 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Data Augmentation to Improve Accuracy of Sleep Assessment and Sleep Individuality Analysis
Apr 16, 2024Recently, growing health awareness, novel methods allow individuals to monitor sleep at home. Utilizing sleep sounds offers advantages over conventional methods like smartwatches, being non-intrusive, and capable of detecting various physiological activities. This study aims to construct a machine learning-based sleep assessment model providing evidence-based assessments, such as poor sleep due to frequent movement during sleep onset. Extracting sleep sound events, deriving latent representations using VAE, clustering with GMM, and training LSTM for subjective sleep assessment achieved a high accuracy of 94.8% in distinguishing sleep satisfaction. Moreover, TimeSHAP revealed differences in impactful sound event types and timings for different individuals.
Adaptive Uncertainty-Guided Model Selection for Data-Driven PDE Discovery
Aug 31, 2023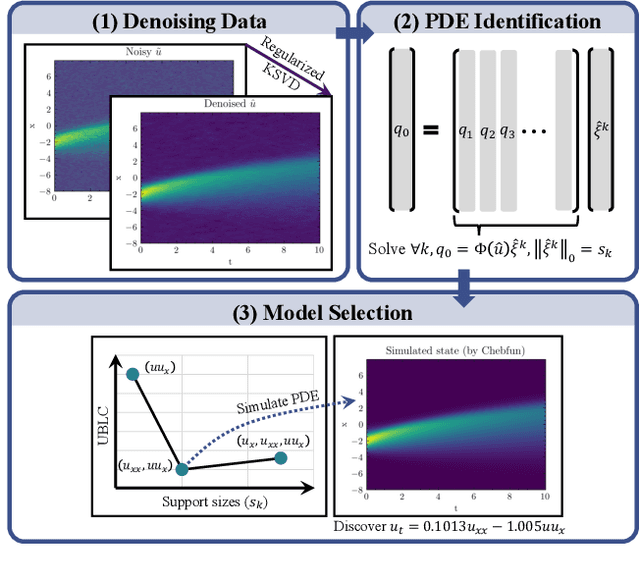



We propose a new parameter-adaptive uncertainty-penalized Bayesian information criterion (UBIC) to prioritize the parsimonious partial differential equation (PDE) that sufficiently governs noisy spatial-temporal observed data with few reliable terms. Since the naive use of the BIC for model selection has been known to yield an undesirable overfitted PDE, the UBIC penalizes the found PDE not only by its complexity but also the quantified uncertainty, derived from the model supports' coefficient of variation in a probabilistic view. We also introduce physics-informed neural network learning as a simulation-based approach to further validate the selected PDE flexibly against the other discovered PDE. Numerical results affirm the successful application of the UBIC in identifying the true governing PDE. Additionally, we reveal an interesting effect of denoising the observed data on improving the trade-off between the BIC score and model complexity. Code is available at https://github.com/Pongpisit-Thanasutives/UBIC.
Noise-aware Physics-informed Machine Learning for Robust PDE Discovery
Jul 04, 2022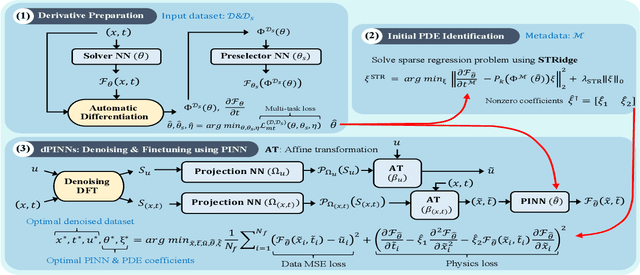
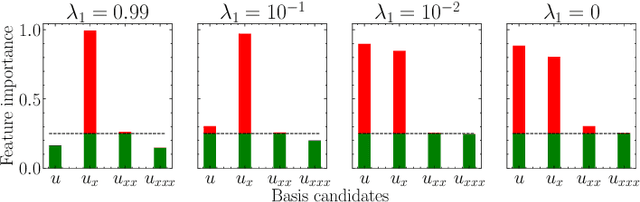
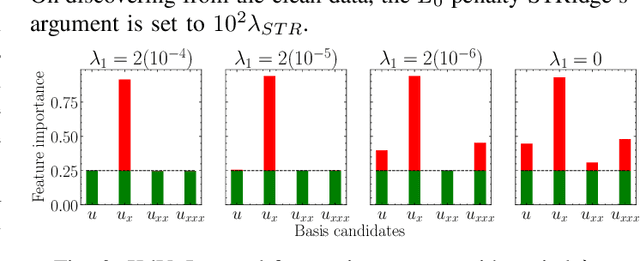
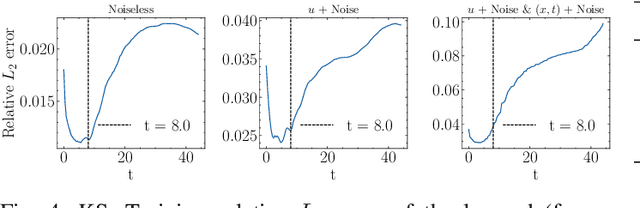
This work is concerned with discovering the governing partial differential equation (PDE) of a physical system. Existing methods have demonstrated the PDE identification from finite observations but failed to maintain satisfying performance against noisy data, partly owing to suboptimal estimated derivatives and found PDE coefficients. We address the issues by introducing a noise-aware physics-informed machine learning (nPIML) framework to discover the governing PDE from data following arbitrary distributions. Our proposals are twofold. First, we propose a couple of neural networks, namely solver and preselector, which yield an interpretable neural representation of the hidden physical constraint. After they are jointly trained, the solver network approximates potential candidates, e.g., partial derivatives, which are then fed to the sparse regression algorithm that initially unveils the most likely parsimonious PDE, decided according to the information criterion. Second, we propose the denoising physics-informed neural networks (dPINNs), based on Discrete Fourier Transform (DFT), to deliver a set of the optimal finetuned PDE coefficients respecting the noise-reduced variables. The denoising PINNs' structures are compartmentalized into forefront projection networks and a PINN, by which the formerly learned solver initializes. Our extensive experiments on five canonical PDEs affirm that the proposed framework presents a robust and interpretable approach for PDE discovery, applicable to a wide range of systems, possibly complicated by noise.
Adversarial Multi-task Learning Enhanced Physics-informed Neural Networks for Solving Partial Differential Equations
May 12, 2021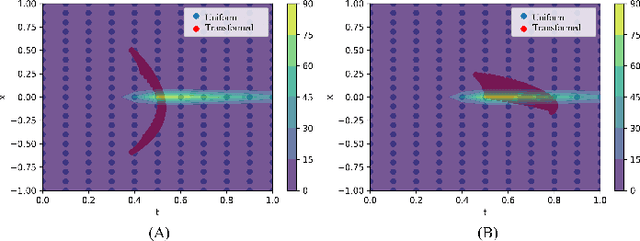
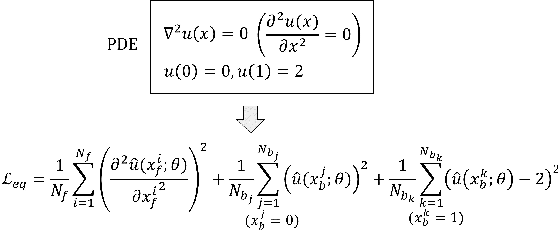
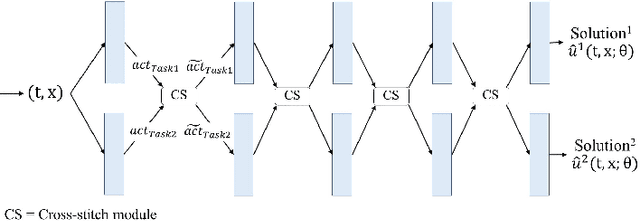
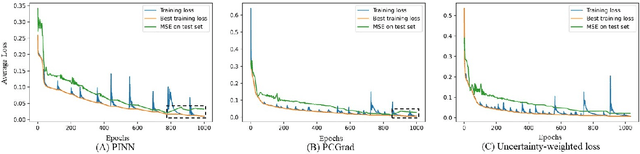
Recently, researchers have utilized neural networks to accurately solve partial differential equations (PDEs), enabling the mesh-free method for scientific computation. Unfortunately, the network performance drops when encountering a high nonlinearity domain. To improve the generalizability, we introduce the novel approach of employing multi-task learning techniques, the uncertainty-weighting loss and the gradients surgery, in the context of learning PDE solutions. The multi-task scheme exploits the benefits of learning shared representations, controlled by cross-stitch modules, between multiple related PDEs, which are obtainable by varying the PDE parameterization coefficients, to generalize better on the original PDE. Encouraging the network pay closer attention to the high nonlinearity domain regions that are more challenging to learn, we also propose adversarial training for generating supplementary high-loss samples, similarly distributed to the original training distribution. In the experiments, our proposed methods are found to be effective and reduce the error on the unseen data points as compared to the previous approaches in various PDE examples, including high-dimensional stochastic PDEs.
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
Apr 13, 2020
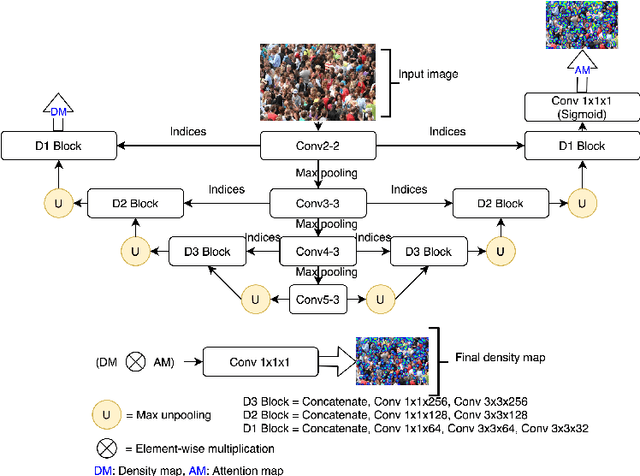
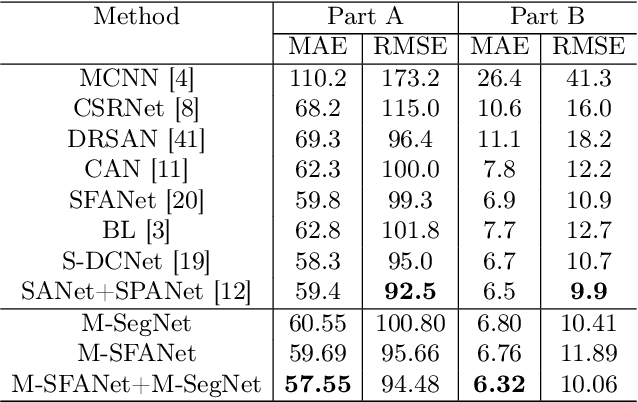
In this paper, we proposed two modified neural network architectures based on SFANet and SegNet respectively for accurate and efficient crowd counting. Inspired by SFANet, the first model is attached with two novel multi-scale-aware modules, called ASSP and CAN. This model is named M-SFANet. The encoder of M-SFANet is enhanced with ASSP containing parallel atrous convolutional layers with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage contextual module called CAN which adaptively encodes the scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on SFANet decoder structure, M-SFANet's decoder has dual paths, for density map generation and attention map generation. The second model is called M-SegNet, which is produced by replacing the bilinear upsampling in SFANet with max unpooling that is used in SegNet. This change provides the faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and are end-to-end trainable. We also conduct extensive experiments on five crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could outperform some of state-of-the-art crowd counting methods. Codes are available at https://github.com/Pongpisit-Thanasutives/Variations-of-SFANet-for-Crowd-Counting.
Spatiotemporal Emotion Recognition using Deep CNN Based on EEG during Music Listening
Oct 22, 2019
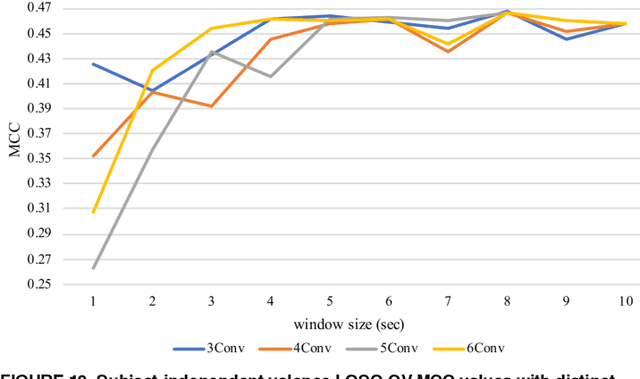
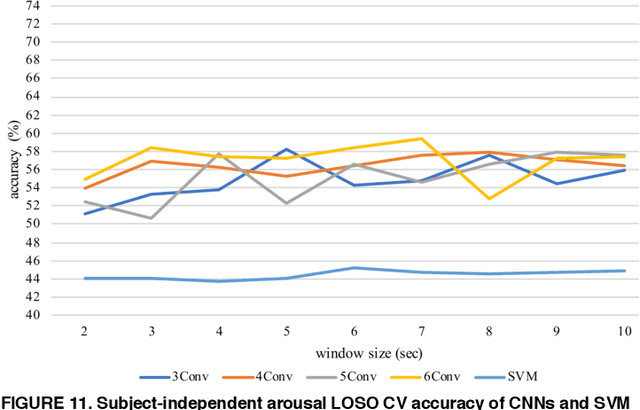
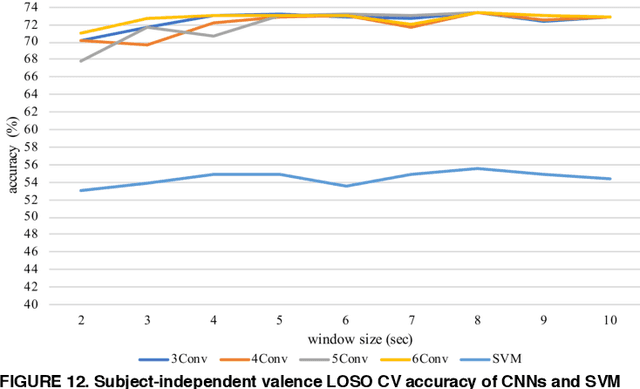
Emotion recognition based on EEG has become an active research area. As one of the machine learning models, CNN has been utilized to solve diverse problems including issues in this domain. In this work, a study of CNN and its spatiotemporal feature extraction has been conducted in order to explore capabilities of the model in varied window sizes and electrode orders. Our investigation was conducted in subject-independent fashion. Results have shown that temporal information in distinct window sizes significantly affects recognition performance in both 10-fold and leave-one-subject-out cross validation. Spatial information from varying electrode order has modicum effect on classification. SVM classifier depending on spatiotemporal knowledge on the same dataset was previously employed and compared to these empirical results. Even though CNN and SVM have a homologous trend in window size effect, CNN outperformed SVM using leave-one-subject-out cross validation. This could be caused by different extracted features in the elicitation process.
Efficient Decision Trees for Multi-class Support Vector Machines Using Entropy and Generalization Error Estimation
Aug 28, 2017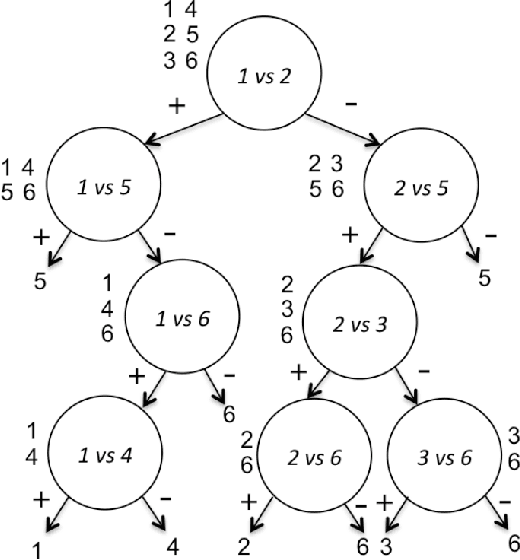
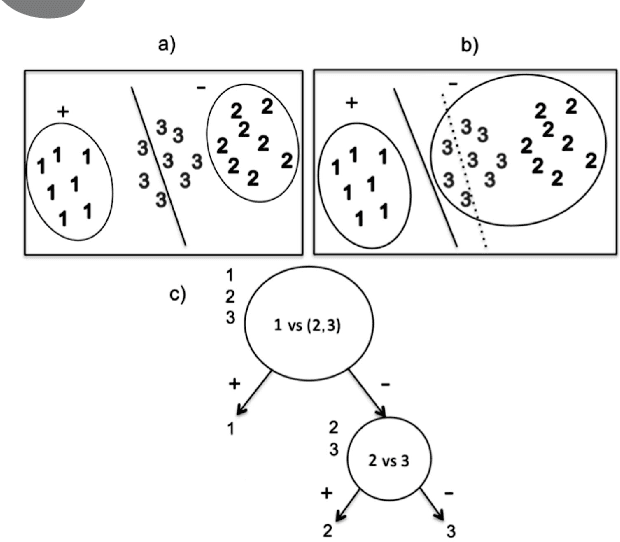
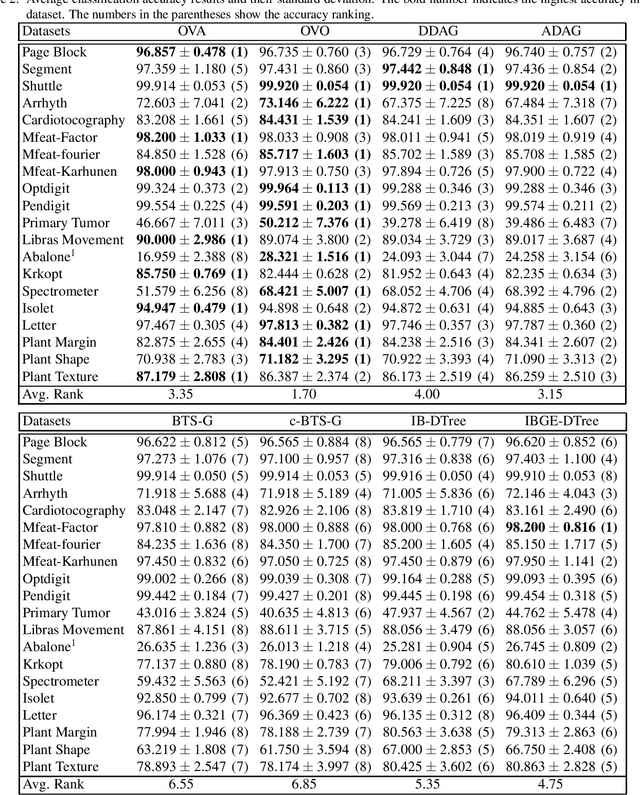
We propose new methods for Support Vector Machines (SVMs) using tree architecture for multi-class classi- fication. In each node of the tree, we select an appropriate binary classifier using entropy and generalization error estimation, then group the examples into positive and negative classes based on the selected classi- fier and train a new classifier for use in the classification phase. The proposed methods can work in time complexity between O(log2N) to O(N) where N is the number of classes. We compared the performance of our proposed methods to the traditional techniques on the UCI machine learning repository using 10-fold cross-validation. The experimental results show that our proposed methods are very useful for the problems that need fast classification time or problems with a large number of classes as the proposed methods run much faster than the traditional techniques but still provide comparable accuracy.
Fusion of EEG and Musical Features in Continuous Music-emotion Recognition
Nov 30, 2016
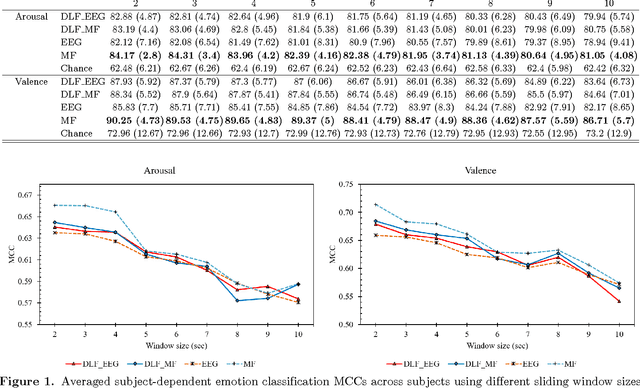
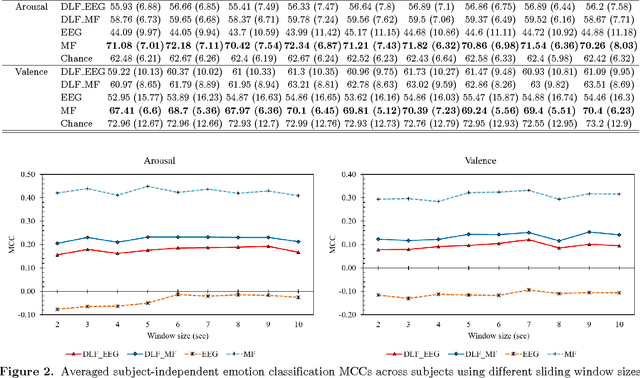
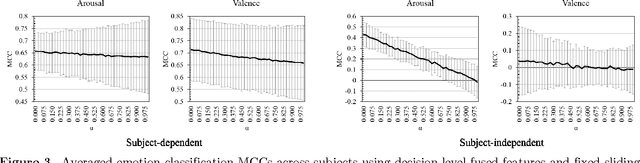
Emotion estimation in music listening is confronting challenges to capture the emotion variation of listeners. Recent years have witnessed attempts to exploit multimodality fusing information from musical contents and physiological signals captured from listeners to improve the performance of emotion recognition. In this paper, we present a study of fusion of signals of electroencephalogram (EEG), a tool to capture brainwaves at a high-temporal resolution, and musical features at decision level in recognizing the time-varying binary classes of arousal and valence. Our empirical results showed that the fusion could outperform the performance of emotion recognition using only EEG modality that was suffered from inter-subject variability, and this suggested the promise of multimodal fusion in improving the accuracy of music-emotion recognition.