 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh resolution weakly supervised localization architectures for medical images
Oct 22, 2020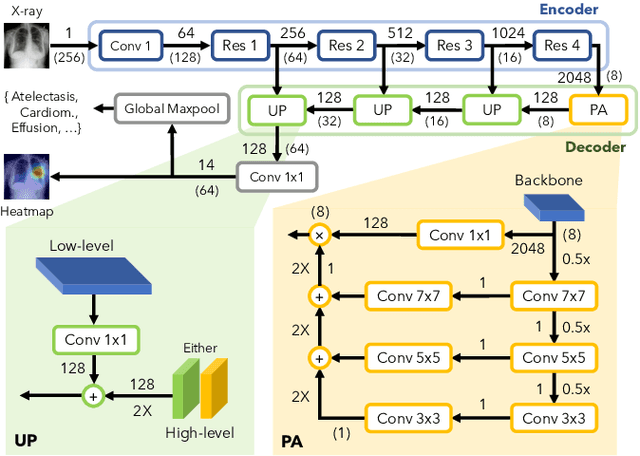

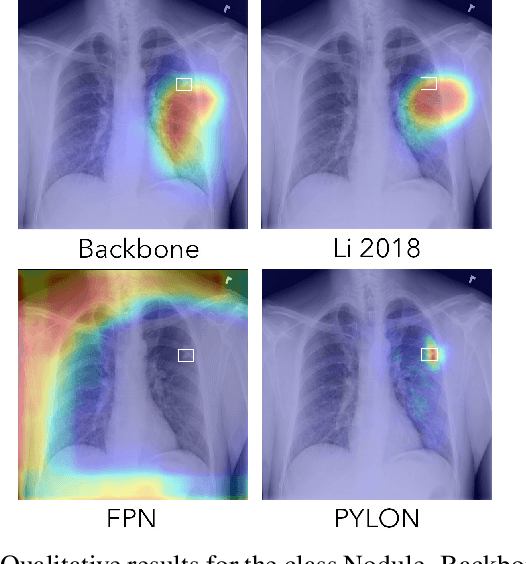
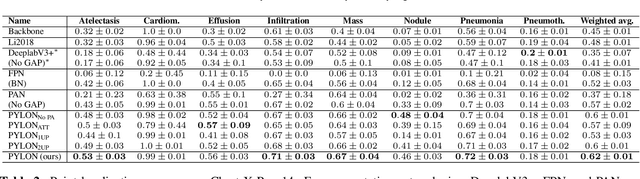
In medical imaging, Class-Activation Map (CAM) serves as the main explainability tool by pointing to the region of interest. Since the localization accuracy from CAM is constrained by the resolution of the model's feature map, one may expect that segmentation models, which generally have large feature maps, would produce more accurate CAMs. However, we have found that this is not the case due to task mismatch. While segmentation models are developed for datasets with pixel-level annotation, only image-level annotation is available in most medical imaging datasets. Our experiments suggest that Global Average Pooling (GAP) and Group Normalization are the main culprits that worsen the localization accuracy of CAM. To address this issue, we propose Pyramid Localization Network (PYLON), a model for high-accuracy weakly-supervised localization that achieved 0.62 average point localization accuracy on NIH's Chest X-Ray 14 dataset, compared to 0.45 for a traditional CAM model. Source code and extended results are available at https://github.com/cmb-chula/pylon.
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Apr 13, 2020
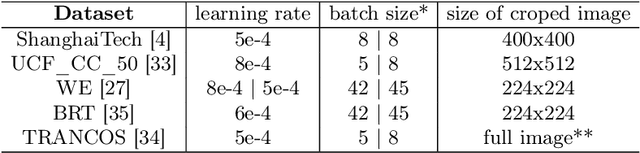
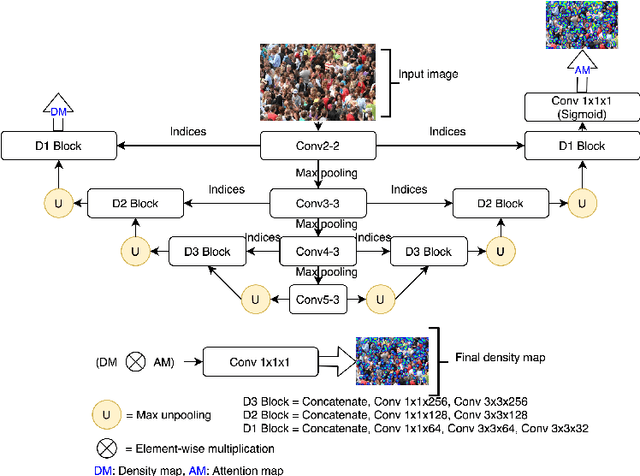
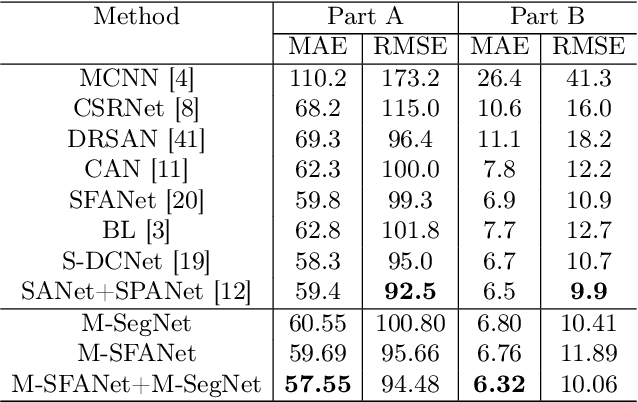
In this paper, we proposed two modified neural network architectures based on SFANet and SegNet respectively for accurate and efficient crowd counting. Inspired by SFANet, the first model is attached with two novel multi-scale-aware modules, called ASSP and CAN. This model is named M-SFANet. The encoder of M-SFANet is enhanced with ASSP containing parallel atrous convolutional layers with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage contextual module called CAN which adaptively encodes the scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on SFANet decoder structure, M-SFANet's decoder has dual paths, for density map generation and attention map generation. The second model is called M-SegNet, which is produced by replacing the bilinear upsampling in SFANet with max unpooling that is used in SegNet. This change provides the faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and are end-to-end trainable. We also conduct extensive experiments on five crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could outperform some of state-of-the-art crowd counting methods. Codes are available at https://github.com/Pongpisit-Thanasutives/Variations-of-SFANet-for-Crowd-Counting.
CProp: Adaptive Learning Rate Scaling from Past Gradient Conformity
Dec 24, 2019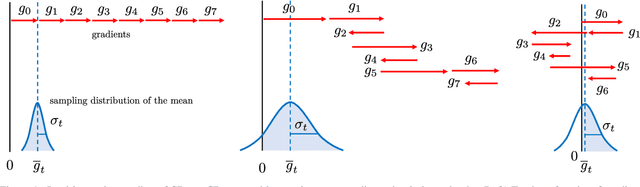
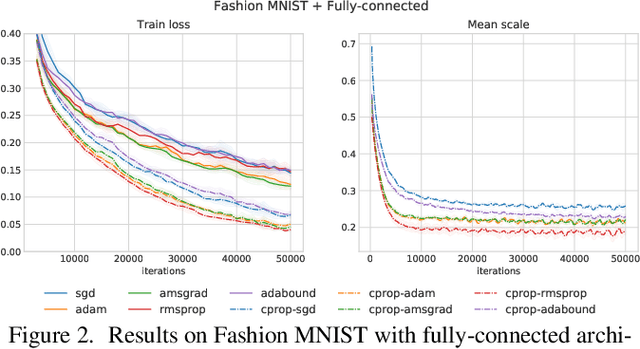

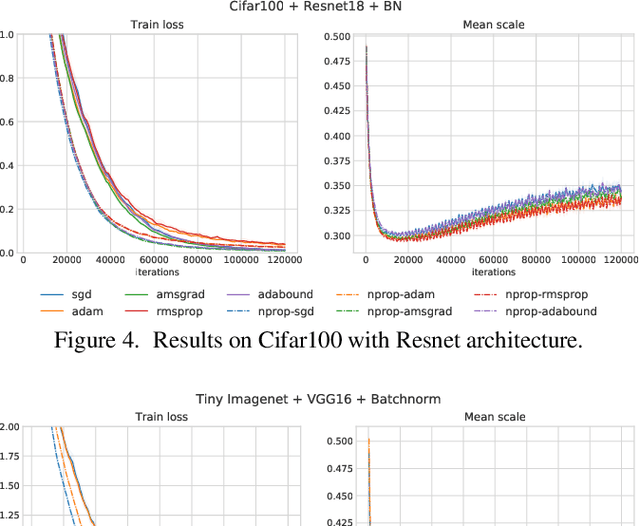
Most optimizers including stochastic gradient descent (SGD) and its adaptive gradient derivatives face the same problem where an effective learning rate during the training is vastly different. A learning rate scheduling, mostly tuned by hand, is usually employed in practice. In this paper, we propose CProp, a gradient scaling method, which acts as a second-level learning rate adapting throughout the training process based on cues from past gradient conformity. When the past gradients agree on direction, CProp keeps the original learning rate. On the contrary, if the gradients do not agree on direction, CProp scales down the gradient proportionally to its uncertainty. Since it works by scaling, it could apply to any existing optimizer extending its learning rate scheduling capability. We put CProp to a series of tests showing significant gain in training speed on both SGD and adaptive gradient method like Adam. Codes are available at https://github.com/phizaz/cprop .
A Comparative Study of Pretrained Language Models on Thai Social Text Categorization
Dec 17, 2019


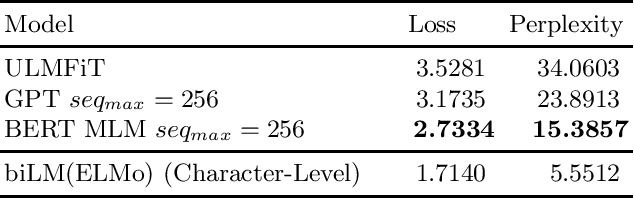
The ever-growing volume of data of user-generated content on social media provides a nearly unlimited corpus of unlabeled data even in languages where resources are scarce. In this paper, we demonstrate that state-of-the-art results on two Thai social text categorization tasks can be realized by pretraining a language model on a large noisy Thai social media corpus of over 1.26 billion tokens and later fine-tuned on the downstream classification tasks. Due to the linguistically noisy and domain-specific nature of the content, our unique data preprocessing steps designed for Thai social media were utilized to ease the training comprehension of the model. We compared four modern language models: ULMFiT, ELMo with biLSTM, OpenAI GPT, and BERT. We systematically compared the models across different dimensions including speed of pretraining and fine-tuning, perplexity, downstream classification benchmarks, and performance in limited pretraining data.
Spatiotemporal Emotion Recognition using Deep CNN Based on EEG during Music Listening
Oct 22, 2019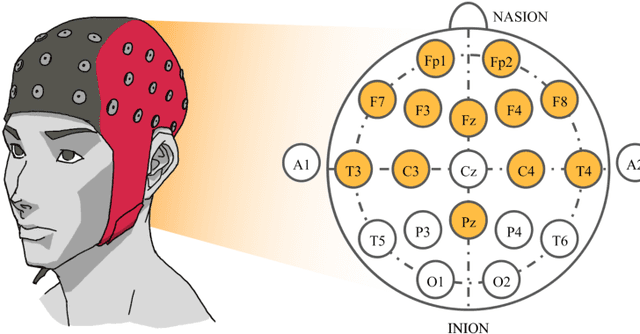
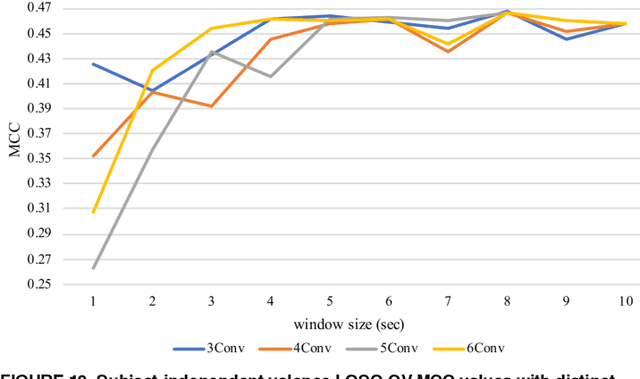
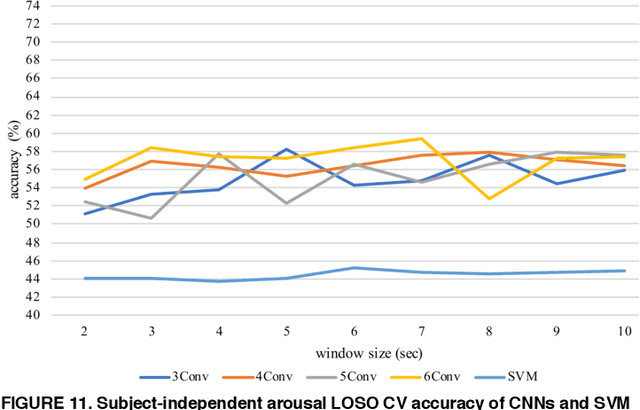
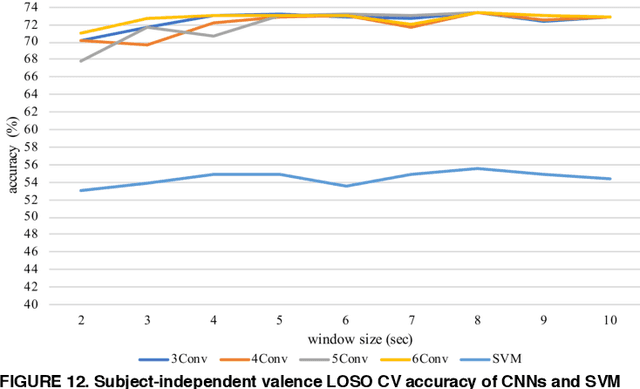
Emotion recognition based on EEG has become an active research area. As one of the machine learning models, CNN has been utilized to solve diverse problems including issues in this domain. In this work, a study of CNN and its spatiotemporal feature extraction has been conducted in order to explore capabilities of the model in varied window sizes and electrode orders. Our investigation was conducted in subject-independent fashion. Results have shown that temporal information in distinct window sizes significantly affects recognition performance in both 10-fold and leave-one-subject-out cross validation. Spatial information from varying electrode order has modicum effect on classification. SVM classifier depending on spatiotemporal knowledge on the same dataset was previously employed and compared to these empirical results. Even though CNN and SVM have a homologous trend in window size effect, CNN outperformed SVM using leave-one-subject-out cross validation. This could be caused by different extracted features in the elicitation process.
Efficient Decision Trees for Multi-class Support Vector Machines Using Entropy and Generalization Error Estimation
Aug 28, 2017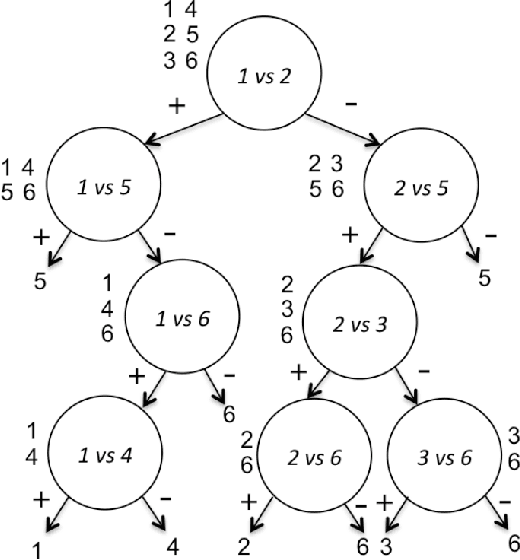
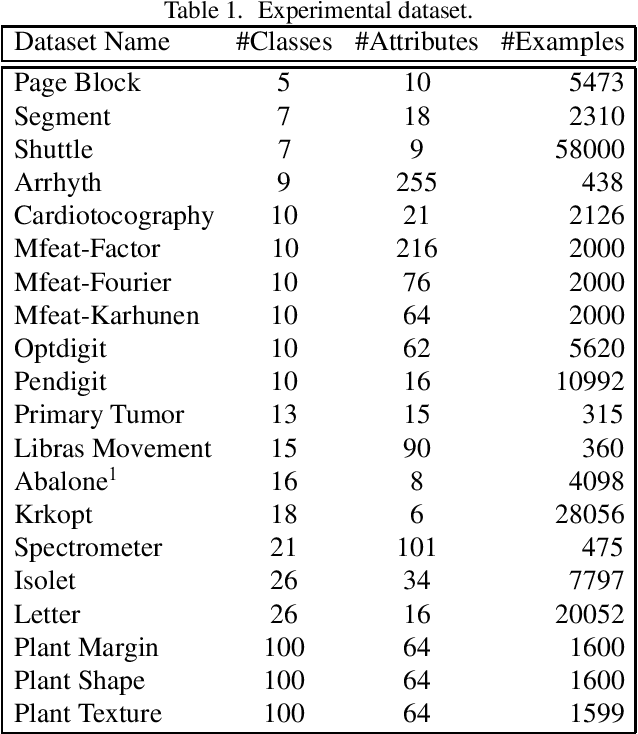
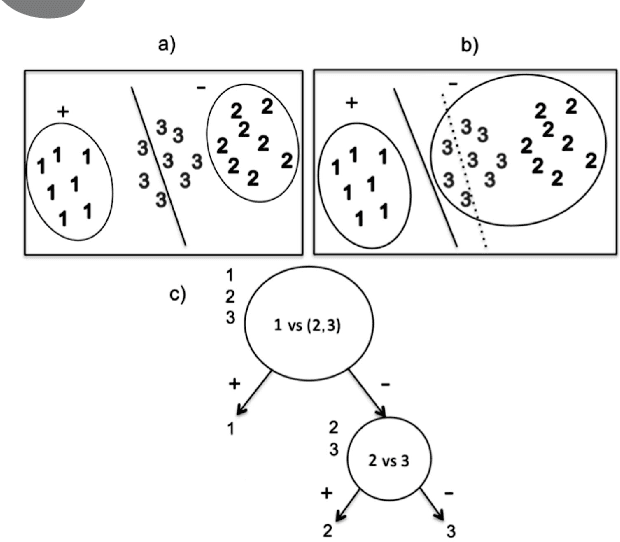
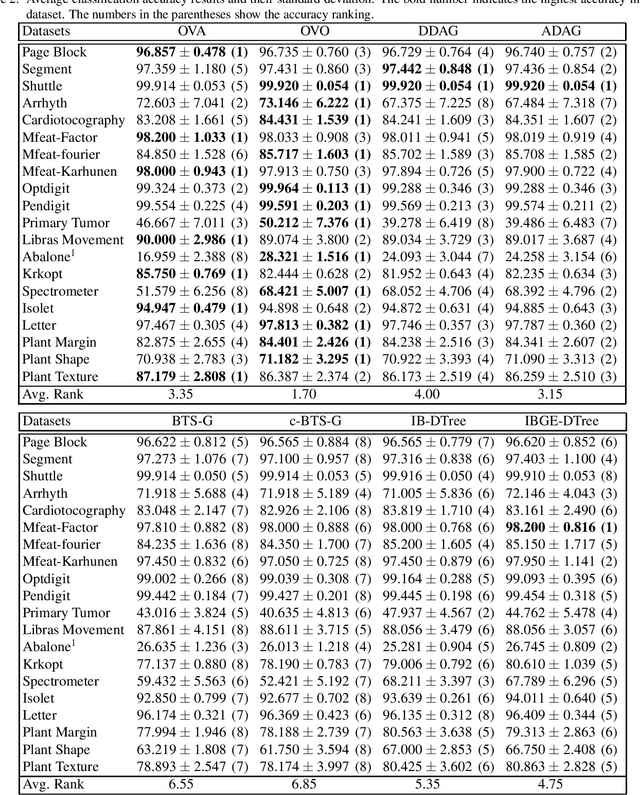
We propose new methods for Support Vector Machines (SVMs) using tree architecture for multi-class classi- fication. In each node of the tree, we select an appropriate binary classifier using entropy and generalization error estimation, then group the examples into positive and negative classes based on the selected classi- fier and train a new classifier for use in the classification phase. The proposed methods can work in time complexity between O(log2N) to O(N) where N is the number of classes. We compared the performance of our proposed methods to the traditional techniques on the UCI machine learning repository using 10-fold cross-validation. The experimental results show that our proposed methods are very useful for the problems that need fast classification time or problems with a large number of classes as the proposed methods run much faster than the traditional techniques but still provide comparable accuracy.
Sub-Classifier Construction for Error Correcting Output Code Using Minimum Weight Perfect Matching
Dec 27, 2013
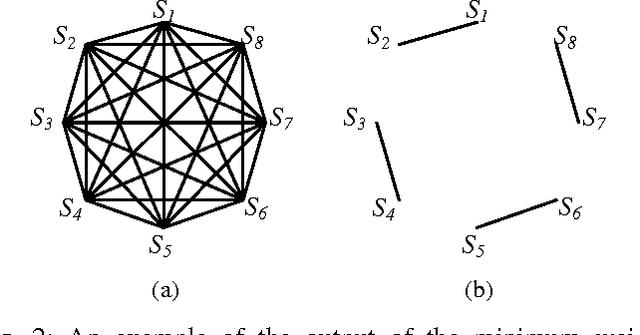
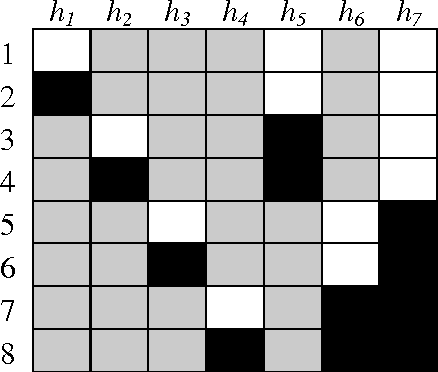
Multi-class classification is mandatory for real world problems and one of promising techniques for multi-class classification is Error Correcting Output Code. We propose a method for constructing the Error Correcting Output Code to obtain the suitable combination of positive and negative classes encoded to represent binary classifiers. The minimum weight perfect matching algorithm is applied to find the optimal pairs of subset of classes by using the generalization performance as a weighting criterion. Based on our method, each subset of classes with positive and negative labels is appropriately combined for learning the binary classifiers. Experimental results show that our technique gives significantly higher performance compared to traditional methods including the dense random code and the sparse random code both in terms of accuracy and classification times. Moreover, our method requires significantly smaller number of binary classifiers while maintaining accuracy compared to the One-Versus-One.
Enhancements of Multi-class Support Vector Machine Construction from Binary Learners using Generalization Performance
Sep 11, 2013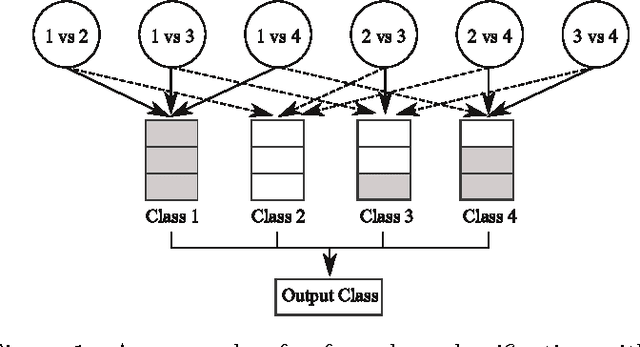
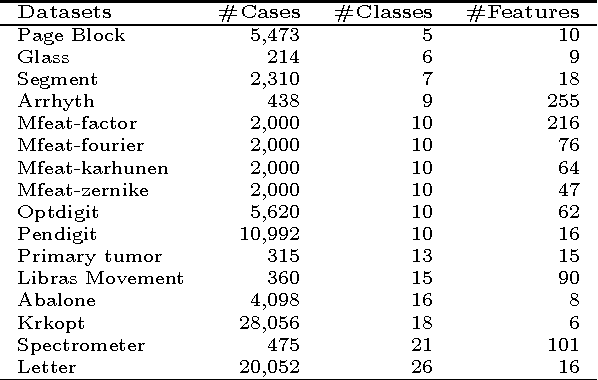
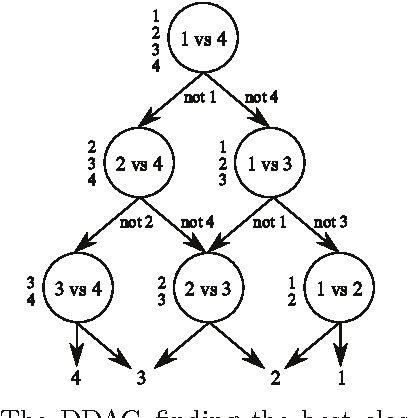
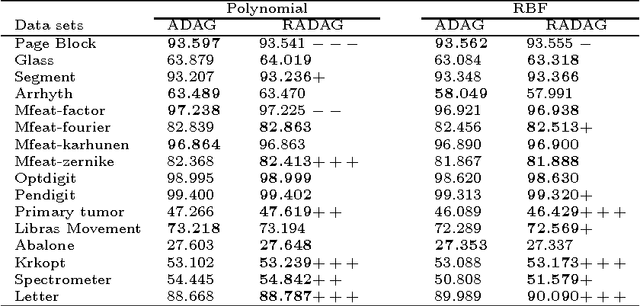
We propose several novel methods for enhancing the multi-class SVMs by applying the generalization performance of binary classifiers as the core idea. This concept will be applied on the existing algorithms, i.e., the Decision Directed Acyclic Graph (DDAG), the Adaptive Directed Acyclic Graphs (ADAG), and Max Wins. Although in the previous approaches there have been many attempts to use some information such as the margin size and the number of support vectors as performance estimators for binary SVMs, they may not accurately reflect the actual performance of the binary SVMs. We show that the generalization ability evaluated via a cross-validation mechanism is more suitable to directly extract the actual performance of binary SVMs. Our methods are built around this performance measure, and each of them is crafted to overcome the weakness of the previous algorithm. The proposed methods include the Reordering Adaptive Directed Acyclic Graph (RADAG), Strong Elimination of the classifiers (SE), Weak Elimination of the classifiers (WE), and Voting based Candidate Filtering (VCF). Experimental results demonstrate that our methods give significantly higher accuracy than all of the traditional ones. Especially, WE provides significantly superior results compared to Max Wins which is recognized as the state of the art algorithm in terms of both accuracy and classification speed with two times faster in average.
Robust Principal Component Analysis Using Statistical Estimators
Jul 02, 2012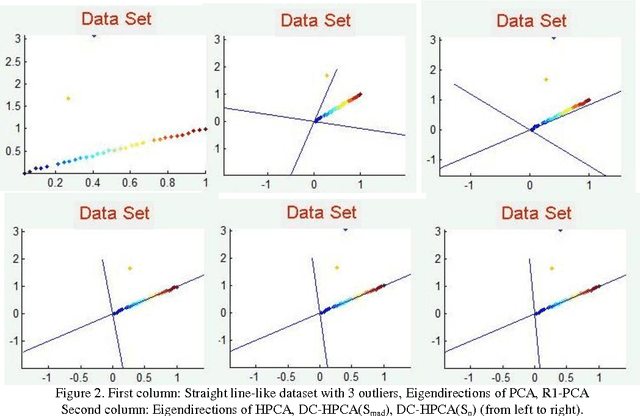
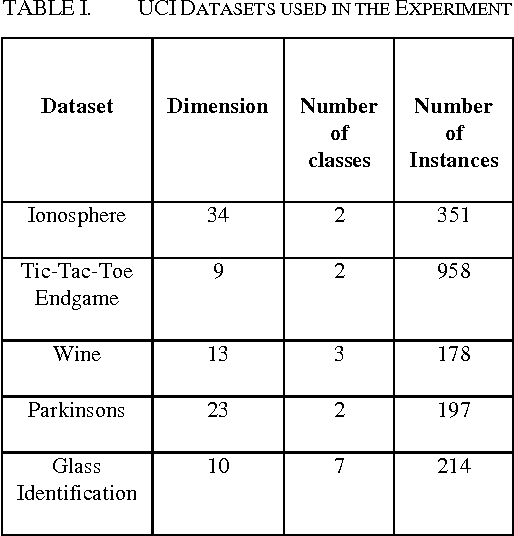
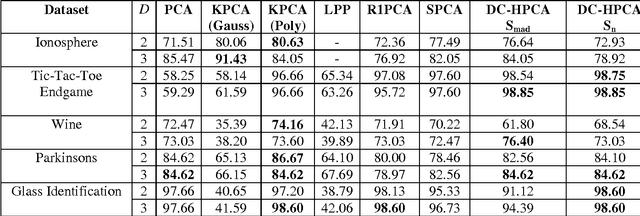
Principal Component Analysis (PCA) finds a linear mapping and maximizes the variance of the data which makes PCA sensitive to outliers and may cause wrong eigendirection. In this paper, we propose techniques to solve this problem; we use the data-centering method and reestimate the covariance matrix using robust statistic techniques such as median, robust scaling which is a booster to data-centering and Huber M-estimator which measures the presentation of outliers and reweight them with small values. The results on several real world data sets show that our proposed method handles outliers and gains better results than the original PCA and provides the same accuracy with lower computation cost than the Kernel PCA using the polynomial kernel in classification tasks.
Applying Deep Belief Networks to Word Sense Disambiguation
Jul 02, 2012
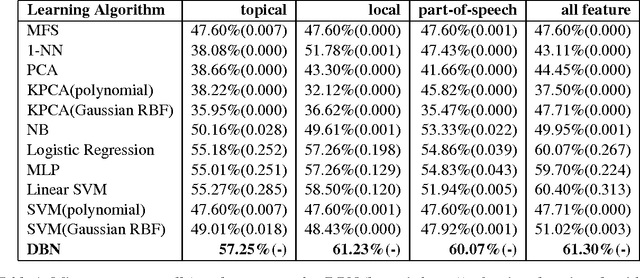
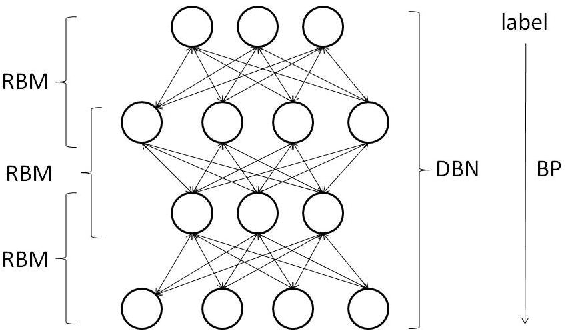
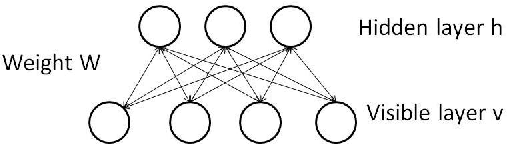
In this paper, we applied a novel learning algorithm, namely, Deep Belief Networks (DBN) to word sense disambiguation (WSD). DBN is a probabilistic generative model composed of multiple layers of hidden units. DBN uses Restricted Boltzmann Machine (RBM) to greedily train layer by layer as a pretraining. Then, a separate fine tuning step is employed to improve the discriminative power. We compared DBN with various state-of-the-art supervised learning algorithms in WSD such as Support Vector Machine (SVM), Maximum Entropy model (MaxEnt), Naive Bayes classifier (NB) and Kernel Principal Component Analysis (KPCA). We used all words in the given paragraph, surrounding context words and part-of-speech of surrounding words as our knowledge sources. We conducted our experiment on the SENSEVAL-2 data set. We observed that DBN outperformed all other learning algorithms.