 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne fish, two fish, but not the whole sea: Alignment reduces language models' conceptual diversity
Paper and Code
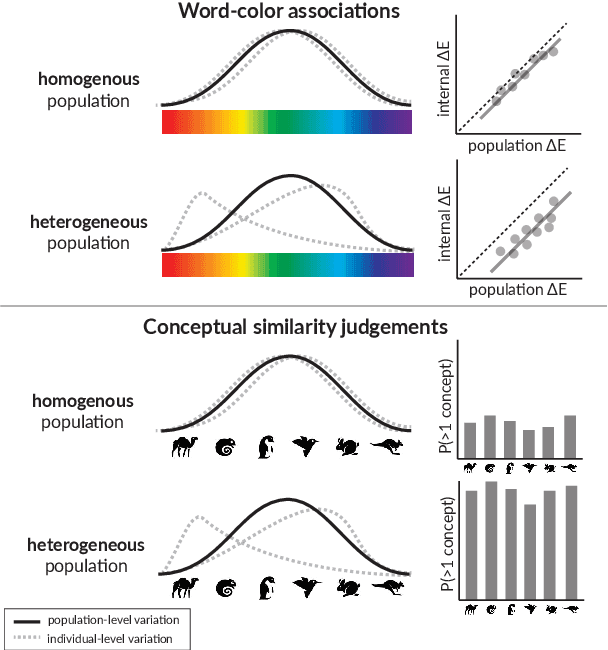
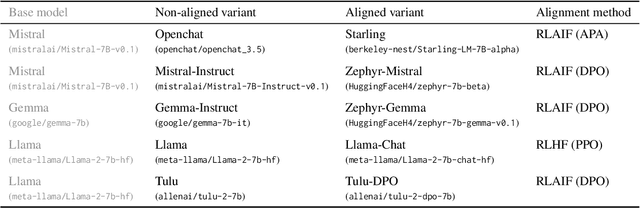
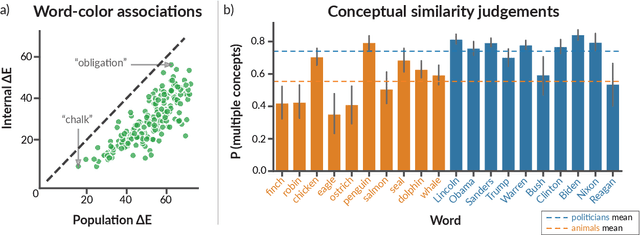
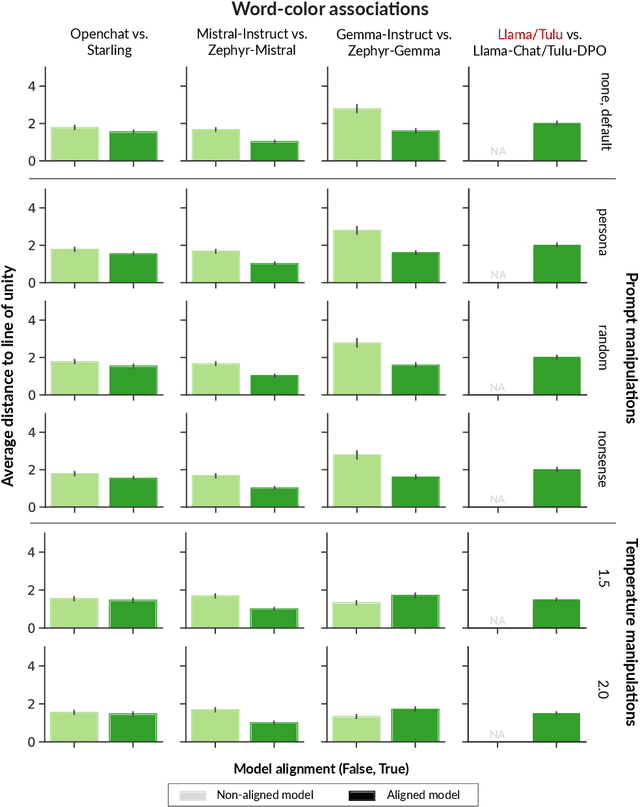
Researchers in social science and psychology have recently proposed using large language models (LLMs) as replacements for humans in behavioral research. In addition to arguments about whether LLMs accurately capture population-level patterns, this has raised questions about whether LLMs capture human-like conceptual diversity. Separately, it is debated whether post-training alignment (RLHF or RLAIF) affects models' internal diversity. Inspired by human studies, we use a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by relating the internal variability of simulated individuals to the population-level variability. We use this approach to evaluate non-aligned and aligned LLMs on two domains with rich human behavioral data. While no model reaches human-like diversity, aligned models generally display less diversity than their instruction fine-tuned counterparts. Our findings highlight potential trade-offs between increasing models' value alignment and decreasing the diversity of their conceptual representations.