 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring TTS without T Using Biologically/Psychologically Motivated Neural Network Modules (ZeroSpeech 2020)
May 15, 2020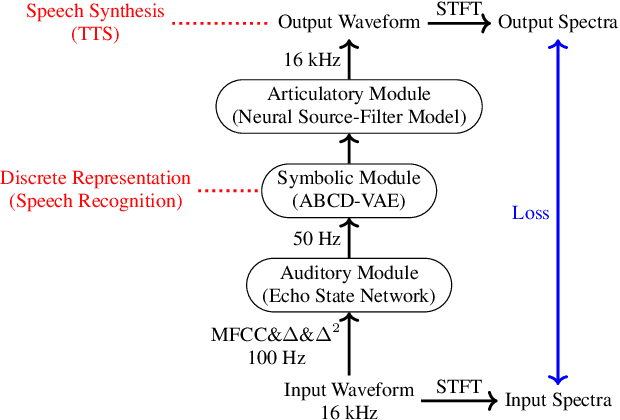

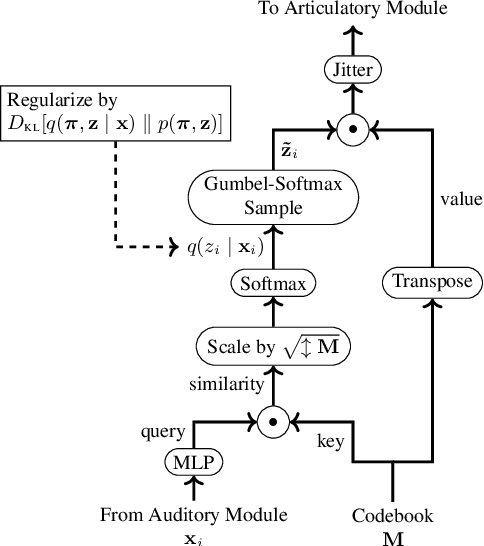

In this study, we reported our exploration of Text-To-Speech without Text (TTS without T) in the Zero Resource Speech Challenge 2020, in which participants proposed an end-to-end, unsupervised system that learned speech recognition and TTS together. We addressed the challenge using biologically/psychologically motivated modules of Artificial Neural Networks (ANN), with a particular interest in unsupervised learning of human language as a biological/psychological problem. The system first processes Mel Frequency Cepstral Coefficient (MFCC) frames with an Echo-State Network (ESN), and simulates computations in cortical microcircuits. The outcome is discretized by our original Variational Autoencoder (VAE) that implements the Dirichlet-based Bayesian clustering widely accepted in computational linguistics and cognitive science. The discretized signal is then reverted into sound waveform via a neural-network implementation of the source-filter model for speech production.
Superregular grammars do not provide additional explanatory power but allow for a compact analysis of animal song
Nov 05, 2018



A pervasive belief with regard to the differences between human language and animal vocal sequences (song) is that they belong to different classes of computational complexity, with animal song belonging to regular languages, whereas human language is superregular. This argument, however, lacks empirical evidence since superregular analyses of animal song are understudied. The goal of this paper is to perform a superregular analysis of animal song, using data from gibbons as a case study, and demonstrate that a superregular analysis can be effectively used with non-human data. A key finding is that a superregular analysis does not increase explanatory power but rather provides for compact analysis. For instance, fewer grammatical rules are necessary once superregularity is allowed. This pattern is analogous to a previous computational analysis of human language, and accordingly, the null hypothesis, that human language and animal song are governed by the same type of grammatical systems, cannot be rejected.