 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring TTS without T Using Biologically/Psychologically Motivated Neural Network Modules (ZeroSpeech 2020)
Paper and Code
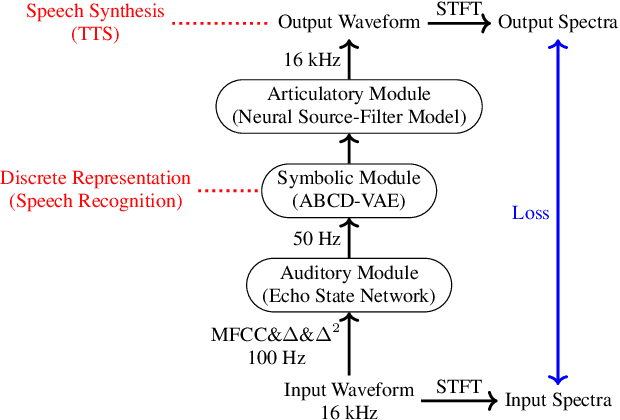

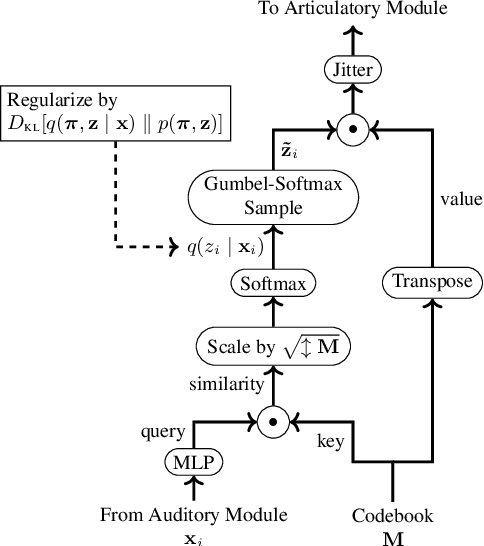

In this study, we reported our exploration of Text-To-Speech without Text (TTS without T) in the Zero Resource Speech Challenge 2020, in which participants proposed an end-to-end, unsupervised system that learned speech recognition and TTS together. We addressed the challenge using biologically/psychologically motivated modules of Artificial Neural Networks (ANN), with a particular interest in unsupervised learning of human language as a biological/psychological problem. The system first processes Mel Frequency Cepstral Coefficient (MFCC) frames with an Echo-State Network (ESN), and simulates computations in cortical microcircuits. The outcome is discretized by our original Variational Autoencoder (VAE) that implements the Dirichlet-based Bayesian clustering widely accepted in computational linguistics and cognitive science. The discretized signal is then reverted into sound waveform via a neural-network implementation of the source-filter model for speech production.