 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Decision Trees for Multi-class Support Vector Machines Using Entropy and Generalization Error Estimation
Aug 28, 2017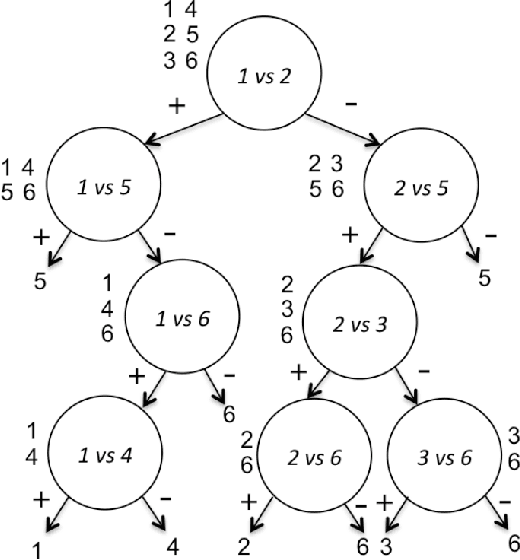
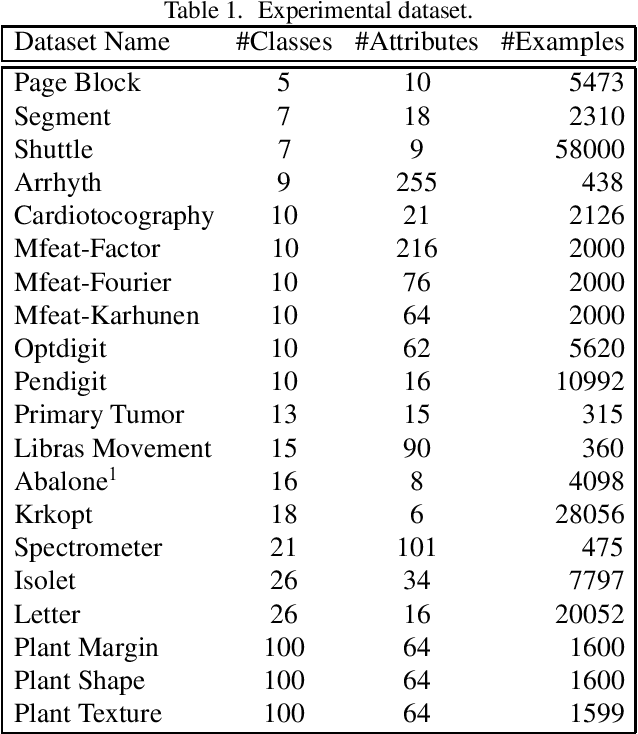
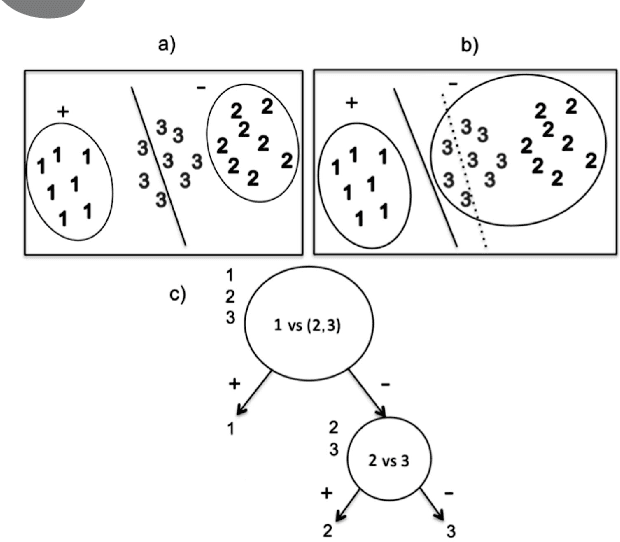
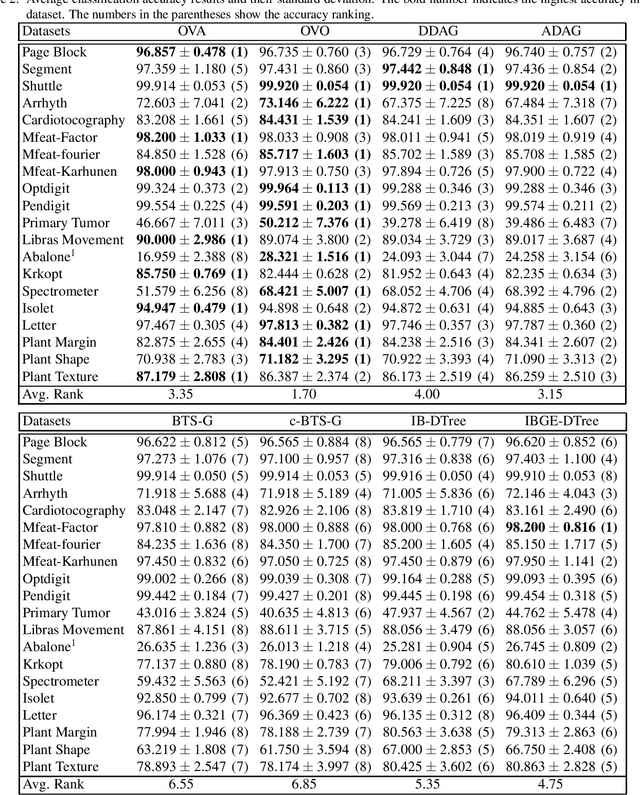
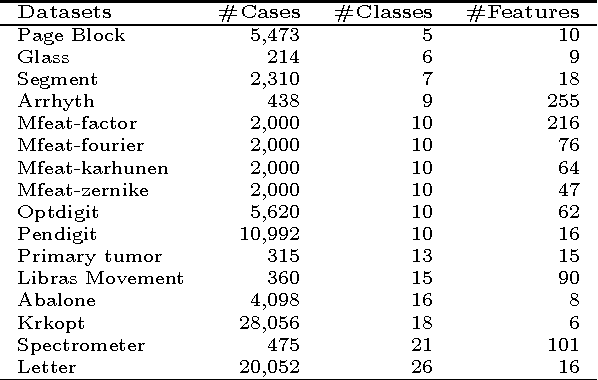
We propose new methods for Support Vector Machines (SVMs) using tree architecture for multi-class classi- fication. In each node of the tree, we select an appropriate binary classifier using entropy and generalization error estimation, then group the examples into positive and negative classes based on the selected classi- fier and train a new classifier for use in the classification phase. The proposed methods can work in time complexity between O(log2N) to O(N) where N is the number of classes. We compared the performance of our proposed methods to the traditional techniques on the UCI machine learning repository using 10-fold cross-validation. The experimental results show that our proposed methods are very useful for the problems that need fast classification time or problems with a large number of classes as the proposed methods run much faster than the traditional techniques but still provide comparable accuracy.
Sub-Classifier Construction for Error Correcting Output Code Using Minimum Weight Perfect Matching
Dec 27, 2013
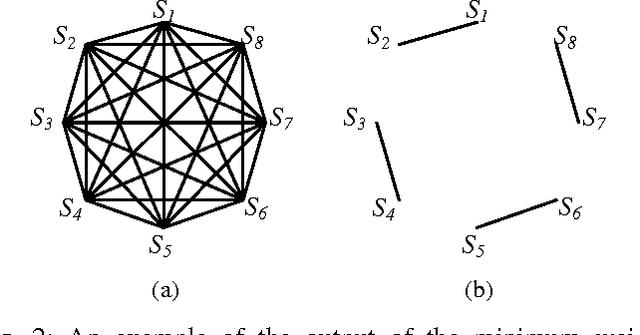
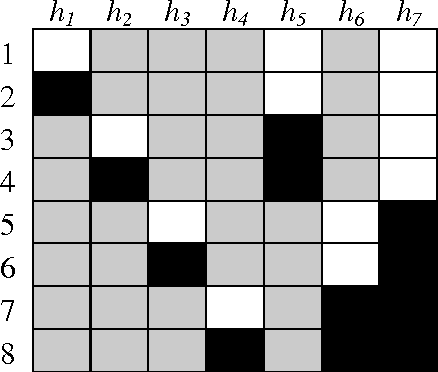
Multi-class classification is mandatory for real world problems and one of promising techniques for multi-class classification is Error Correcting Output Code. We propose a method for constructing the Error Correcting Output Code to obtain the suitable combination of positive and negative classes encoded to represent binary classifiers. The minimum weight perfect matching algorithm is applied to find the optimal pairs of subset of classes by using the generalization performance as a weighting criterion. Based on our method, each subset of classes with positive and negative labels is appropriately combined for learning the binary classifiers. Experimental results show that our technique gives significantly higher performance compared to traditional methods including the dense random code and the sparse random code both in terms of accuracy and classification times. Moreover, our method requires significantly smaller number of binary classifiers while maintaining accuracy compared to the One-Versus-One.
Enhancements of Multi-class Support Vector Machine Construction from Binary Learners using Generalization Performance
Sep 11, 2013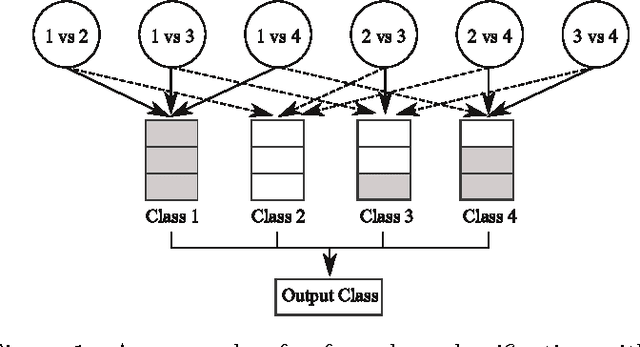
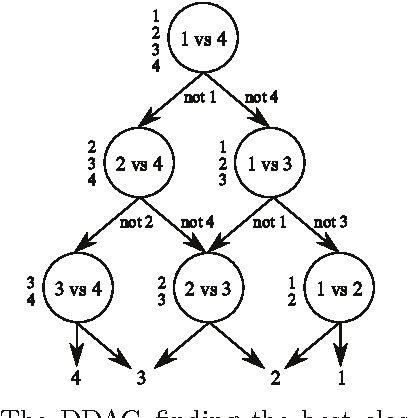
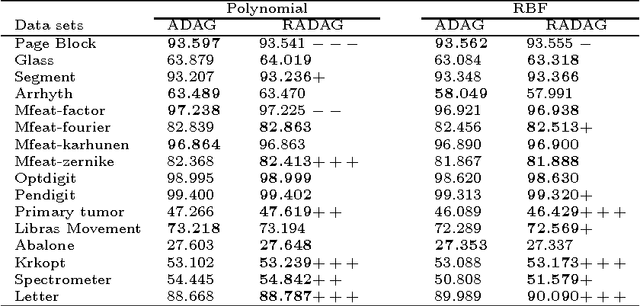
We propose several novel methods for enhancing the multi-class SVMs by applying the generalization performance of binary classifiers as the core idea. This concept will be applied on the existing algorithms, i.e., the Decision Directed Acyclic Graph (DDAG), the Adaptive Directed Acyclic Graphs (ADAG), and Max Wins. Although in the previous approaches there have been many attempts to use some information such as the margin size and the number of support vectors as performance estimators for binary SVMs, they may not accurately reflect the actual performance of the binary SVMs. We show that the generalization ability evaluated via a cross-validation mechanism is more suitable to directly extract the actual performance of binary SVMs. Our methods are built around this performance measure, and each of them is crafted to overcome the weakness of the previous algorithm. The proposed methods include the Reordering Adaptive Directed Acyclic Graph (RADAG), Strong Elimination of the classifiers (SE), Weak Elimination of the classifiers (WE), and Voting based Candidate Filtering (VCF). Experimental results demonstrate that our methods give significantly higher accuracy than all of the traditional ones. Especially, WE provides significantly superior results compared to Max Wins which is recognized as the state of the art algorithm in terms of both accuracy and classification speed with two times faster in average.