 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning Boosted by External Knowledge
Paper and Code
Dec 12, 2017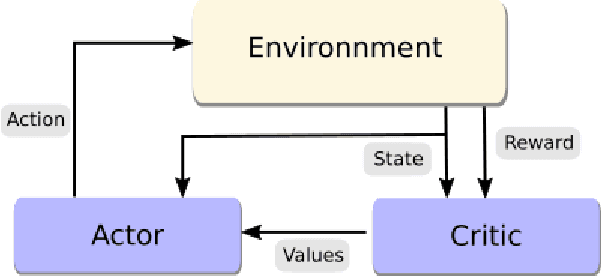

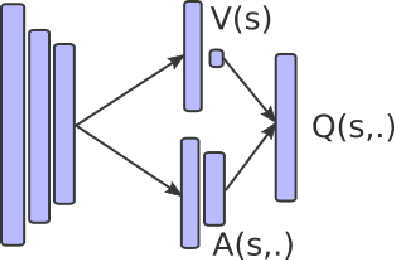

Recent improvements in deep reinforcement learning have allowed to solve problems in many 2D domains such as Atari games. However, in complex 3D environments, numerous learning episodes are required which may be too time consuming or even impossible especially in real-world scenarios. We present a new architecture to combine external knowledge and deep reinforcement learning using only visual input. A key concept of our system is augmenting image input by adding environment feature information and combining two sources of decision. We evaluate the performances of our method in a 3D partially-observable environment from the Microsoft Malmo platform. Experimental evaluation exhibits higher performance and faster learning compared to a single reinforcement learning model.