 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixtures of Unsupervised Lexicon Classification
May 27, 2024This paper presents a mixture version of the method-of-moment unsupervised lexicon classification by an incorporation of a Dirichlet process.
ClassBases at CASE-2022 Multilingual Protest Event Detection Tasks: Multilingual Protest News Detection and Automatically Replicating Manually Created Event Datasets
Jan 16, 2023



In this report, we describe our ClassBases submissions to a shared task on multilingual protest event detection. For the multilingual protest news detection, we participated in subtask-1, subtask-2, and subtask-4, which are document classification, sentence classification, and token classification. In subtask-1, we compare XLM-RoBERTa-base, mLUKE-base, and XLM-RoBERTa-large on finetuning in a sequential classification setting. We always use a combination of the training data from every language provided to train our multilingual models. We found that larger models seem to work better and entity knowledge helps but at a non-negligible cost. For subtask-2, we only submitted an mLUKE-base system for sentence classification. For subtask-4, we only submitted an XLM-RoBERTa-base for token classification system for sequence labeling. For automatically replicating manually created event datasets, we participated in COVID-related protest events from the New York Times news corpus. We created a system to process the crawled data into a dataset of protest events.
PromptShots at the FinNLP-2022 ERAI Tasks: Pairwise Comparison and Unsupervised Ranking
Jan 16, 2023



This report describes our PromptShots submissions to a shared task on Evaluating the Rationales of Amateur Investors (ERAI). We participated in both pairwise comparison and unsupervised ranking tasks. For pairwise comparison, we employed instruction-based models based on T5-small and OpenAI InstructGPT language models. Surprisingly, we observed OpenAI InstructGPT language model few-shot trained on Chinese data works best in our submissions, ranking 3rd on the maximal loss (ML) pairwise accuracy. This model works better than training on the Google translated English data by a large margin, where the English few-shot trained InstructGPT model even performs worse than an instruction-based T5-small model finetuned on the English data. However, all instruction-based submissions do not perform well on the maximal potential profit (MPP) pairwise accuracy where there are more data and learning signals. The Chinese few-shot trained InstructGPT model still performs best in our setting. For unsupervised ranking, we utilized many language models, including many financial-specific ones, and Bayesian lexicons unsupervised-learned on both Chinese and English words using a method-of-moments estimator. All our submissions rank best in the MPP ranking, from 1st to 3rd. However, they all do not perform well for ML scoring. Therefore, both MPP and ML scores need different treatments since we treated MPP and ML using the same formula. Our only difference is the treatment of market sentiment lexicons.
TEDB System Description to a Shared Task on Euphemism Detection 2022
Jan 16, 2023



In this report, we describe our Transformers for euphemism detection baseline (TEDB) submissions to a shared task on euphemism detection 2022. We cast the task of predicting euphemism as text classification. We considered Transformer-based models which are the current state-of-the-art methods for text classification. We explored different training schemes, pretrained models, and model architectures. Our best result of 0.816 F1-score (0.818 precision and 0.814 recall) consists of a euphemism-detection-finetuned TweetEval/TimeLMs-pretrained RoBERTa model as a feature extractor frontend with a KimCNN classifier backend trained end-to-end using a cosine annealing scheduler. We observed pretrained models on sentiment analysis and offensiveness detection to correlate with more F1-score while pretraining on other tasks, such as sarcasm detection, produces less F1-scores. Also, putting more word vector channels does not improve the performance in our experiments.
Is Sluice Resolution really just Question Answering?
May 29, 2021

Sluice resolution is a problem where a system needs to output the corresponding antecedents of wh-ellipses. The antecedents are elided contents behind the wh-words but are implicitly referred to using contexts. Previous work frames sluice resolution as question answering where this setting outperforms all its preceding works by large margins. Ellipsis and questions are referentially dependent expressions (anaphoras) and retrieving the corresponding antecedents are like answering questions to output pieces of clarifying information. However, the task is not fully solved. Therefore, we want to further investigate what makes sluice resolution differ to question answering and fill in the error gaps. We also present some results using recent state-of-the-art question answering systems which improve the previous work (86.01 to 90.39 F1).
SpotFast Networks with Memory Augmented Lateral Transformers for Lipreading
May 21, 2020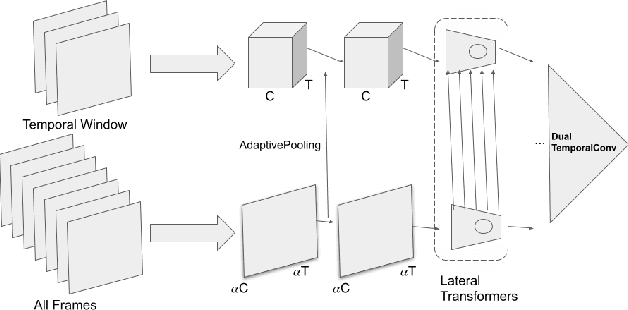

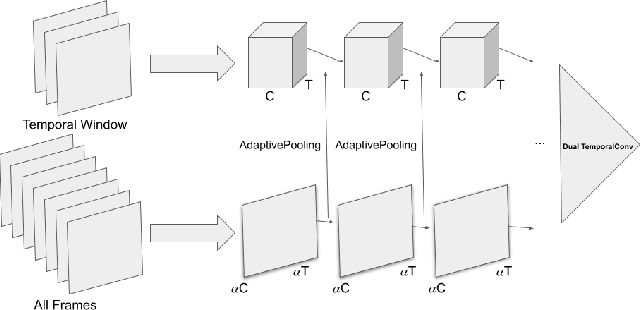
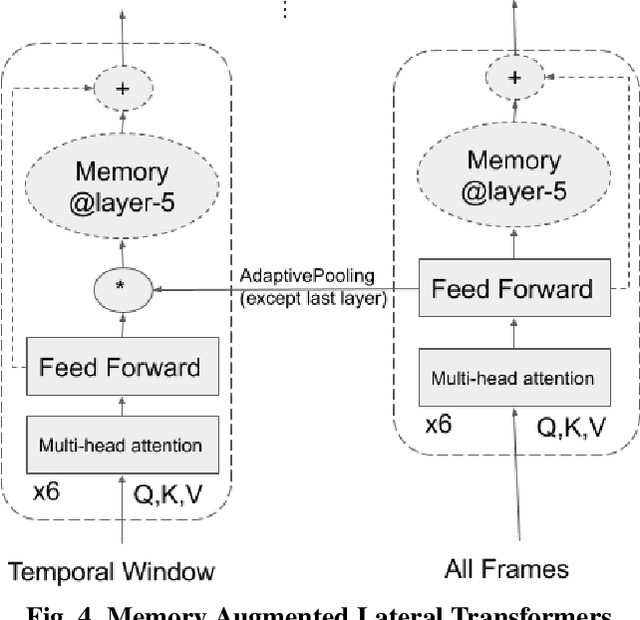
This paper presents a novel deep learning architecture for word-level lipreading. Previous works suggest a potential for incorporating a pretrained deep 3D Convolutional Neural Networks as a front-end feature extractor. We introduce a SpotFast networks, a variant of the state-of-the-art SlowFast networks for action recognition, which utilizes a temporal window as a spot pathway and all frames as a fast pathway. We further incorporate memory augmented lateral transformers to learn sequential features for classification. We evaluate the proposed model on the LRW dataset. The experiments show that our proposed model outperforms various state-of-the-art models and incorporating the memory augmented lateral transformers makes a 3.7% improvement to the SpotFast networks.
Referring to Objects in Videos using Spatio-Temporal Identifying Descriptions
Apr 08, 2019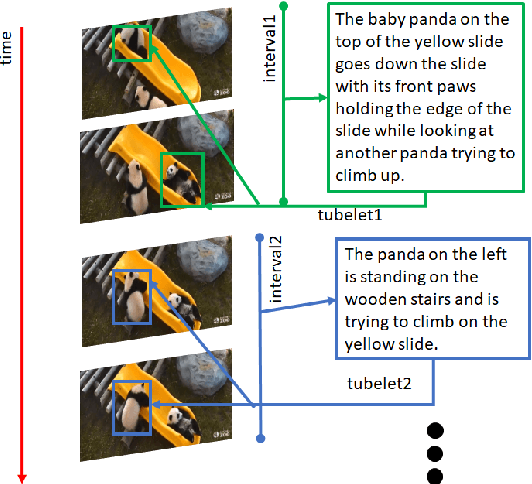

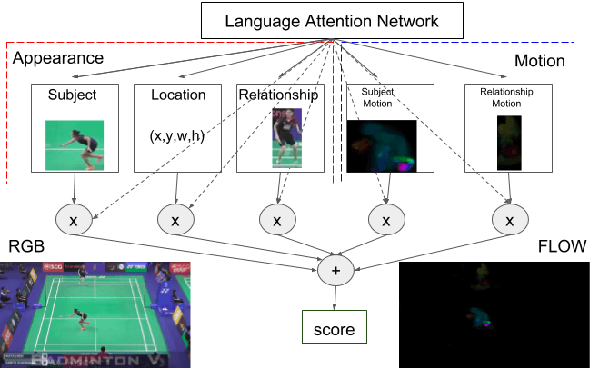

This paper presents a new task, the grounding of spatio-temporal identifying descriptions in videos. Previous work suggests potential bias in existing datasets and emphasizes the need for a new data creation schema to better model linguistic structure. We introduce a new data collection scheme based on grammatical constraints for surface realization to enable us to investigate the problem of grounding spatio-temporal identifying descriptions in videos. We then propose a two-stream modular attention network that learns and grounds spatio-temporal identifying descriptions based on appearance and motion. We show that motion modules help to ground motion-related words and also help to learn in appearance modules because modular neural networks resolve task interference between modules. Finally, we propose a future challenge and a need for a robust system arising from replacing ground truth visual annotations with automatic video object detector and temporal event localization.
Robust Principal Component Analysis Using Statistical Estimators
Jul 02, 2012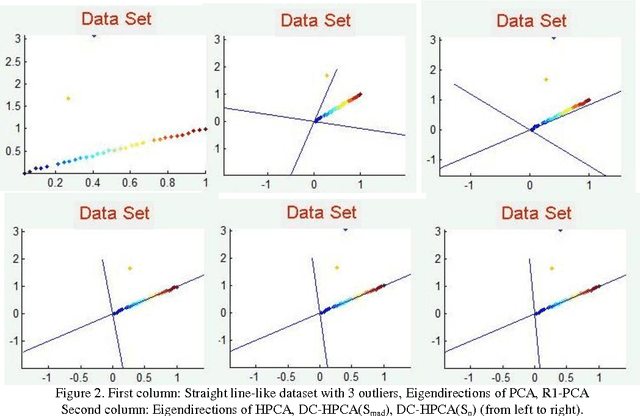
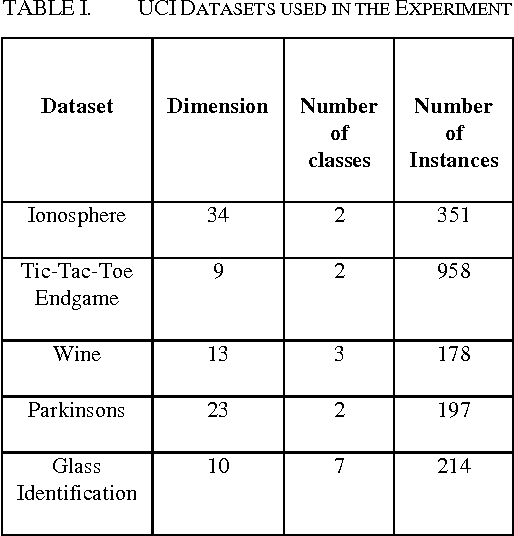
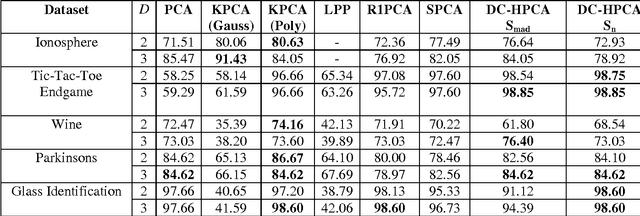
Principal Component Analysis (PCA) finds a linear mapping and maximizes the variance of the data which makes PCA sensitive to outliers and may cause wrong eigendirection. In this paper, we propose techniques to solve this problem; we use the data-centering method and reestimate the covariance matrix using robust statistic techniques such as median, robust scaling which is a booster to data-centering and Huber M-estimator which measures the presentation of outliers and reweight them with small values. The results on several real world data sets show that our proposed method handles outliers and gains better results than the original PCA and provides the same accuracy with lower computation cost than the Kernel PCA using the polynomial kernel in classification tasks.
Applying Deep Belief Networks to Word Sense Disambiguation
Jul 02, 2012
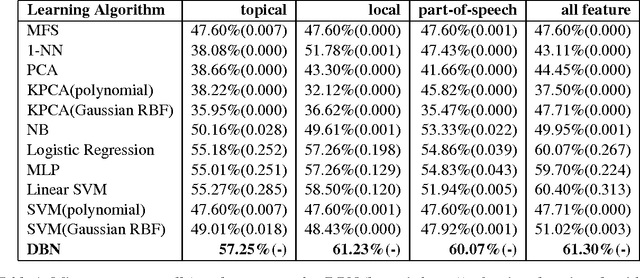
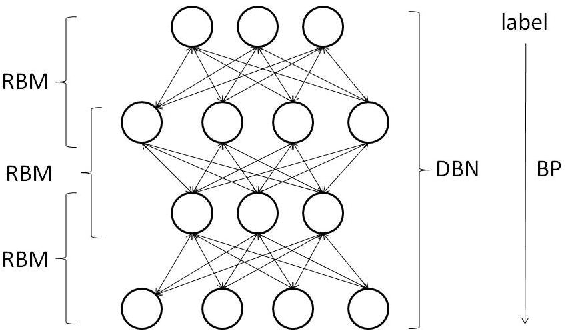
In this paper, we applied a novel learning algorithm, namely, Deep Belief Networks (DBN) to word sense disambiguation (WSD). DBN is a probabilistic generative model composed of multiple layers of hidden units. DBN uses Restricted Boltzmann Machine (RBM) to greedily train layer by layer as a pretraining. Then, a separate fine tuning step is employed to improve the discriminative power. We compared DBN with various state-of-the-art supervised learning algorithms in WSD such as Support Vector Machine (SVM), Maximum Entropy model (MaxEnt), Naive Bayes classifier (NB) and Kernel Principal Component Analysis (KPCA). We used all words in the given paragraph, surrounding context words and part-of-speech of surrounding words as our knowledge sources. We conducted our experiment on the SENSEVAL-2 data set. We observed that DBN outperformed all other learning algorithms.