 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing Toward the Simplex Vertices: A Simple Remedy for Code Collapse in Smoothed Vector Quantization
Sep 26, 2025



Vector quantization, which discretizes a continuous vector space into a finite set of representative vectors (a codebook), has been widely adopted in modern machine learning. Despite its effectiveness, vector quantization poses a fundamental challenge: the non-differentiable quantization step blocks gradient backpropagation. Smoothed vector quantization addresses this issue by relaxing the hard assignment of a codebook vector into a weighted combination of codebook entries, represented as the matrix product of a simplex vector and the codebook. Effective smoothing requires two properties: (1) smoothed quantizers should remain close to a onehot vector, ensuring tight approximation, and (2) all codebook entries should be utilized, preventing code collapse. Existing methods typically address these desiderata separately. By contrast, the present study introduces a simple and intuitive regularization that promotes both simultaneously by minimizing the distance between each simplex vertex and its $K$-nearest smoothed quantizers. Experiments on representative benchmarks, including discrete image autoencoding and contrastive speech representation learning, demonstrate that the proposed method achieves more reliable codebook utilization and improves performance compared to prior approaches.
Unsupervised Classification of English Words Based on Phonological Information: Discovery of Germanic and Latinate Clusters
Apr 16, 2025Cross-linguistically, native words and loanwords follow different phonological rules. In English, for example, words of Germanic and Latinate origin exhibit different stress patterns, and a certain syntactic structure is exclusive to Germanic verbs. When seeing them as a cognitive model, however, such etymology-based generalizations face challenges in terms of learnability, since the historical origins of words are presumably inaccessible information for general language learners. In this study, we present computational evidence indicating that the Germanic-Latinate distinction in the English lexicon is learnable from the phonotactic information of individual words. Specifically, we performed an unsupervised clustering on corpus-extracted words, and the resulting word clusters largely aligned with the etymological distinction. The model-discovered clusters also recovered various linguistic generalizations documented in the previous literature regarding the corresponding etymological classes. Moreover, our findings also uncovered previously unrecognized features of the quasi-etymological clusters, offering novel hypotheses for future experimental studies.
Emergence of the Primacy Effect in Structured State-Space Models
Feb 20, 2025Human and animal memory for sequentially presented items is well-documented to be more accurate for those at the beginning and end of the sequence, phenomena known as the primacy and recency effects, respectively. By contrast, artificial neural network (ANN) models are typically designed with a memory that decays monotonically over time. Accordingly, ANNs are expected to show the recency effect but not the primacy effect. Contrary to this theoretical expectation, however, the present study reveals a counterintuitive finding: a recently developed ANN architecture, called structured state-space models, exhibits the primacy effect when trained and evaluated on a synthetic task that mirrors psychological memory experiments. Given that this model was originally designed for recovering neuronal activity patterns observed in biological brains, this result provides a novel perspective on the psychological primacy effect while also posing a non-trivial puzzle for the current theories in machine learning.
Oscillations enhance time-series prediction in reservoir computing with feedback
Jun 05, 2024Reservoir computing, a machine learning framework used for modeling the brain, can predict temporal data with little observations and minimal computational resources. However, it is difficult to accurately reproduce the long-term target time series because the reservoir system becomes unstable. This predictive capability is required for a wide variety of time-series processing, including predictions of motor timing and chaotic dynamical systems. This study proposes oscillation-driven reservoir computing (ODRC) with feedback, where oscillatory signals are fed into a reservoir network to stabilize the network activity and induce complex reservoir dynamics. The ODRC can reproduce long-term target time series more accurately than conventional reservoir computing methods in a motor timing and chaotic time-series prediction tasks. Furthermore, it generates a time series similar to the target in the unexperienced period, that is, it can learn the abstract generative rules from limited observations. Given these significant improvements made by the simple and computationally inexpensive implementation, the ODRC would serve as a practical model of various time series data. Moreover, we will discuss biological implications of the ODRC, considering it as a model of neural oscillations and their cerebellar processors.
Positional Encoding Helps Recurrent Neural Networks Handle a Large Vocabulary
Jan 31, 2024



This study discusses the effects of positional encoding on recurrent neural networks (RNNs) utilizing synthetic benchmarks. Positional encoding "time-stamps" data points in time series and complements the capabilities of Transformer neural networks, which lack an inherent mechanism for representing the data order. By contrast, RNNs can encode the temporal information of data points on their own, rendering their use of positional encoding seemingly "redundant". Nonetheless, empirical investigations reveal the effectiveness of positional encoding even when coupled with RNNs, specifically for handling a large vocabulary that yields diverse observations. These findings pave the way for a new line of research on RNNs, concerning the combination of input-driven and autonomous time representation. Additionally, biological implications of the computational/simulational results are discussed, in the light of the affinity between the sinusoidal implementation of positional encoding and neural oscillations in biological brains.
Adaptive Uncertainty-Guided Model Selection for Data-Driven PDE Discovery
Aug 31, 2023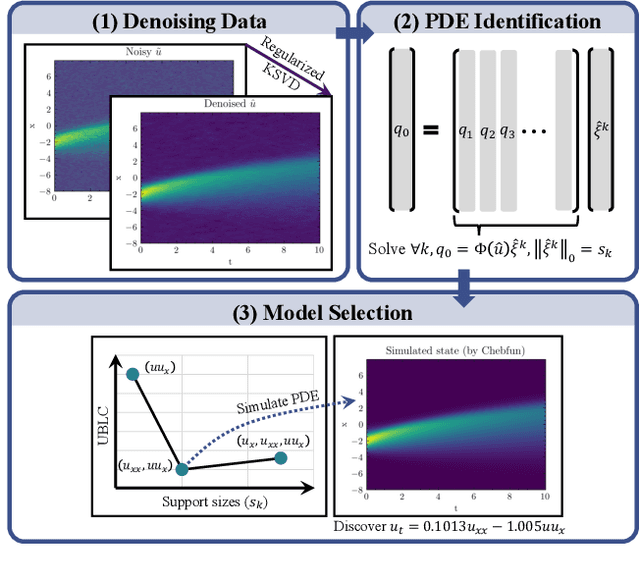



We propose a new parameter-adaptive uncertainty-penalized Bayesian information criterion (UBIC) to prioritize the parsimonious partial differential equation (PDE) that sufficiently governs noisy spatial-temporal observed data with few reliable terms. Since the naive use of the BIC for model selection has been known to yield an undesirable overfitted PDE, the UBIC penalizes the found PDE not only by its complexity but also the quantified uncertainty, derived from the model supports' coefficient of variation in a probabilistic view. We also introduce physics-informed neural network learning as a simulation-based approach to further validate the selected PDE flexibly against the other discovered PDE. Numerical results affirm the successful application of the UBIC in identifying the true governing PDE. Additionally, we reveal an interesting effect of denoising the observed data on improving the trade-off between the BIC score and model complexity. Code is available at https://github.com/Pongpisit-Thanasutives/UBIC.
Noise-aware Physics-informed Machine Learning for Robust PDE Discovery
Jul 04, 2022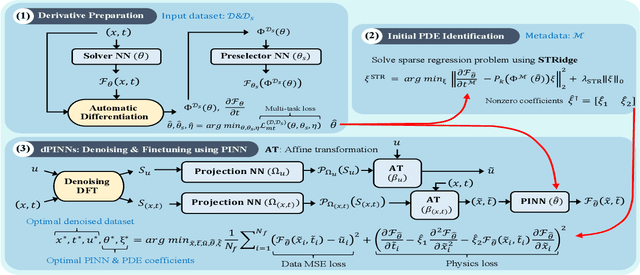
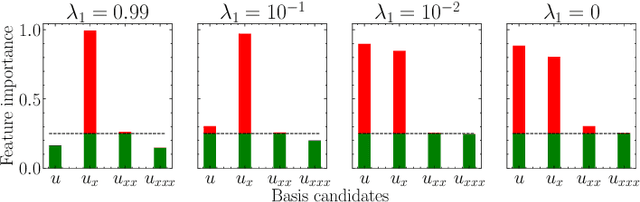
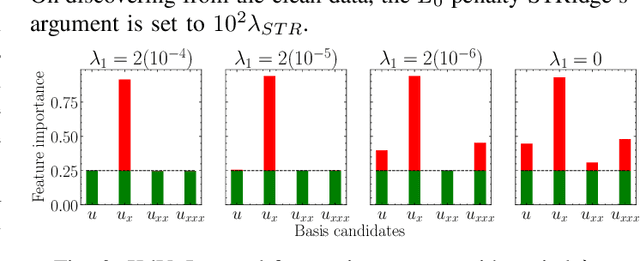
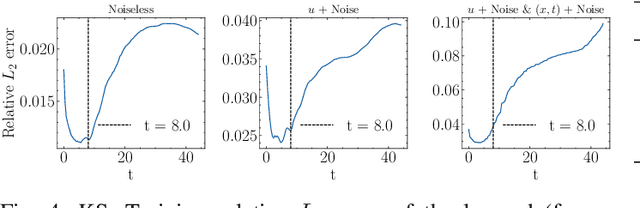
This work is concerned with discovering the governing partial differential equation (PDE) of a physical system. Existing methods have demonstrated the PDE identification from finite observations but failed to maintain satisfying performance against noisy data, partly owing to suboptimal estimated derivatives and found PDE coefficients. We address the issues by introducing a noise-aware physics-informed machine learning (nPIML) framework to discover the governing PDE from data following arbitrary distributions. Our proposals are twofold. First, we propose a couple of neural networks, namely solver and preselector, which yield an interpretable neural representation of the hidden physical constraint. After they are jointly trained, the solver network approximates potential candidates, e.g., partial derivatives, which are then fed to the sparse regression algorithm that initially unveils the most likely parsimonious PDE, decided according to the information criterion. Second, we propose the denoising physics-informed neural networks (dPINNs), based on Discrete Fourier Transform (DFT), to deliver a set of the optimal finetuned PDE coefficients respecting the noise-reduced variables. The denoising PINNs' structures are compartmentalized into forefront projection networks and a PINN, by which the formerly learned solver initializes. Our extensive experiments on five canonical PDEs affirm that the proposed framework presents a robust and interpretable approach for PDE discovery, applicable to a wide range of systems, possibly complicated by noise.
Exploring TTS without T Using Biologically/Psychologically Motivated Neural Network Modules (ZeroSpeech 2020)
May 15, 2020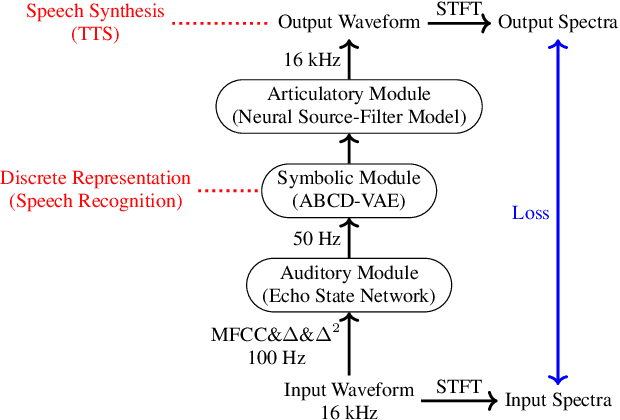

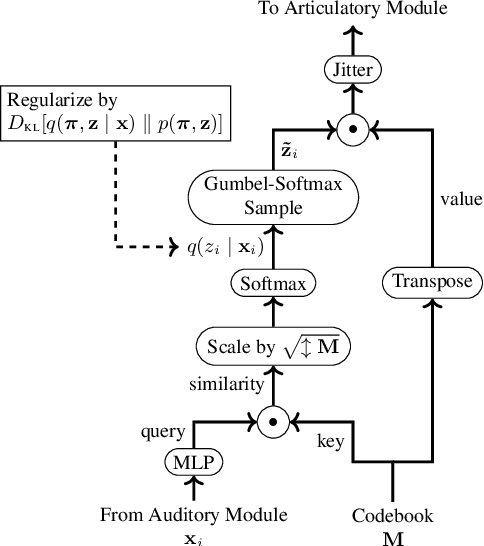

In this study, we reported our exploration of Text-To-Speech without Text (TTS without T) in the Zero Resource Speech Challenge 2020, in which participants proposed an end-to-end, unsupervised system that learned speech recognition and TTS together. We addressed the challenge using biologically/psychologically motivated modules of Artificial Neural Networks (ANN), with a particular interest in unsupervised learning of human language as a biological/psychological problem. The system first processes Mel Frequency Cepstral Coefficient (MFCC) frames with an Echo-State Network (ESN), and simulates computations in cortical microcircuits. The outcome is discretized by our original Variational Autoencoder (VAE) that implements the Dirichlet-based Bayesian clustering widely accepted in computational linguistics and cognitive science. The discretized signal is then reverted into sound waveform via a neural-network implementation of the source-filter model for speech production.
Neural Language Models as Psycholinguistic Subjects: Representations of Syntactic State
Mar 08, 2019



We deploy the methods of controlled psycholinguistic experimentation to shed light on the extent to which the behavior of neural network language models reflects incremental representations of syntactic state. To do so, we examine model behavior on artificial sentences containing a variety of syntactically complex structures. We test four models: two publicly available LSTM sequence models of English (Jozefowicz et al., 2016; Gulordava et al., 2018) trained on large datasets; an RNNG (Dyer et al., 2016) trained on a small, parsed dataset; and an LSTM trained on the same small corpus as the RNNG. We find evidence that the LSTMs trained on large datasets represent syntactic state over large spans of text in a way that is comparable to the RNNG, while the LSTM trained on the small dataset does not or does so only weakly.
Superregular grammars do not provide additional explanatory power but allow for a compact analysis of animal song
Nov 05, 2018



A pervasive belief with regard to the differences between human language and animal vocal sequences (song) is that they belong to different classes of computational complexity, with animal song belonging to regular languages, whereas human language is superregular. This argument, however, lacks empirical evidence since superregular analyses of animal song are understudied. The goal of this paper is to perform a superregular analysis of animal song, using data from gibbons as a case study, and demonstrate that a superregular analysis can be effectively used with non-human data. A key finding is that a superregular analysis does not increase explanatory power but rather provides for compact analysis. For instance, fewer grammatical rules are necessary once superregularity is allowed. This pattern is analogous to a previous computational analysis of human language, and accordingly, the null hypothesis, that human language and animal song are governed by the same type of grammatical systems, cannot be rejected.