 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Sampling in Knowledge Graph Representation Learning: A Review
Feb 29, 2024

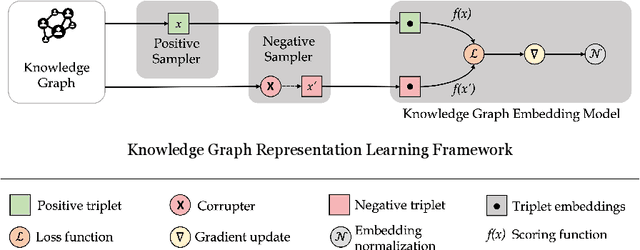
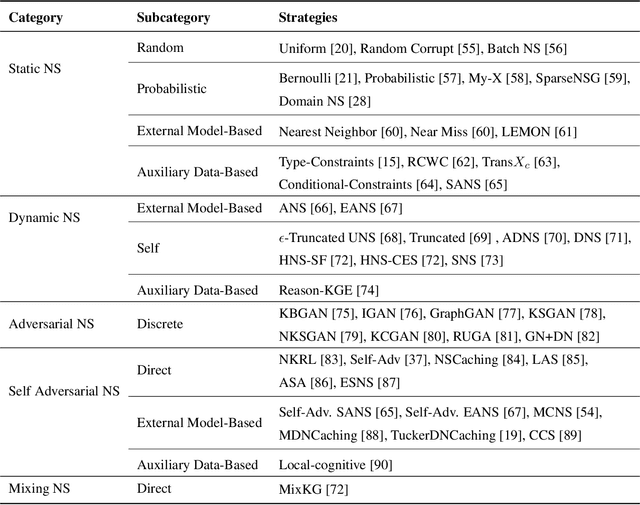
Knowledge graph representation learning (KGRL) or knowledge graph embedding (KGE) plays a crucial role in AI applications for knowledge construction and information exploration. These models aim to encode entities and relations present in a knowledge graph into a lower-dimensional vector space. During the training process of KGE models, using positive and negative samples becomes essential for discrimination purposes. However, obtaining negative samples directly from existing knowledge graphs poses a challenge, emphasizing the need for effective generation techniques. The quality of these negative samples greatly impacts the accuracy of the learned embeddings, making their generation a critical aspect of KGRL. This comprehensive survey paper systematically reviews various negative sampling (NS) methods and their contributions to the success of KGRL. Their respective advantages and disadvantages are outlined by categorizing existing NS methods into five distinct categories. Moreover, this survey identifies open research questions that serve as potential directions for future investigations. By offering a generalization and alignment of fundamental NS concepts, this survey provides valuable insights for designing effective NS methods in the context of KGRL and serves as a motivating force for further advancements in the field.
TabEAno: Table to Knowledge Graph Entity Annotation
Oct 05, 2020
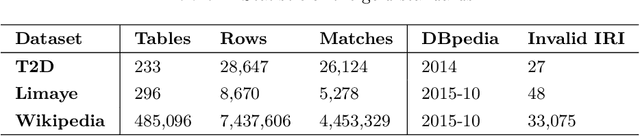
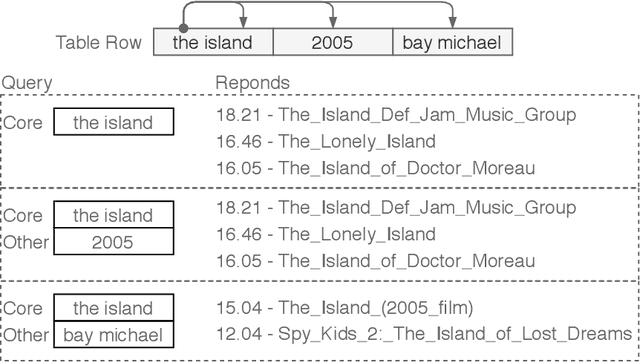
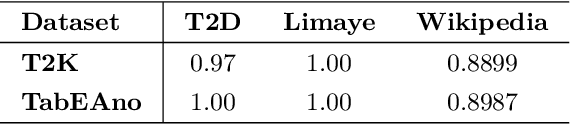
In the Open Data era, a large number of table resources have been made available on the Web and data portals. However, it is difficult to directly utilize such data due to the ambiguity of entities, name variations, heterogeneous schema, missing, or incomplete metadata. To address these issues, we propose a novel approach, namely TabEAno, to semantically annotate table rows toward knowledge graph entities. Specifically, we introduce a "two-cells" lookup strategy bases on the assumption that there is an existing logical relation occurring in the knowledge graph between the two closed cells in the same row of the table. Despite the simplicity of the approach, TabEAno outperforms the state of the art approaches in the two standard datasets e.g, T2D, Limaye with, and in the large-scale Wikipedia tables dataset.
MTab: Matching Tabular Data to Knowledge Graph using Probability Models
Oct 01, 2019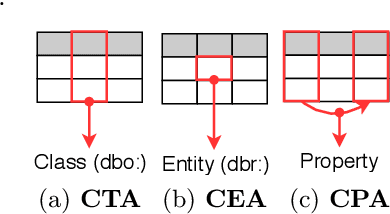
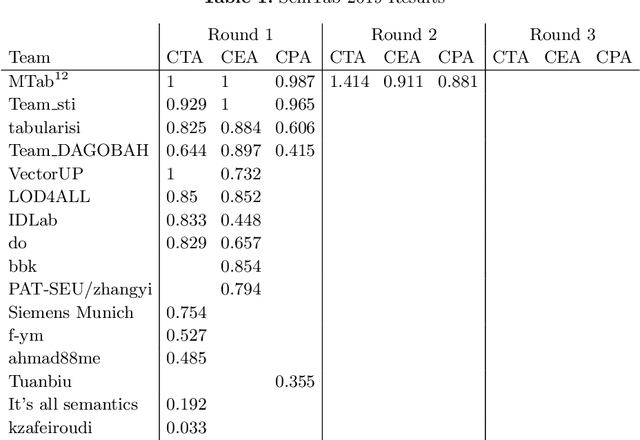
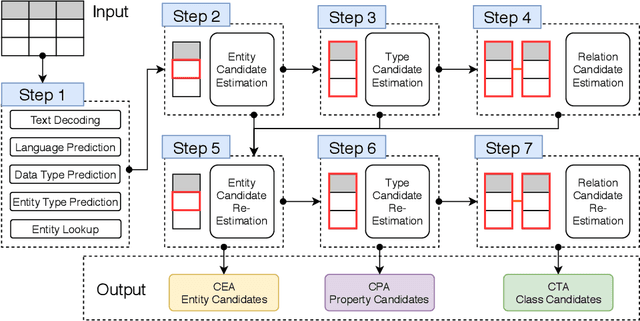
This paper presents the design of our system, namely MTab, for Semantic Web Challenge on Tabular Data to Knowledge Graph Matching (SemTab 2019). MTab combines the voting algorithm and the probability models to solve critical problems of the matching tasks. Results on SemTab 2019 show that MTab obtains promising performance for the three matching tasks.
Combination of Unified Embedding Model and Observed Features for Knowledge Graph Completion
Sep 10, 2019
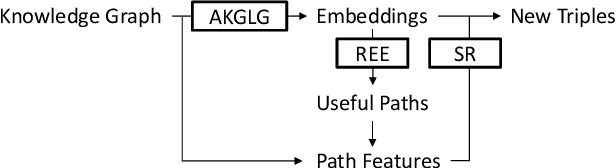
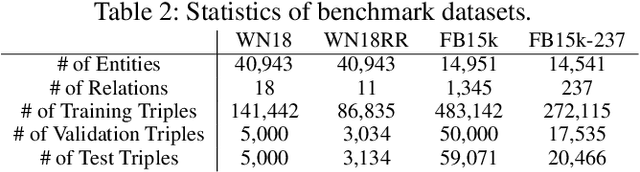
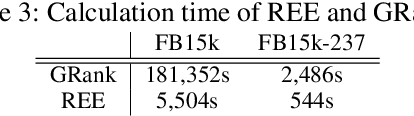
Knowledge graphs are useful for many artificial intelligence tasks but often have missing data. Hence, a method for completing knowledge graphs is required. Existing approaches include embedding models, the Path Ranking Algorithm, and rule evaluation models. However, these approaches have limitations. For example, all the information is mixed and difficult to interpret in embedding models, and traditional rule evaluation models are basically slow. In this paper, we provide an integrated view of various approaches and combine them to compensate for their limitations. We first unify state-of-the-art embedding models, such as ComplEx and TorusE, reinterpreting them as a variant of translation-based models. Then, we show that these models utilize paths for link prediction and propose a method for evaluating rules based on this idea. Finally, we combine an embedding model and observed feature models to predict missing triples. This is possible because all of these models utilize paths. We also conduct experiments, including link prediction tasks, with standard datasets to evaluate our method and framework. The experiments show that our method can evaluate rules faster than traditional methods and that our framework outperforms state-of-the-art models in terms of link prediction.
Graph Pattern Entity Ranking Model for Knowledge Graph Completion
Apr 05, 2019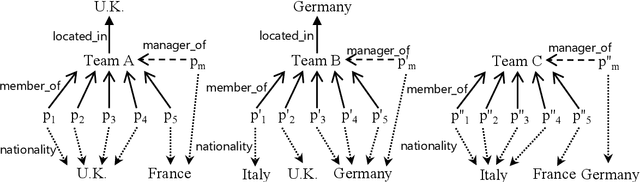
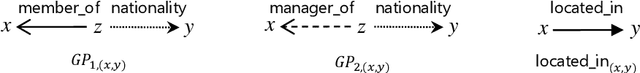
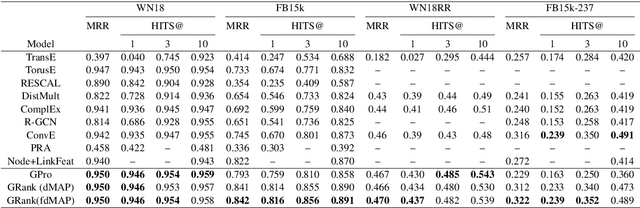
Knowledge graphs have evolved rapidly in recent years and their usefulness has been demonstrated in many artificial intelligence tasks. However, knowledge graphs often have lots of missing facts. To solve this problem, many knowledge graph embedding models have been developed to populate knowledge graphs and these have shown outstanding performance. However, knowledge graph embedding models are so-called black boxes, and the user does not know how the information in a knowledge graph is processed and the models can be difficult to interpret. In this paper, we utilize graph patterns in a knowledge graph to overcome such problems. Our proposed model, the {\it graph pattern entity ranking model} (GRank), constructs an entity ranking system for each graph pattern and evaluates them using a ranking measure. By doing so, we can find graph patterns which are useful for predicting facts. Then, we perform link prediction tasks on standard datasets to evaluate our GRank method. We show that our approach outperforms other state-of-the-art approaches such as ComplEx and TorusE for standard metrics such as HITS@{\it n} and MRR. Moreover, our model is easily interpretable because the output facts are described by graph patterns.
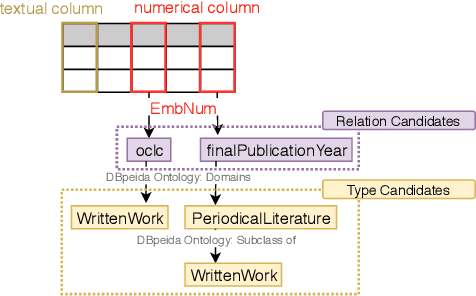
EmbNum: Semantic labeling for numerical values with deep metric learning
Aug 16, 2018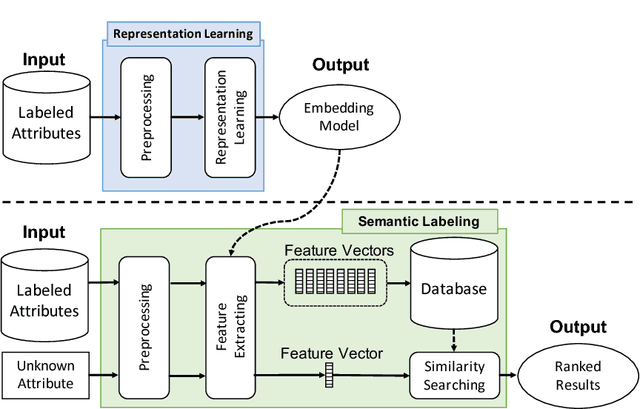

Semantic labeling for numerical values is a task of assigning semantic labels to unknown numerical attributes. The semantic labels could be numerical properties in ontologies, instances in knowledge bases, or labeled data that are manually annotated by domain experts. In this paper, we refer to semantic labeling as a retrieval setting where the label of an unknown attribute is assigned by the label of the most relevant attribute in labeled data. One of the greatest challenges is that an unknown attribute rarely has the same set of values with the similar one in the labeled data. To overcome the issue, statistical interpretation of value distribution is taken into account. However, the existing studies assume a specific form of distribution. It is not appropriate in particular to apply open data where there is no knowledge of data in advance. To address these problems, we propose a neural numerical embedding model (EmbNum) to learn useful representation vectors for numerical attributes without prior assumptions on the distribution of data. Then, the "semantic similarities" between the attributes are measured on these representation vectors by the Euclidean distance. Our empirical experiments on City Data and Open Data show that EmbNum significantly outperforms state-of-the-art methods for the task of numerical attribute semantic labeling regarding effectiveness and efficiency.
Deep Reinforcement Learning Boosted by External Knowledge
Dec 12, 2017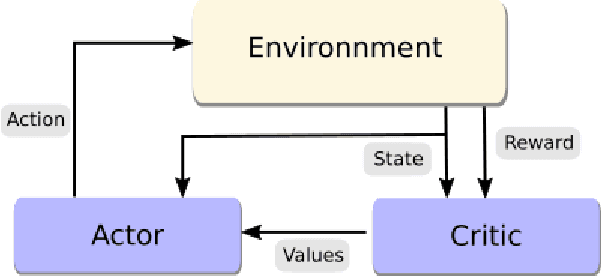

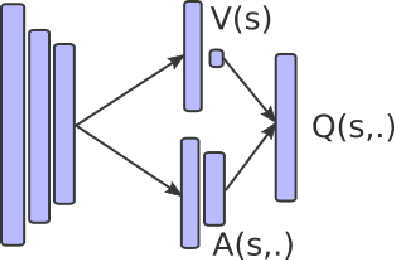

Recent improvements in deep reinforcement learning have allowed to solve problems in many 2D domains such as Atari games. However, in complex 3D environments, numerous learning episodes are required which may be too time consuming or even impossible especially in real-world scenarios. We present a new architecture to combine external knowledge and deep reinforcement learning using only visual input. A key concept of our system is augmenting image input by adding environment feature information and combining two sources of decision. We evaluate the performances of our method in a 3D partially-observable environment from the Microsoft Malmo platform. Experimental evaluation exhibits higher performance and faster learning compared to a single reinforcement learning model.
TorusE: Knowledge Graph Embedding on a Lie Group
Nov 15, 2017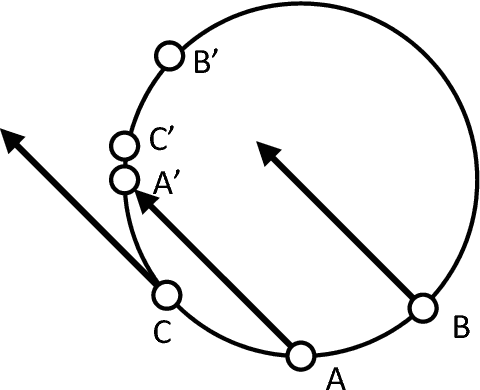
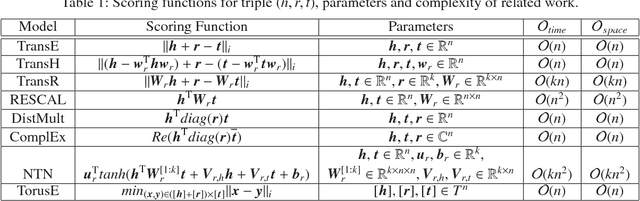
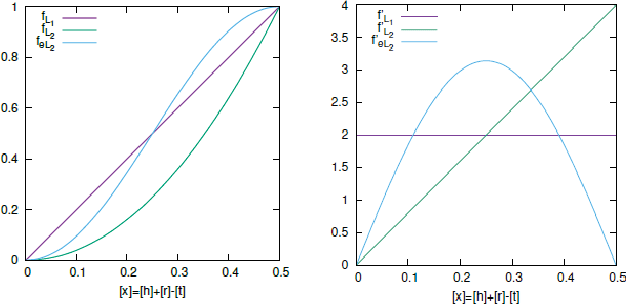
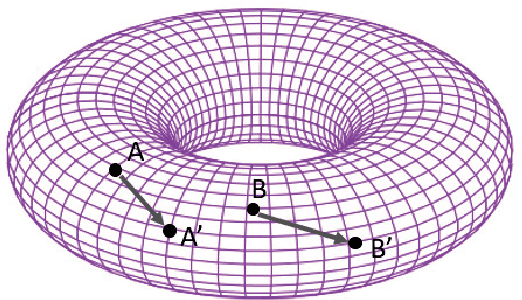
Knowledge graphs are useful for many artificial intelligence (AI) tasks. However, knowledge graphs often have missing facts. To populate the graphs, knowledge graph embedding models have been developed. Knowledge graph embedding models map entities and relations in a knowledge graph to a vector space and predict unknown triples by scoring candidate triples. TransE is the first translation-based method and it is well known because of its simplicity and efficiency for knowledge graph completion. It employs the principle that the differences between entity embeddings represent their relations. The principle seems very simple, but it can effectively capture the rules of a knowledge graph. However, TransE has a problem with its regularization. TransE forces entity embeddings to be on a sphere in the embedding vector space. This regularization warps the embeddings and makes it difficult for them to fulfill the abovementioned principle. The regularization also affects adversely the accuracies of the link predictions. On the other hand, regularization is important because entity embeddings diverge by negative sampling without it. This paper proposes a novel embedding model, TorusE, to solve the regularization problem. The principle of TransE can be defined on any Lie group. A torus, which is one of the compact Lie groups, can be chosen for the embedding space to avoid regularization. To the best of our knowledge, TorusE is the first model that embeds objects on other than a real or complex vector space, and this paper is the first to formally discuss the problem of regularization of TransE. Our approach outperforms other state-of-the-art approaches such as TransE, DistMult and ComplEx on a standard link prediction task. We show that TorusE is scalable to large-size knowledge graphs and is faster than the original TransE.
Integrating Know-How into the Linked Data Cloud
Apr 15, 2016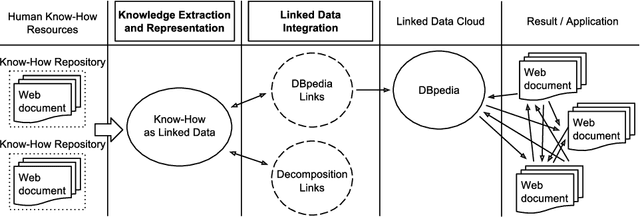

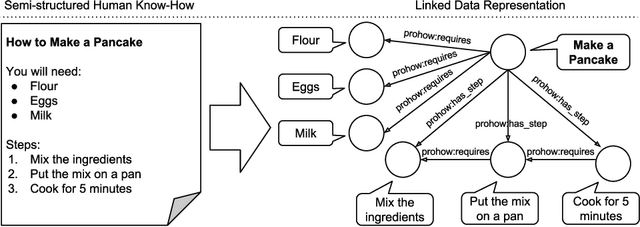
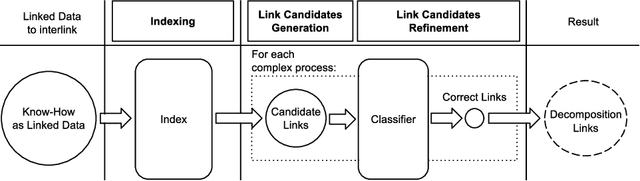
This paper presents the first framework for integrating procedural knowledge, or "know-how", into the Linked Data Cloud. Know-how available on the Web, such as step-by-step instructions, is largely unstructured and isolated from other sources of online knowledge. To overcome these limitations, we propose extending to procedural knowledge the benefits that Linked Data has already brought to representing, retrieving and reusing declarative knowledge. We describe a framework for representing generic know-how as Linked Data and for automatically acquiring this representation from existing resources on the Web. This system also allows the automatic generation of links between different know-how resources, and between those resources and other online knowledge bases, such as DBpedia. We discuss the results of applying this framework to a real-world scenario and we show how it outperforms existing manual community-driven integration efforts.
* The 19th International Conference on Knowledge Engineering and Knowledge Management (EKAW 2014), 24-28 November 2014, Link\"oping, Sweden
Sub-Classifier Construction for Error Correcting Output Code Using Minimum Weight Perfect Matching
Dec 27, 2013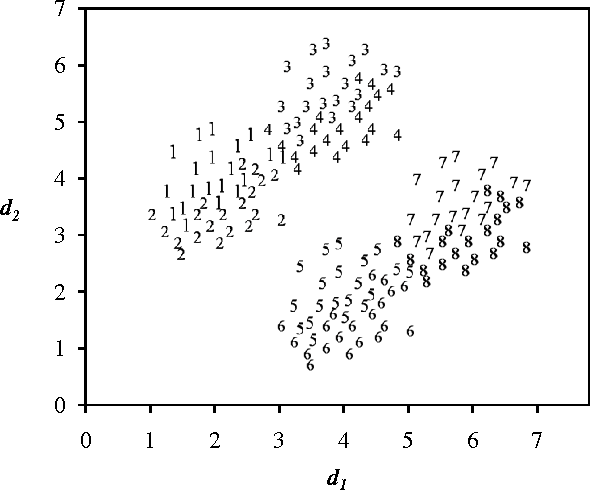
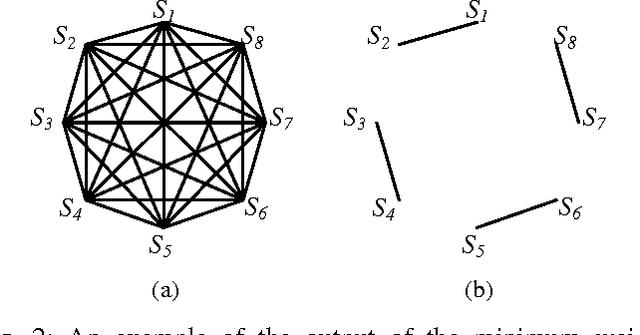
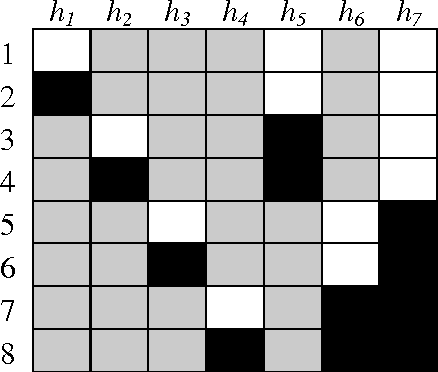
Multi-class classification is mandatory for real world problems and one of promising techniques for multi-class classification is Error Correcting Output Code. We propose a method for constructing the Error Correcting Output Code to obtain the suitable combination of positive and negative classes encoded to represent binary classifiers. The minimum weight perfect matching algorithm is applied to find the optimal pairs of subset of classes by using the generalization performance as a weighting criterion. Based on our method, each subset of classes with positive and negative labels is appropriately combined for learning the binary classifiers. Experimental results show that our technique gives significantly higher performance compared to traditional methods including the dense random code and the sparse random code both in terms of accuracy and classification times. Moreover, our method requires significantly smaller number of binary classifiers while maintaining accuracy compared to the One-Versus-One.