 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorusE: Knowledge Graph Embedding on a Lie Group
Paper and Code
Nov 15, 2017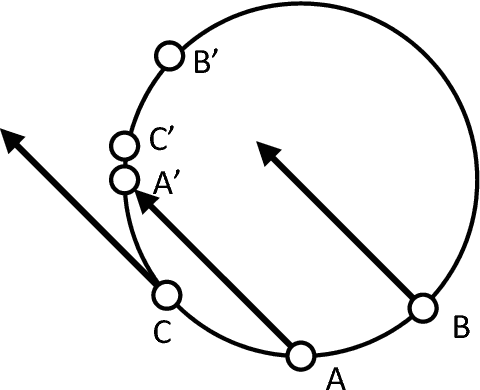
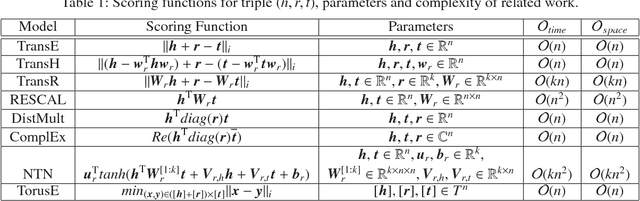
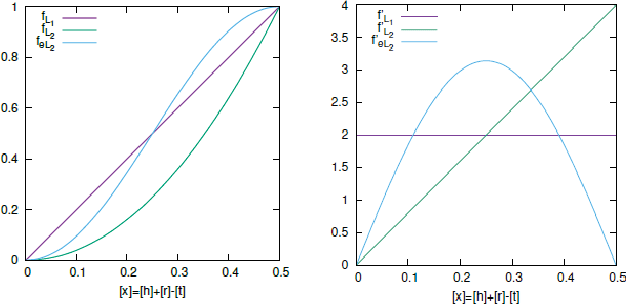
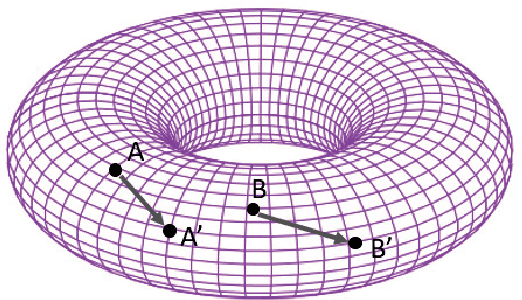
Knowledge graphs are useful for many artificial intelligence (AI) tasks. However, knowledge graphs often have missing facts. To populate the graphs, knowledge graph embedding models have been developed. Knowledge graph embedding models map entities and relations in a knowledge graph to a vector space and predict unknown triples by scoring candidate triples. TransE is the first translation-based method and it is well known because of its simplicity and efficiency for knowledge graph completion. It employs the principle that the differences between entity embeddings represent their relations. The principle seems very simple, but it can effectively capture the rules of a knowledge graph. However, TransE has a problem with its regularization. TransE forces entity embeddings to be on a sphere in the embedding vector space. This regularization warps the embeddings and makes it difficult for them to fulfill the abovementioned principle. The regularization also affects adversely the accuracies of the link predictions. On the other hand, regularization is important because entity embeddings diverge by negative sampling without it. This paper proposes a novel embedding model, TorusE, to solve the regularization problem. The principle of TransE can be defined on any Lie group. A torus, which is one of the compact Lie groups, can be chosen for the embedding space to avoid regularization. To the best of our knowledge, TorusE is the first model that embeds objects on other than a real or complex vector space, and this paper is the first to formally discuss the problem of regularization of TransE. Our approach outperforms other state-of-the-art approaches such as TransE, DistMult and ComplEx on a standard link prediction task. We show that TorusE is scalable to large-size knowledge graphs and is faster than the original TransE.