 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACCoRD: A Multi-Document Approach to Generating Diverse Descriptions of Scientific Concepts
May 14, 2022


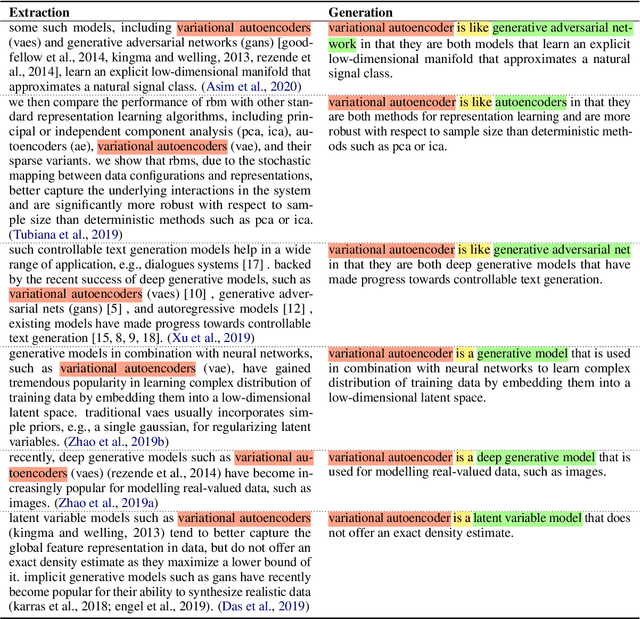
Systems that can automatically define unfamiliar terms hold the promise of improving the accessibility of scientific texts, especially for readers who may lack prerequisite background knowledge. However, current systems assume a single "best" description per concept, which fails to account for the many potentially useful ways a concept can be described. We present ACCoRD, an end-to-end system tackling the novel task of generating sets of descriptions of scientific concepts. Our system takes advantage of the myriad ways a concept is mentioned across the scientific literature to produce distinct, diverse descriptions of target scientific concepts in terms of different reference concepts. To support research on the task, we release an expert-annotated resource, the ACCoRD corpus, which includes 1,275 labeled contexts and 1,787 hand-authored concept descriptions. We conduct a user study demonstrating that (1) users prefer descriptions produced by our end-to-end system, and (2) users prefer multiple descriptions to a single "best" description.
SciSight: Combining faceted navigation and research group detection for COVID-19 exploratory scientific search
May 27, 2020

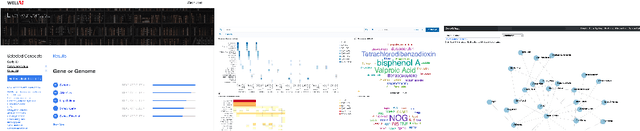
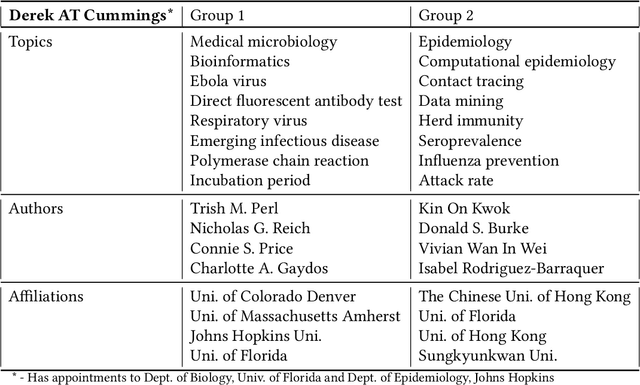
The COVID-19 pandemic has sparked unprecedented mobilization of scientists, already generating thousands of new papers that join a litany of previous biomedical work in related areas. This deluge of information makes it hard for researchers to keep track of their own research area, let alone explore new directions. Standard search engines are designed primarily for targeted search and are not geared for discovery or making connections that are not obvious from reading individual papers. In this paper, we present our ongoing work on SciSight, a novel framework for exploratory search of COVID-19 research. Based on formative interviews with scientists and a review of existing tools, we build and integrate two key capabilities: first, exploring interactions between biomedical facets (e.g., proteins, genes, drugs, diseases, patient characteristics); and second, discovering groups of researchers and how they are connected. We extract entities using a language model pre-trained on several biomedical information extraction tasks, and enrich them with data from the Microsoft Academic Graph (MAG). To find research groups automatically, we use hierarchical clustering with overlap to allow authors, as they do, to belong to multiple groups. Finally, we introduce a novel presentation of these groups based on both topical and social affinities, allowing users to drill down from groups to papers to associations between entities, and update query suggestions on the fly with the goal of facilitating exploratory navigation. SciSight has thus far served over 10K users with over 30K page views and 13% returning users. Preliminary user interviews with biomedical researchers suggest that SciSight complements current approaches and helps find new and relevant knowledge.