given sparse spatial constraints (e.g. sparse keyframes), we introduce a new dense guidance approach that utilizes the denoiser of diffusion models to turn a sparse signal into denser signals, effectively guiding the generation motion to the given constraints. The extensive experiments justify the development of GMD, which achieves a significant improvement over state-of-the-art methods in text-based motion generation while being able to control the synthesized motions with spatial constraints.
Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
Dec 01, 2021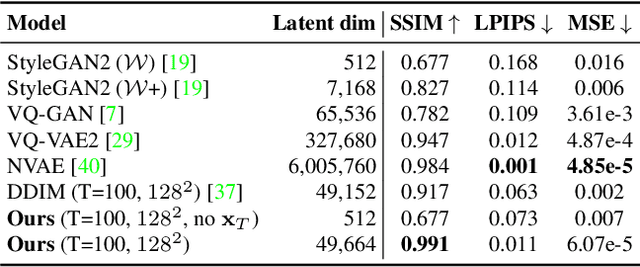
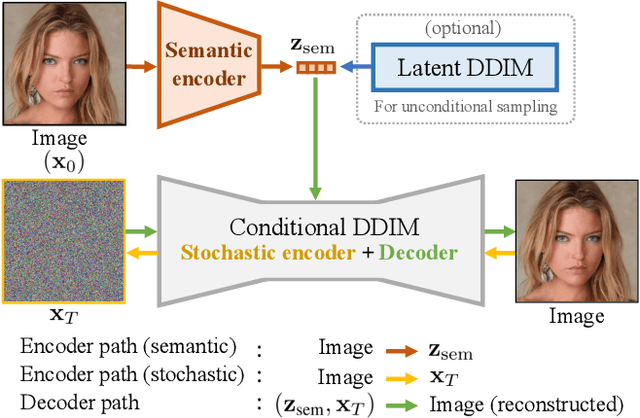
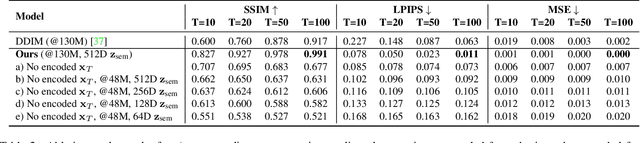

Diffusion probabilistic models (DPMs) have achieved remarkable quality in image generation that rivals GANs'. But unlike GANs, DPMs use a set of latent variables that lack semantic meaning and cannot serve as a useful representation for other tasks. This paper explores the possibility of using DPMs for representation learning and seeks to extract a meaningful and decodable representation of an input image via autoencoding. Our key idea is to use a learnable encoder for discovering the high-level semantics, and a DPM as the decoder for modeling the remaining stochastic variations. Our method can encode any image into a two-part latent code, where the first part is semantically meaningful and linear, and the second part captures stochastic details, allowing near-exact reconstruction. This capability enables challenging applications that currently foil GAN-based methods, such as attribute manipulation on real images. We also show that this two-level encoding improves denoising efficiency and naturally facilitates various downstream tasks including few-shot conditional sampling. Please visit our project page: https://Diff-AE.github.io/
High resolution weakly supervised localization architectures for medical images
Oct 22, 2020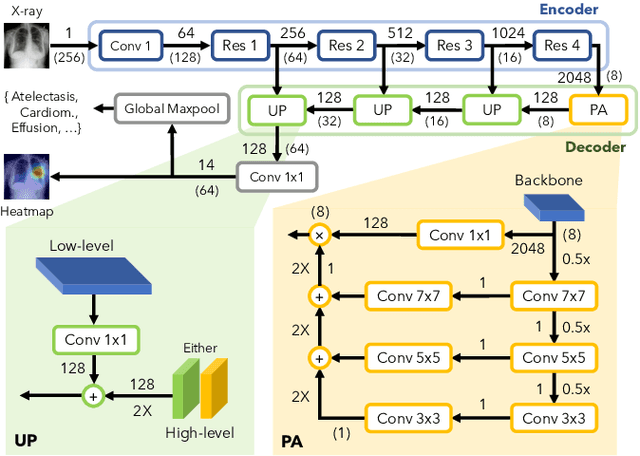

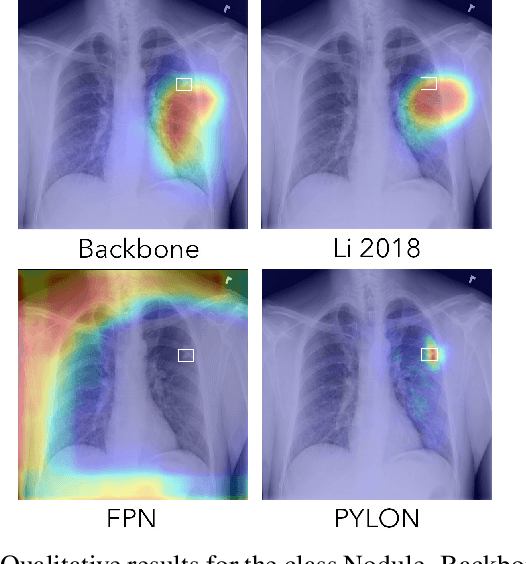
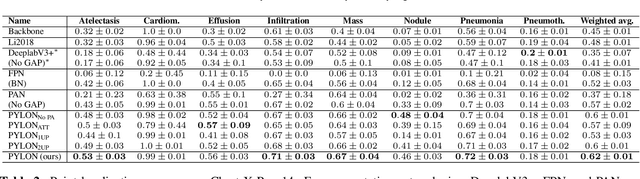
In medical imaging, Class-Activation Map (CAM) serves as the main explainability tool by pointing to the region of interest. Since the localization accuracy from CAM is constrained by the resolution of the model's feature map, one may expect that segmentation models, which generally have large feature maps, would produce more accurate CAMs. However, we have found that this is not the case due to task mismatch. While segmentation models are developed for datasets with pixel-level annotation, only image-level annotation is available in most medical imaging datasets. Our experiments suggest that Global Average Pooling (GAP) and Group Normalization are the main culprits that worsen the localization accuracy of CAM. To address this issue, we propose Pyramid Localization Network (PYLON), a model for high-accuracy weakly-supervised localization that achieved 0.62 average point localization accuracy on NIH's Chest X-Ray 14 dataset, compared to 0.45 for a traditional CAM model. Source code and extended results are available at https://github.com/cmb-chula/pylon.
CProp: Adaptive Learning Rate Scaling from Past Gradient Conformity
Dec 24, 2019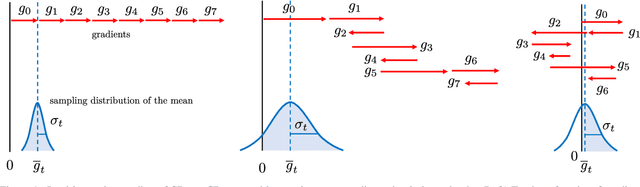
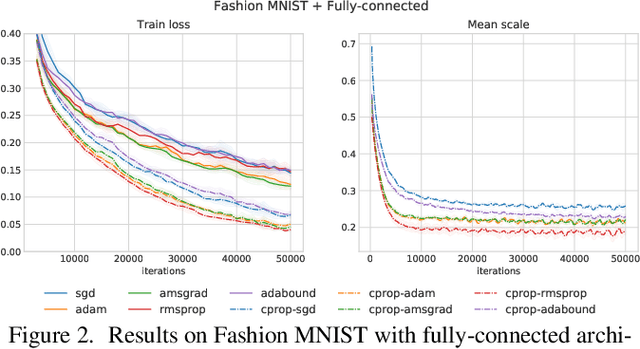

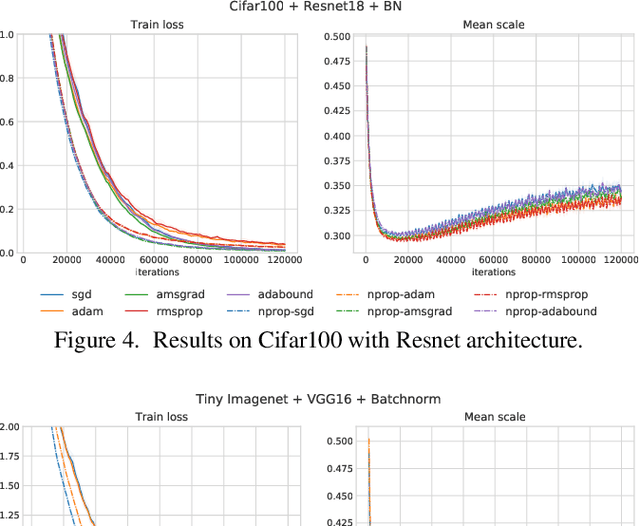
Most optimizers including stochastic gradient descent (SGD) and its adaptive gradient derivatives face the same problem where an effective learning rate during the training is vastly different. A learning rate scheduling, mostly tuned by hand, is usually employed in practice. In this paper, we propose CProp, a gradient scaling method, which acts as a second-level learning rate adapting throughout the training process based on cues from past gradient conformity. When the past gradients agree on direction, CProp keeps the original learning rate. On the contrary, if the gradients do not agree on direction, CProp scales down the gradient proportionally to its uncertainty. Since it works by scaling, it could apply to any existing optimizer extending its learning rate scheduling capability. We put CProp to a series of tests showing significant gain in training speed on both SGD and adaptive gradient method like Adam. Codes are available at https://github.com/phizaz/cprop .