 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
Human-Like Coarse Object Representations in Vision Models
Feb 12, 2026Humans appear to represent objects for intuitive physics with coarse, volumetric bodies'' that smooth concavities - trading fine visual details for efficient physical predictions - yet their internal structure is largely unknown. Segmentation models, in contrast, optimize pixel-accurate masks that may misalign with such bodies. We ask whether and when these models nonetheless acquire human-like bodies. Using a time-to-collision (TTC) behavioral paradigm, we introduce a comparison pipeline and alignment metric, then vary model training time, size, and effective capacity via pruning. Across all manipulations, alignment with human behavior follows an inverse U-shaped curve: small/briefly trained/pruned models under-segment into blobs; large/fully trained models over-segment with boundary wiggles; and an intermediate ideal body granularity'' best matches humans. This suggests human-like coarse bodies emerge from resource constraints rather than bespoke biases, and points to simple knobs - early checkpoints, modest architectures, light pruning - for eliciting physics-efficient representations. We situate these results within resource-rational accounts balancing recognition detail against physical affordances.
Inside you are many wolves: Using cognitive models to interpret value trade-offs in LLMs
Jun 25, 2025



Navigating everyday social situations often requires juggling conflicting goals, such as conveying a harsh truth, maintaining trust, all while still being mindful of another person's feelings. These value trade-offs are an integral part of human decision-making and language use, however, current tools for interpreting such dynamic and multi-faceted notions of values in LLMs are limited. In cognitive science, so-called "cognitive models" provide formal accounts of these trade-offs in humans, by modeling the weighting of a speaker's competing utility functions in choosing an action or utterance. In this work, we use a leading cognitive model of polite speech to interpret the extent to which LLMs represent human-like trade-offs. We apply this lens to systematically evaluate value trade-offs in two encompassing model settings: degrees of reasoning "effort" in frontier black-box models, and RL post-training dynamics of open-source models. Our results highlight patterns of higher informational utility than social utility in reasoning models, and in open-source models shown to be stronger in mathematical reasoning. Our findings from LLMs' training dynamics suggest large shifts in utility values early on in training with persistent effects of the choice of base model and pretraining data, compared to feedback dataset or alignment method. We show that our method is responsive to diverse aspects of the rapidly evolving LLM landscape, with insights for forming hypotheses about other high-level behaviors, shaping training regimes for reasoning models, and better controlling trade-offs between values during model training.
Re-evaluating Theory of Mind evaluation in large language models
Feb 28, 2025The question of whether large language models (LLMs) possess Theory of Mind (ToM) -- often defined as the ability to reason about others' mental states -- has sparked significant scientific and public interest. However, the evidence as to whether LLMs possess ToM is mixed, and the recent growth in evaluations has not resulted in a convergence. Here, we take inspiration from cognitive science to re-evaluate the state of ToM evaluation in LLMs. We argue that a major reason for the disagreement on whether LLMs have ToM is a lack of clarity on whether models should be expected to match human behaviors, or the computations underlying those behaviors. We also highlight ways in which current evaluations may be deviating from "pure" measurements of ToM abilities, which also contributes to the confusion. We conclude by discussing several directions for future research, including the relationship between ToM and pragmatic communication, which could advance our understanding of artificial systems as well as human cognition.
Shades of Zero: Distinguishing Impossibility from Inconceivability
Feb 27, 2025Some things are impossible, but some things may be even more impossible than impossible. Levitating a feather using one's mind is impossible in our world, but fits into our intuitive theories of possible worlds, whereas levitating a feather using the number five cannot be conceived in any possible world ("inconceivable"). While prior work has examined the distinction between improbable and impossible events, there has been little empirical research on inconceivability. Here, we investigate whether people maintain a distinction between impossibility and inconceivability, and how such distinctions might be made. We find that people can readily distinguish the impossible from the inconceivable, using categorization studies similar to those used to investigate the differences between impossible and improbable (Experiment 1). However, this distinction is not explained by people's subjective ratings of event likelihood, which are near zero and indistinguishable between impossible and inconceivable event descriptions (Experiment 2). Finally, we ask whether the probabilities assigned to event descriptions by statistical language models (LMs) can be used to separate modal categories, and whether these probabilities align with people's ratings (Experiment 3). We find high-level similarities between people and LMs: both distinguish among impossible and inconceivable event descriptions, and LM-derived string probabilities predict people's ratings of event likelihood across modal categories. Our findings suggest that fine-grained knowledge about exceedingly rare events (i.e., the impossible and inconceivable) may be learned via statistical learning over linguistic forms, yet leave open the question of whether people represent the distinction between impossible and inconceivable as a difference not of degree, but of kind.
Forking Paths in Neural Text Generation
Dec 10, 2024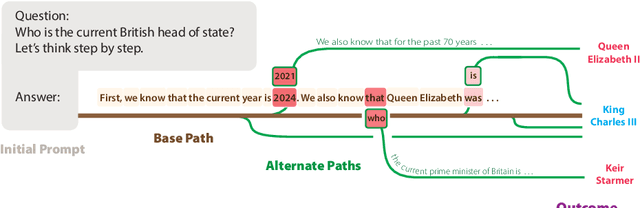
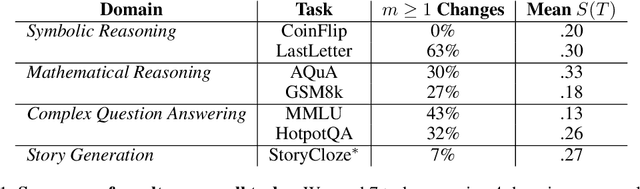
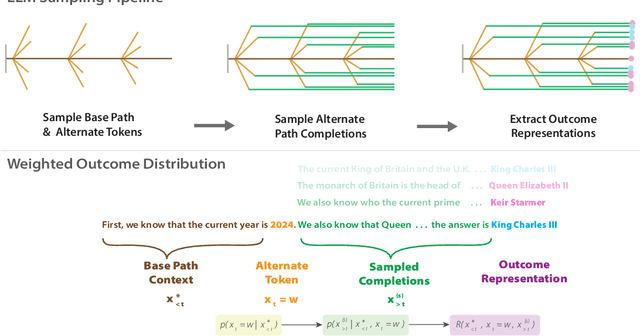
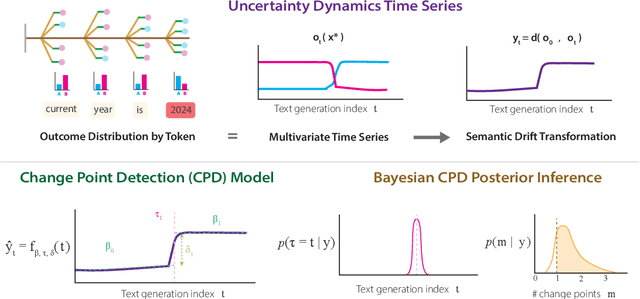
Estimating uncertainty in Large Language Models (LLMs) is important for properly evaluating LLMs, and ensuring safety for users. However, prior approaches to uncertainty estimation focus on the final answer in generated text, ignoring intermediate steps that might dramatically impact the outcome. We hypothesize that there exist key forking tokens, such that re-sampling the system at those specific tokens, but not others, leads to very different outcomes. To test this empirically, we develop a novel approach to representing uncertainty dynamics across individual tokens of text generation, and applying statistical models to test our hypothesis. Our approach is highly flexible: it can be applied to any dataset and any LLM, without fine tuning or accessing model weights. We use our method to analyze LLM responses on 7 different tasks across 4 domains, spanning a wide range of typical use cases. We find many examples of forking tokens, including surprising ones such as punctuation marks, suggesting that LLMs are often just a single token away from saying something very different.
Relations, Negations, and Numbers: Looking for Logic in Generative Text-to-Image Models
Nov 26, 2024



Despite remarkable progress in multi-modal AI research, there is a salient domain in which modern AI continues to lag considerably behind even human children: the reliable deployment of logical operators. Here, we examine three forms of logical operators: relations, negations, and discrete numbers. We asked human respondents (N=178 in total) to evaluate images generated by a state-of-the-art image-generating AI (DALL-E 3) prompted with these `logical probes', and find that none reliably produce human agreement scores greater than 50\%. The negation probes and numbers (beyond 3) fail most frequently. In a 4th experiment, we assess a `grounded diffusion' pipeline that leverages targeted prompt engineering and structured intermediate representations for greater compositional control, but find its performance is judged even worse than that of DALL-E 3 across prompts. To provide further clarity on potential sources of success and failure in these text-to-image systems, we supplement our 4 core experiments with multiple auxiliary analyses and schematic diagrams, directly quantifying, for example, the relationship between the N-gram frequency of relational prompts and the average match to generated images; the success rates for 3 different prompt modification strategies in the rendering of negation prompts; and the scalar variability / ratio dependence (`approximate numeracy') of prompts involving integers. We conclude by discussing the limitations inherent to `grounded' multimodal learning systems whose grounding relies heavily on vector-based semantics (e.g. DALL-E 3), or under-specified syntactical constraints (e.g. `grounded diffusion'), and propose minimal modifications (inspired by development, based in imagery) that could help to bridge the lingering compositional gap between scale and structure. All data and code is available at https://github.com/ColinConwell/T2I-Probology
One fish, two fish, but not the whole sea: Alignment reduces language models' conceptual diversity
Nov 07, 2024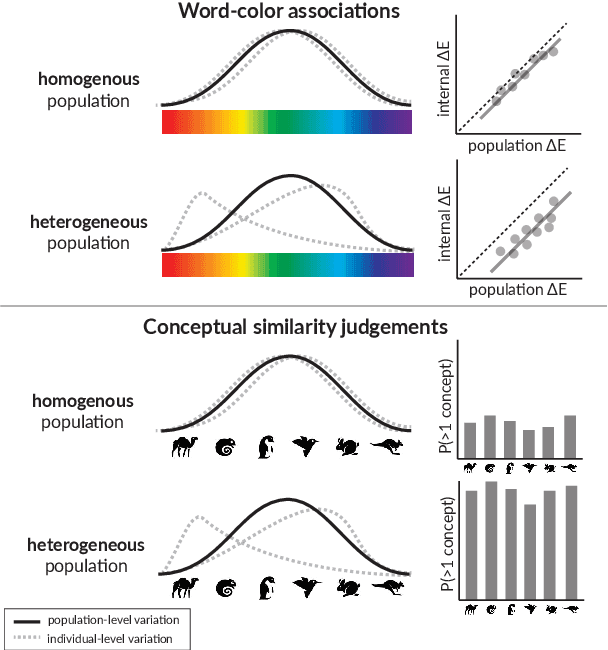
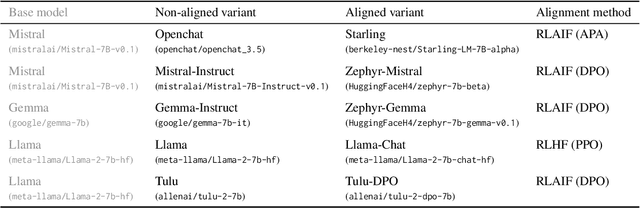
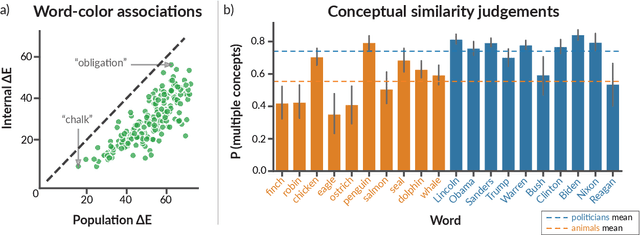
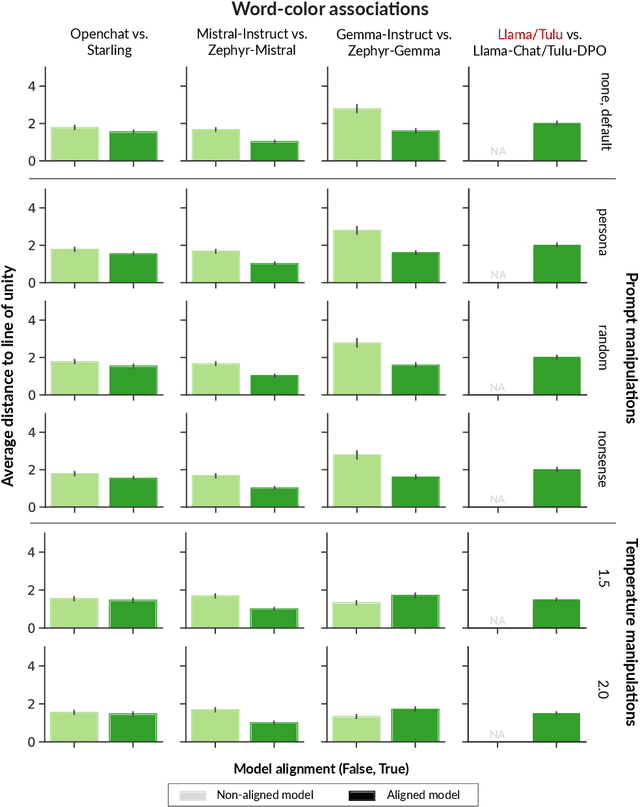
Researchers in social science and psychology have recently proposed using large language models (LLMs) as replacements for humans in behavioral research. In addition to arguments about whether LLMs accurately capture population-level patterns, this has raised questions about whether LLMs capture human-like conceptual diversity. Separately, it is debated whether post-training alignment (RLHF or RLAIF) affects models' internal diversity. Inspired by human studies, we use a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by relating the internal variability of simulated individuals to the population-level variability. We use this approach to evaluate non-aligned and aligned LLMs on two domains with rich human behavioral data. While no model reaches human-like diversity, aligned models generally display less diversity than their instruction fine-tuned counterparts. Our findings highlight potential trade-offs between increasing models' value alignment and decreasing the diversity of their conceptual representations.
MMToM-QA: Multimodal Theory of Mind Question Answering
Jan 16, 2024



Theory of Mind (ToM), the ability to understand people's minds, is an essential ingredient for developing machines with human-level social intelligence. Recent machine learning models, particularly large language models, seem to show some aspects of ToM understanding. However, existing ToM benchmarks use unimodal datasets - either video or text. Human ToM, on the other hand, is more than video or text understanding. People can flexibly reason about another person's mind based on conceptual representations (e.g., goals, beliefs, plans) extracted from any available data, which can include visual cues, linguistic narratives, or both. To address this, we introduce a multimodal Theory of Mind question answering (MMToM-QA) benchmark. MMToM-QA comprehensively evaluates machine ToM both on multimodal data and on different kinds of unimodal data about a person's activity in a household environment. To engineer multimodal ToM capacity, we propose a novel method, BIP-ALM (Bayesian Inverse Planning Accelerated by Language Models). BIP-ALM extracts unified representations from multimodal data and utilizes language models for scalable Bayesian inverse planning. We conducted a systematic comparison of human performance, BIP-ALM, and state-of-the-art models, including GPT-4. The experiments demonstrate that large language models and large multimodal models still lack robust ToM capacity. BIP-ALM, on the other hand, shows promising results, by leveraging the power of both model-based mental inference and language models.
Large Language Models Fail on Trivial Alterations to Theory-of-Mind Tasks
Feb 26, 2023

Intuitive psychology is a pillar of common-sense reasoning. The replication of this reasoning in machine intelligence is an important stepping-stone on the way to human-like artificial intelligence. Several recent tasks and benchmarks for examining this reasoning in Large-Large Models have focused in particular on belief attribution in Theory-of-Mind tasks. These tasks have shown both successes and failures. We consider in particular a recent purported success case, and show that small variations that maintain the principles of ToM turn the results on their head. We argue that in general, the zero-hypothesis for model evaluation in intuitive psychology should be skeptical, and that outlying failure cases should outweigh average success rates. We also consider what possible future successes on Theory-of-Mind tasks by more powerful LLMs would mean for ToM tasks with people.