 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInside you are many wolves: Using cognitive models to interpret value trade-offs in LLMs
Jun 25, 2025



Navigating everyday social situations often requires juggling conflicting goals, such as conveying a harsh truth, maintaining trust, all while still being mindful of another person's feelings. These value trade-offs are an integral part of human decision-making and language use, however, current tools for interpreting such dynamic and multi-faceted notions of values in LLMs are limited. In cognitive science, so-called "cognitive models" provide formal accounts of these trade-offs in humans, by modeling the weighting of a speaker's competing utility functions in choosing an action or utterance. In this work, we use a leading cognitive model of polite speech to interpret the extent to which LLMs represent human-like trade-offs. We apply this lens to systematically evaluate value trade-offs in two encompassing model settings: degrees of reasoning "effort" in frontier black-box models, and RL post-training dynamics of open-source models. Our results highlight patterns of higher informational utility than social utility in reasoning models, and in open-source models shown to be stronger in mathematical reasoning. Our findings from LLMs' training dynamics suggest large shifts in utility values early on in training with persistent effects of the choice of base model and pretraining data, compared to feedback dataset or alignment method. We show that our method is responsive to diverse aspects of the rapidly evolving LLM landscape, with insights for forming hypotheses about other high-level behaviors, shaping training regimes for reasoning models, and better controlling trade-offs between values during model training.
One fish, two fish, but not the whole sea: Alignment reduces language models' conceptual diversity
Nov 07, 2024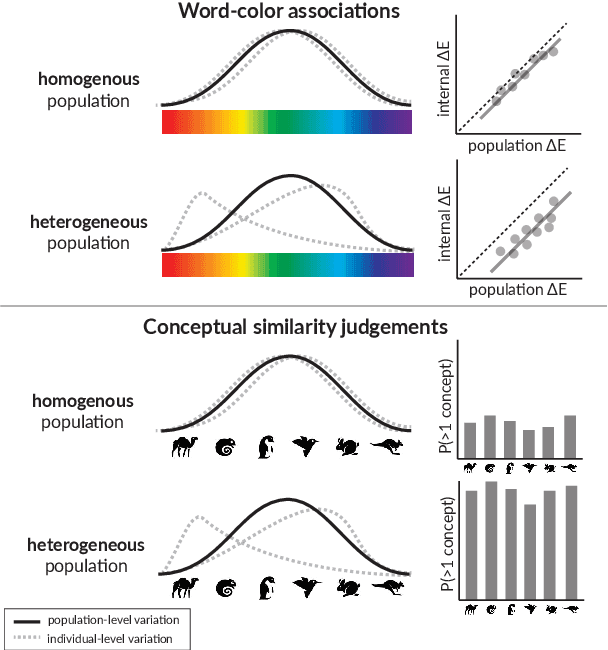
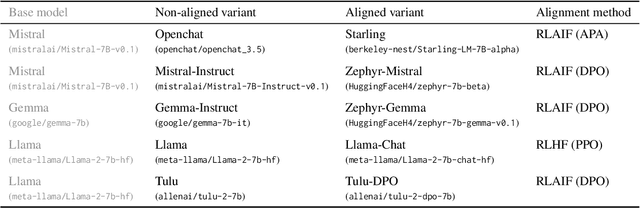
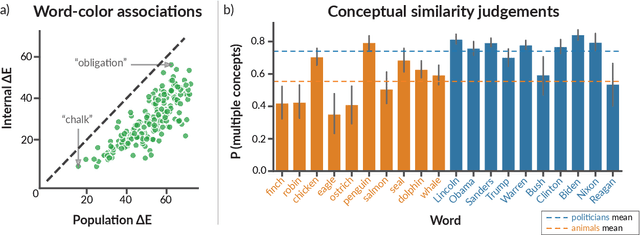
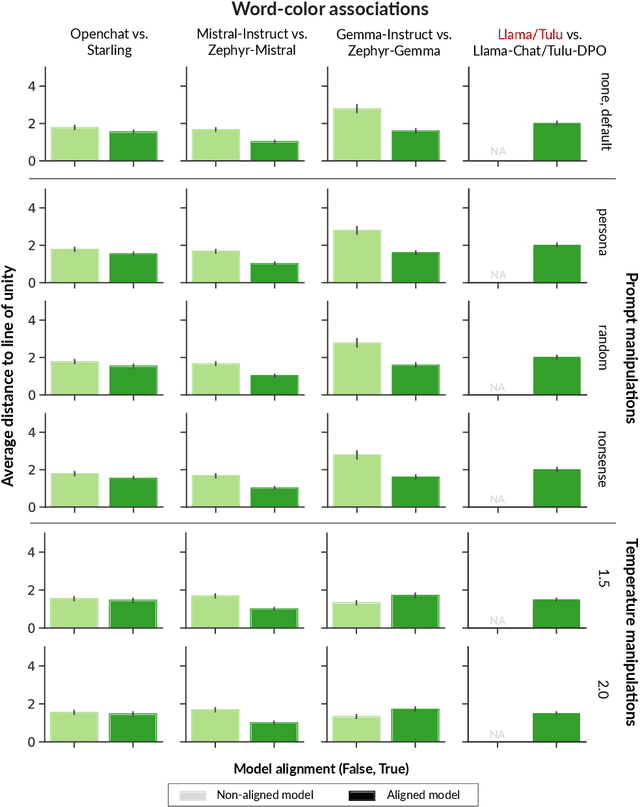
Researchers in social science and psychology have recently proposed using large language models (LLMs) as replacements for humans in behavioral research. In addition to arguments about whether LLMs accurately capture population-level patterns, this has raised questions about whether LLMs capture human-like conceptual diversity. Separately, it is debated whether post-training alignment (RLHF or RLAIF) affects models' internal diversity. Inspired by human studies, we use a new way of measuring the conceptual diversity of synthetically-generated LLM "populations" by relating the internal variability of simulated individuals to the population-level variability. We use this approach to evaluate non-aligned and aligned LLMs on two domains with rich human behavioral data. While no model reaches human-like diversity, aligned models generally display less diversity than their instruction fine-tuned counterparts. Our findings highlight potential trade-offs between increasing models' value alignment and decreasing the diversity of their conceptual representations.
ACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific Concepts
May 14, 2022


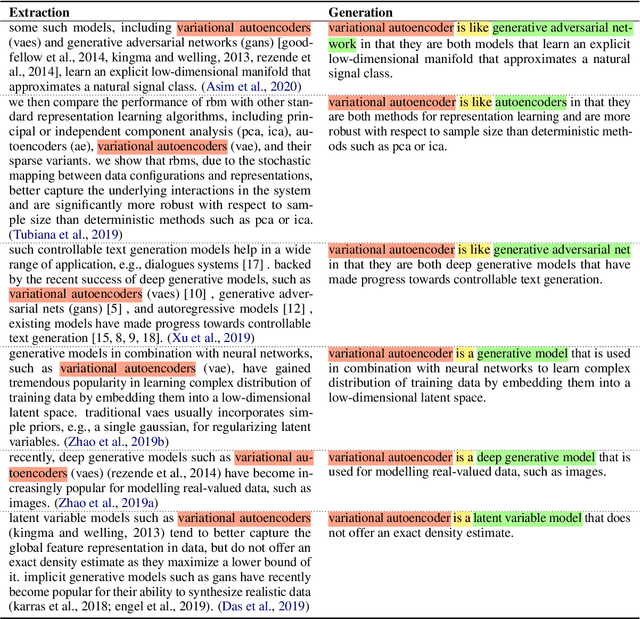
Systems that can automatically define unfamiliar terms hold the promise of improving the accessibility of scientific texts, especially for readers who may lack prerequisite background knowledge. However, current systems assume a single "best" description per concept, which fails to account for the many potentially useful ways a concept can be described. We present ACCoRD, an end-to-end system tackling the novel task of generating sets of descriptions of scientific concepts. Our system takes advantage of the myriad ways a concept is mentioned across the scientific literature to produce distinct, diverse descriptions of target scientific concepts in terms of different reference concepts. To support research on the task, we release an expert-annotated resource, the ACCoRD corpus, which includes 1,275 labeled contexts and 1,787 hand-authored concept descriptions. We conduct a user study demonstrating that (1) users prefer descriptions produced by our end-to-end system, and (2) users prefer multiple descriptions to a single "best" description.
Shades of confusion: Lexical uncertainty modulates ad hoc coordination in an interactive communication task
May 13, 2021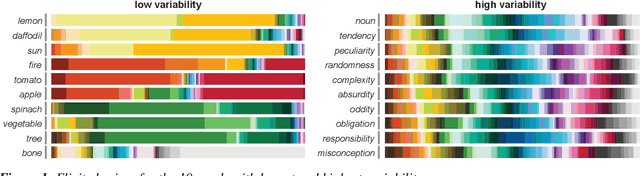
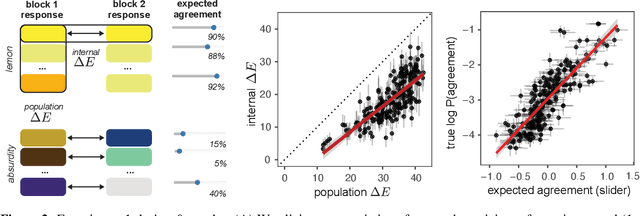
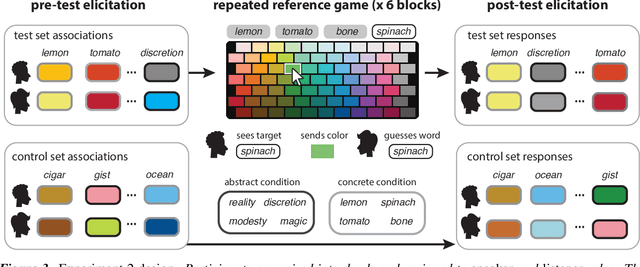
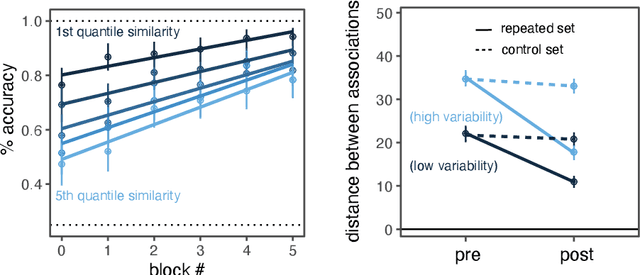
There is substantial variability in the expectations that communication partners bring into interactions, creating the potential for misunderstandings. To directly probe these gaps and our ability to overcome them, we propose a communication task based on color-concept associations. In Experiment 1, we establish several key properties of the mental representations of these expectations, or \emph{lexical priors}, based on recent probabilistic theories. Associations are more variable for abstract concepts, variability is represented as uncertainty within each individual, and uncertainty enables accurate predictions about whether others are likely to share the same association. In Experiment 2, we then examine the downstream consequences of these representations for communication. Accuracy is initially low when communicating about concepts with more variable associations, but rapidly increases as participants form ad hoc conventions. Together, our findings suggest that people cope with variability by maintaining well-calibrated uncertainty about their partner and appropriately adaptable representations of their own.