 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotFast Networks with Memory Augmented Lateral Transformers for Lipreading
Paper and Code
May 21, 2020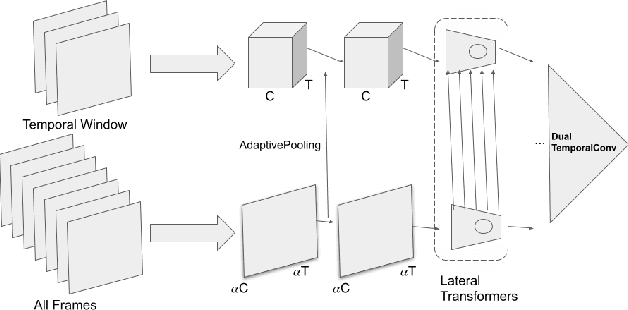

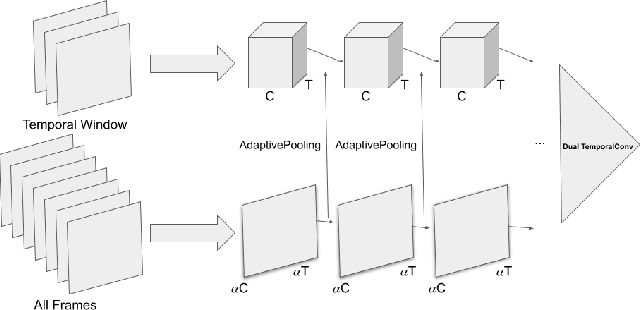
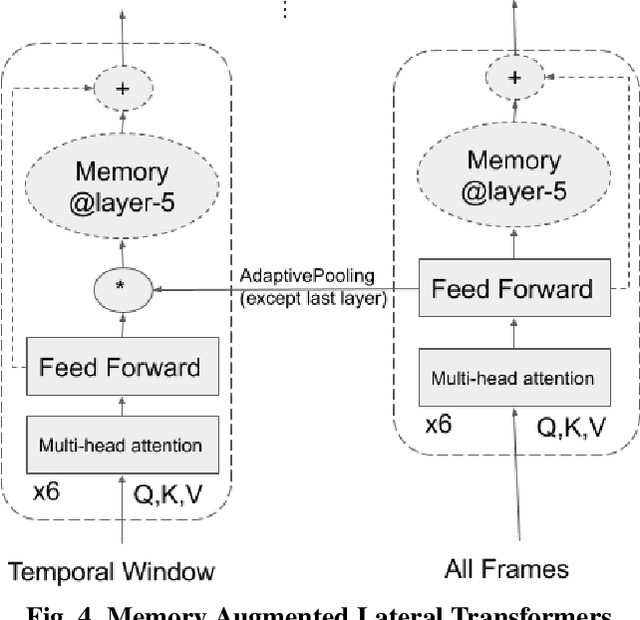
This paper presents a novel deep learning architecture for word-level lipreading. Previous works suggest a potential for incorporating a pretrained deep 3D Convolutional Neural Networks as a front-end feature extractor. We introduce a SpotFast networks, a variant of the state-of-the-art SlowFast networks for action recognition, which utilizes a temporal window as a spot pathway and all frames as a fast pathway. We further incorporate memory augmented lateral transformers to learn sequential features for classification. We evaluate the proposed model on the LRW dataset. The experiments show that our proposed model outperforms various state-of-the-art models and incorporating the memory augmented lateral transformers makes a 3.7% improvement to the SpotFast networks.