 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Anomalies in Machine Learning Infrastructure via Hardware Telemetry
Oct 29, 2025Modern machine learning (ML) has grown into a tightly coupled, full-stack ecosystem that combines hardware, software, network, and applications. Many users rely on cloud providers for elastic, isolated, and cost-efficient resources. Unfortunately, these platforms as a service use virtualization, which means operators have little insight into the users' workloads. This hinders resource optimizations by the operator, which is essential to ensure cost efficiency and minimize execution time. In this paper, we argue that workload knowledge is unnecessary for system-level optimization. We propose System-X, which takes a \emph{hardware-centric} approach, relying only on hardware signals -- fully accessible by operators. Using low-level signals collected from the system, System-X detects anomalies through an unsupervised learning pipeline. The pipeline is developed by analyzing over 30 popular ML models on various hardware platforms, ensuring adaptability to emerging workloads and unknown deployment patterns. Using System-X, we successfully identified both network and system configuration issues, accelerating the DeepSeek model by 5.97%.
LMAE4Eth: Generalizable and Robust Ethereum Fraud Detection by Exploring Transaction Semantics and Masked Graph Embedding
Sep 04, 2025Current Ethereum fraud detection methods rely on context-independent, numerical transaction sequences, failing to capture semantic of account transactions. Furthermore, the pervasive homogeneity in Ethereum transaction records renders it challenging to learn discriminative account embeddings. Moreover, current self-supervised graph learning methods primarily learn node representations through graph reconstruction, resulting in suboptimal performance for node-level tasks like fraud account detection, while these methods also encounter scalability challenges. To tackle these challenges, we propose LMAE4Eth, a multi-view learning framework that fuses transaction semantics, masked graph embedding, and expert knowledge. We first propose a transaction-token contrastive language model (TxCLM) that transforms context-independent numerical transaction records into logically cohesive linguistic representations. To clearly characterize the semantic differences between accounts, we also use a token-aware contrastive learning pre-training objective together with the masked transaction model pre-training objective, learns high-expressive account representations. We then propose a masked account graph autoencoder (MAGAE) using generative self-supervised learning, which achieves superior node-level account detection by focusing on reconstructing account node features. To enable MAGAE to scale for large-scale training, we propose to integrate layer-neighbor sampling into the graph, which reduces the number of sampled vertices by several times without compromising training quality. Finally, using a cross-attention fusion network, we unify the embeddings of TxCLM and MAGAE to leverage the benefits of both. We evaluate our method against 21 baseline approaches on three datasets. Experimental results show that our method outperforms the best baseline by over 10% in F1-score on two of the datasets.
Inside you are many wolves: Using cognitive models to interpret value trade-offs in LLMs
Jun 25, 2025



Navigating everyday social situations often requires juggling conflicting goals, such as conveying a harsh truth, maintaining trust, all while still being mindful of another person's feelings. These value trade-offs are an integral part of human decision-making and language use, however, current tools for interpreting such dynamic and multi-faceted notions of values in LLMs are limited. In cognitive science, so-called "cognitive models" provide formal accounts of these trade-offs in humans, by modeling the weighting of a speaker's competing utility functions in choosing an action or utterance. In this work, we use a leading cognitive model of polite speech to interpret the extent to which LLMs represent human-like trade-offs. We apply this lens to systematically evaluate value trade-offs in two encompassing model settings: degrees of reasoning "effort" in frontier black-box models, and RL post-training dynamics of open-source models. Our results highlight patterns of higher informational utility than social utility in reasoning models, and in open-source models shown to be stronger in mathematical reasoning. Our findings from LLMs' training dynamics suggest large shifts in utility values early on in training with persistent effects of the choice of base model and pretraining data, compared to feedback dataset or alignment method. We show that our method is responsive to diverse aspects of the rapidly evolving LLM landscape, with insights for forming hypotheses about other high-level behaviors, shaping training regimes for reasoning models, and better controlling trade-offs between values during model training.
Clean-image Backdoor Attacks
Mar 26, 2024



To gather a significant quantity of annotated training data for high-performance image classification models, numerous companies opt to enlist third-party providers to label their unlabeled data. This practice is widely regarded as secure, even in cases where some annotated errors occur, as the impact of these minor inaccuracies on the final performance of the models is negligible and existing backdoor attacks require attacker's ability to poison the training images. Nevertheless, in this paper, we propose clean-image backdoor attacks which uncover that backdoors can still be injected via a fraction of incorrect labels without modifying the training images. Specifically, in our attacks, the attacker first seeks a trigger feature to divide the training images into two parts: those with the feature and those without it. Subsequently, the attacker falsifies the labels of the former part to a backdoor class. The backdoor will be finally implanted into the target model after it is trained on the poisoned data. During the inference phase, the attacker can activate the backdoor in two ways: slightly modifying the input image to obtain the trigger feature, or taking an image that naturally has the trigger feature as input. We conduct extensive experiments to demonstrate the effectiveness and practicality of our attacks. According to the experimental results, we conclude that our attacks seriously jeopardize the fairness and robustness of image classification models, and it is necessary to be vigilant about the incorrect labels in outsourced labeling.
On the Tip of the Tongue: Analyzing Conceptual Representation in Large Language Models with Reverse-Dictionary Probe
Feb 26, 2024Probing and enhancing large language models' reasoning capacity remains a crucial open question. Here we re-purpose the reverse dictionary task as a case study to probe LLMs' capacity for conceptual inference. We use in-context learning to guide the models to generate the term for an object concept implied in a linguistic description. Models robustly achieve high accuracy in this task, and their representation space encodes information about object categories and fine-grained features. Further experiments suggest that the conceptual inference ability as probed by the reverse-dictionary task predicts model's general reasoning performance across multiple benchmarks, despite similar syntactic generalization behaviors across models. Explorative analyses suggest that prompting LLMs with description$\Rightarrow$word examples may induce generalization beyond surface-level differences in task construals and facilitate models on broader commonsense reasoning problems.
Demystifying Bitcoin Address Behavior via Graph Neural Networks
Nov 26, 2022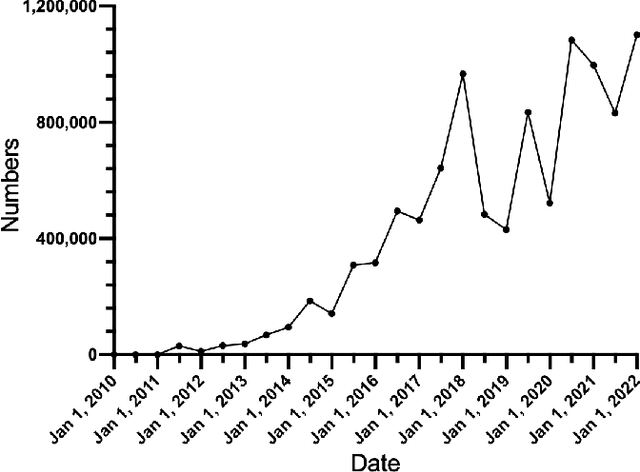

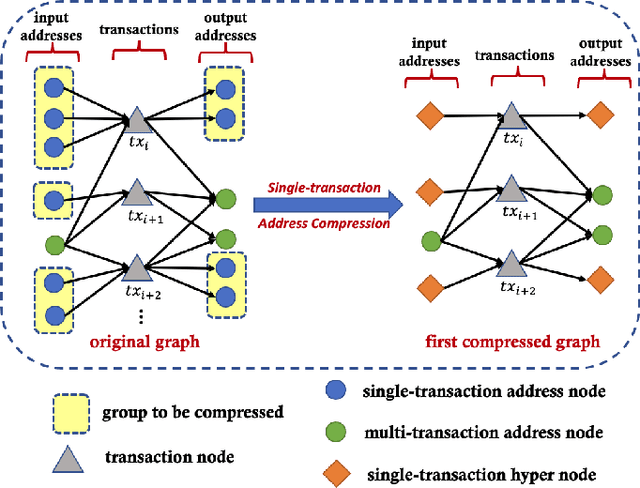

Bitcoin is one of the decentralized cryptocurrencies powered by a peer-to-peer blockchain network. Parties who trade in the bitcoin network are not required to disclose any personal information. Such property of anonymity, however, precipitates potential malicious transactions to a certain extent. Indeed, various illegal activities such as money laundering, dark network trading, and gambling in the bitcoin network are nothing new now. While a proliferation of work has been developed to identify malicious bitcoin transactions, the behavior analysis and classification of bitcoin addresses are largely overlooked by existing tools. In this paper, we propose BAClassifier, a tool that can automatically classify bitcoin addresses based on their behaviors. Technically, we come up with the following three key designs. First, we consider casting the transactions of the bitcoin address into an address graph structure, of which we introduce a graph node compression technique and a graph structure augmentation method to characterize a unified graph representation. Furthermore, we leverage a graph feature network to learn the graph representations of each address and generate the graph embeddings. Finally, we aggregate all graph embeddings of an address into the address-level representation, and engage in a classification model to give the address behavior classification. As a side contribution, we construct and release a large-scale annotated dataset that consists of over 2 million real-world bitcoin addresses and concerns 4 types of address behaviors. Experimental results demonstrate that our proposed framework outperforms state-of-the-art bitcoin address classifiers and existing classification models, where the precision and F1-score are 96% and 95%, respectively. Our implementation and dataset are released, hoping to inspire others.
When Does Syntax Mediate Neural Language Model Performance? Evidence from Dropout Probes
Apr 20, 2022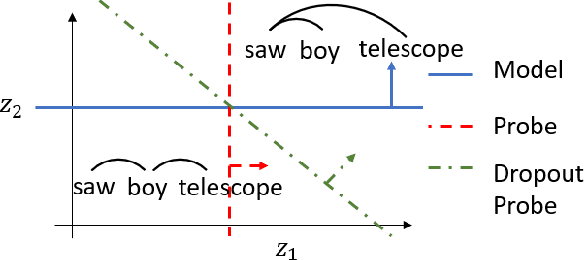
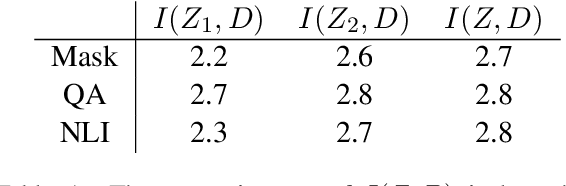
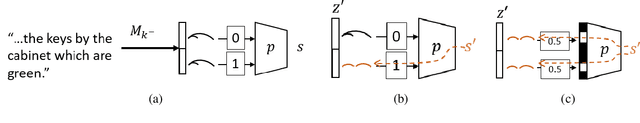

Recent causal probing literature reveals when language models and syntactic probes use similar representations. Such techniques may yield "false negative" causality results: models may use representations of syntax, but probes may have learned to use redundant encodings of the same syntactic information. We demonstrate that models do encode syntactic information redundantly and introduce a new probe design that guides probes to consider all syntactic information present in embeddings. Using these probes, we find evidence for the use of syntax in models where prior methods did not, allowing us to boost model performance by injecting syntactic information into representations.
Controlled Evaluation of Grammatical Knowledge in Mandarin Chinese Language Models
Sep 22, 2021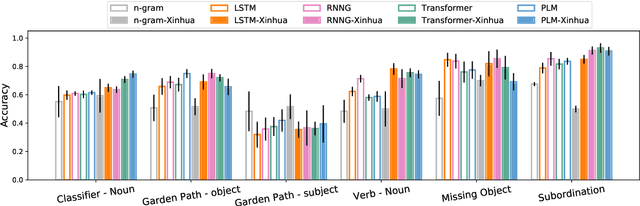
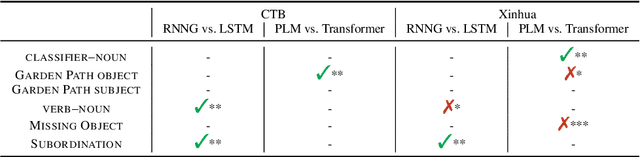
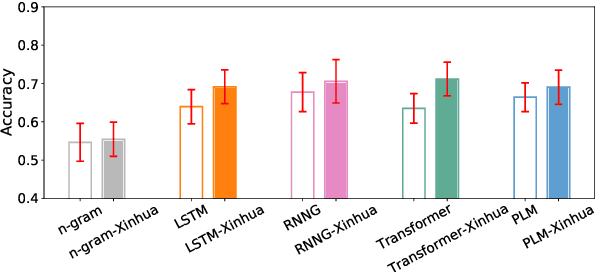
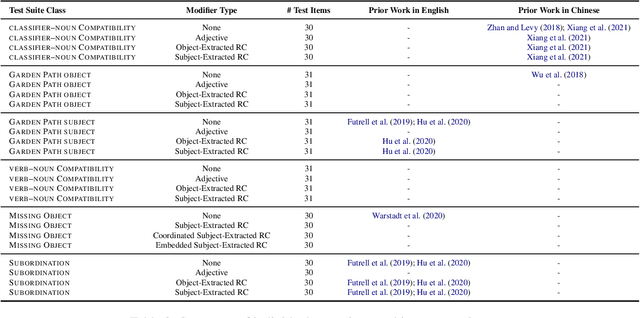
Prior work has shown that structural supervision helps English language models learn generalizations about syntactic phenomena such as subject-verb agreement. However, it remains unclear if such an inductive bias would also improve language models' ability to learn grammatical dependencies in typologically different languages. Here we investigate this question in Mandarin Chinese, which has a logographic, largely syllable-based writing system; different word order; and sparser morphology than English. We train LSTMs, Recurrent Neural Network Grammars, Transformer language models, and Transformer-parameterized generative parsing models on two Mandarin Chinese datasets of different sizes. We evaluate the models' ability to learn different aspects of Mandarin grammar that assess syntactic and semantic relationships. We find suggestive evidence that structural supervision helps with representing syntactic state across intervening content and improves performance in low-data settings, suggesting that the benefits of hierarchical inductive biases in acquiring dependency relationships may extend beyond English.
Structural Guidance for Transformer Language Models
Jul 30, 2021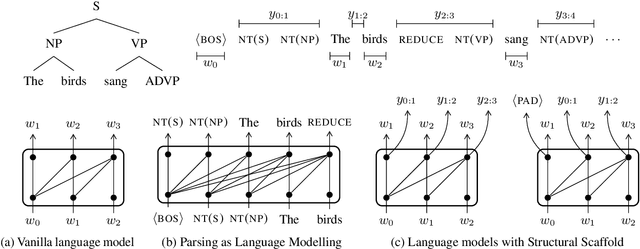
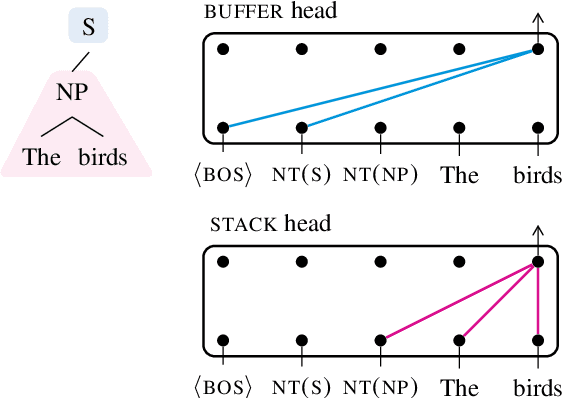
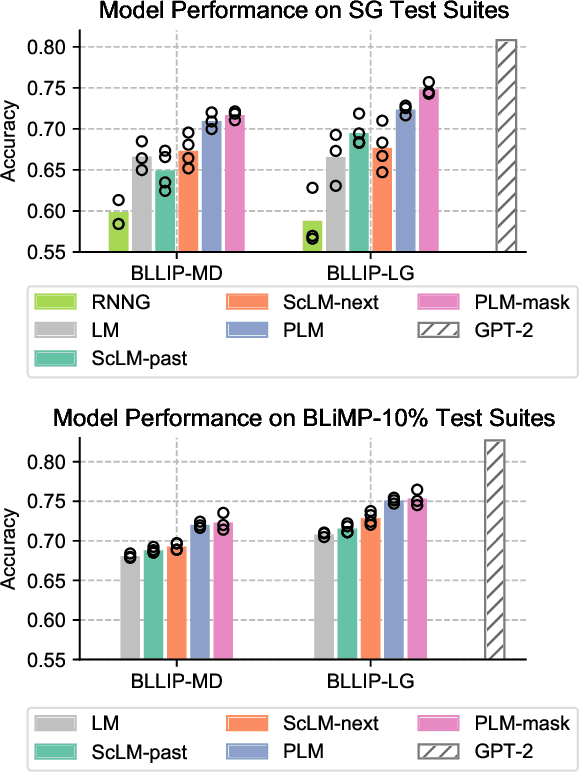
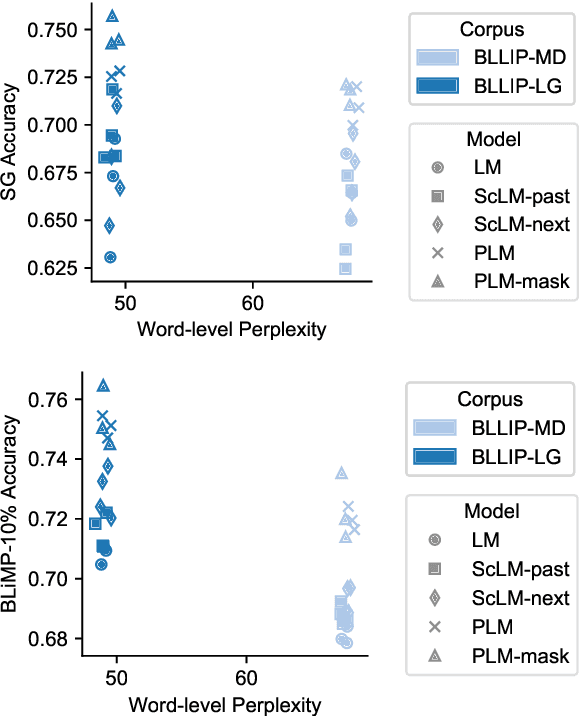
Transformer-based language models pre-trained on large amounts of text data have proven remarkably successful in learning generic transferable linguistic representations. Here we study whether structural guidance leads to more human-like systematic linguistic generalization in Transformer language models without resorting to pre-training on very large amounts of data. We explore two general ideas. The "Generative Parsing" idea jointly models the incremental parse and word sequence as part of the same sequence modeling task. The "Structural Scaffold" idea guides the language model's representation via additional structure loss that separately predicts the incremental constituency parse. We train the proposed models along with a vanilla Transformer language model baseline on a 14 million-token and a 46 million-token subset of the BLLIP dataset, and evaluate models' syntactic generalization performances on SG Test Suites and sized BLiMP. Experiment results across two benchmarks suggest converging evidence that generative structural supervisions can induce more robust and humanlike linguistic generalization in Transformer language models without the need for data intensive pre-training.
Combining Graph Neural Networks with Expert Knowledge for Smart Contract Vulnerability Detection
Jul 24, 2021
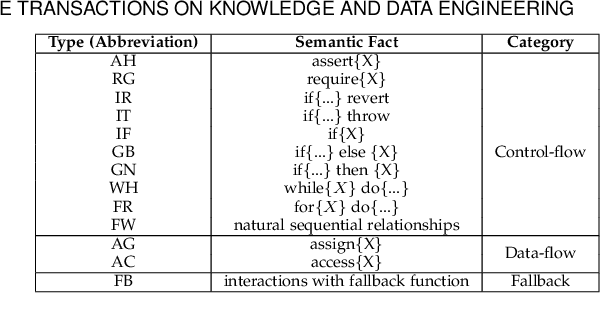

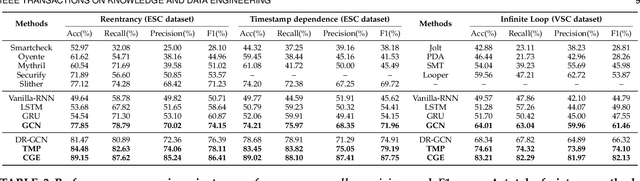
Smart contract vulnerability detection draws extensive attention in recent years due to the substantial losses caused by hacker attacks. Existing efforts for contract security analysis heavily rely on rigid rules defined by experts, which are labor-intensive and non-scalable. More importantly, expert-defined rules tend to be error-prone and suffer the inherent risk of being cheated by crafty attackers. Recent researches focus on the symbolic execution and formal analysis of smart contracts for vulnerability detection, yet to achieve a precise and scalable solution. Although several methods have been proposed to detect vulnerabilities in smart contracts, there is still a lack of effort that considers combining expert-defined security patterns with deep neural networks. In this paper, we explore using graph neural networks and expert knowledge for smart contract vulnerability detection. Specifically, we cast the rich control- and data- flow semantics of the source code into a contract graph. To highlight the critical nodes in the graph, we further design a node elimination phase to normalize the graph. Then, we propose a novel temporal message propagation network to extract the graph feature from the normalized graph, and combine the graph feature with designed expert patterns to yield a final detection system. Extensive experiments are conducted on all the smart contracts that have source code in Ethereum and VNT Chain platforms. Empirical results show significant accuracy improvements over the state-of-the-art methods on three types of vulnerabilities, where the detection accuracy of our method reaches 89.15%, 89.02%, and 83.21% for reentrancy, timestamp dependence, and infinite loop vulnerabilities, respectively.