 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Literature-Driven Scientific Theories at Scale
Jan 22, 2026Contemporary automated scientific discovery has focused on agents for generating scientific experiments, while systems that perform higher-level scientific activities such as theory building remain underexplored. In this work, we formulate the problem of synthesizing theories consisting of qualitative and quantitative laws from large corpora of scientific literature. We study theory generation at scale, using 13.7k source papers to synthesize 2.9k theories, examining how generation using literature-grounding versus parametric knowledge, and accuracy-focused versus novelty-focused generation objectives change theory properties. Our experiments show that, compared to using parametric LLM memory for generation, our literature-supported method creates theories that are significantly better at both matching existing evidence and at predicting future results from 4.6k subsequently-written papers
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Ai2 Scholar QA: Organized Literature Synthesis with Attribution
Apr 15, 2025Retrieval-augmented generation is increasingly effective in answering scientific questions from literature, but many state-of-the-art systems are expensive and closed-source. We introduce Ai2 Scholar QA, a free online scientific question answering application. To facilitate research, we make our entire pipeline public: as a customizable open-source Python package and interactive web app, along with paper indexes accessible through public APIs and downloadable datasets. We describe our system in detail and present experiments analyzing its key design decisions. In an evaluation on a recent scientific QA benchmark, we find that Ai2 Scholar QA outperforms competing systems.
Cocoa: Co-Planning and Co-Execution with AI Agents
Dec 14, 2024



We present Cocoa, a system that implements a novel interaction design pattern -- interactive plans -- for users to collaborate with an AI agent on complex, multi-step tasks in a document editor. Cocoa harmonizes human and AI efforts and enables flexible delegation of agency through two actions: Co-planning (where users collaboratively compose a plan of action with the agent) and Co-execution (where users collaboratively execute plan steps with the agent). Using scientific research as a sample domain, we motivate the design of Cocoa through a formative study with 9 researchers while also drawing inspiration from the design of computational notebooks. We evaluate Cocoa through a user study with 16 researchers and find that when compared to a strong chat baseline, Cocoa improved agent steerability without sacrificing ease of use. A deeper investigation of the general utility of both systems uncovered insights into usage contexts where interactive plans may be more appropriate than chat, and vice versa. Our work surfaces numerous practical implications and paves new paths for interactive interfaces that foster more effective collaboration between humans and agentic AI systems.
ArxivDIGESTables: Synthesizing Scientific Literature into Tables using Language Models
Oct 25, 2024

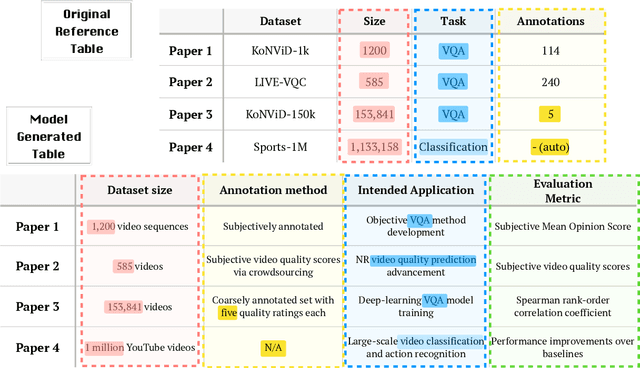
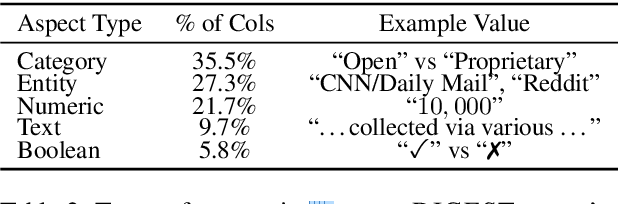
When conducting literature reviews, scientists often create literature review tables - tables whose rows are publications and whose columns constitute a schema, a set of aspects used to compare and contrast the papers. Can we automatically generate these tables using language models (LMs)? In this work, we introduce a framework that leverages LMs to perform this task by decomposing it into separate schema and value generation steps. To enable experimentation, we address two main challenges: First, we overcome a lack of high-quality datasets to benchmark table generation by curating and releasing arxivDIGESTables, a new dataset of 2,228 literature review tables extracted from ArXiv papers that synthesize a total of 7,542 research papers. Second, to support scalable evaluation of model generations against human-authored reference tables, we develop DecontextEval, an automatic evaluation method that aligns elements of tables with the same underlying aspects despite differing surface forms. Given these tools, we evaluate LMs' abilities to reconstruct reference tables, finding this task benefits from additional context to ground the generation (e.g. table captions, in-text references). Finally, through a human evaluation study we find that even when LMs fail to fully reconstruct a reference table, their generated novel aspects can still be useful.
Scideator: Human-LLM Scientific Idea Generation Grounded in Research-Paper Facet Recombination
Sep 23, 2024



The scientific ideation process often involves blending salient aspects of existing papers to create new ideas. To see if large language models (LLMs) can assist this process, we contribute Scideator, a novel mixed-initiative tool for scientific ideation. Starting from a user-provided set of papers, Scideator extracts key facets (purposes, mechanisms, and evaluations) from these and relevant papers, allowing users to explore the idea space by interactively recombining facets to synthesize inventive ideas. Scideator also helps users to gauge idea novelty by searching the literature for potential overlaps and showing automated novelty assessments and explanations. To support these tasks, Scideator introduces four LLM-powered retrieval-augmented generation (RAG) modules: Analogous Paper Facet Finder, Faceted Idea Generator, Idea Novelty Checker, and Idea Novelty Iterator. In a within-subjects user study, 19 computer-science researchers identified significantly more interesting ideas using Scideator compared to a strong baseline combining a scientific search engine with LLM interaction.
Designing LLM Chains by Adapting Techniques from Crowdsourcing Workflows
Dec 20, 2023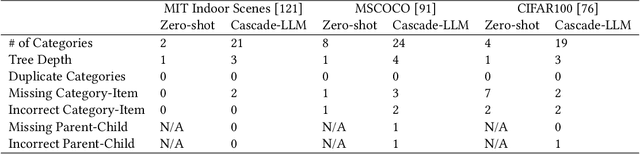


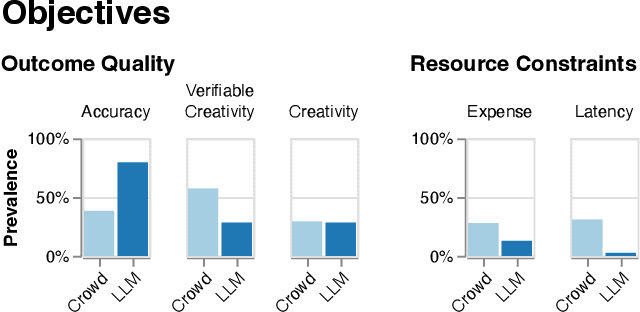
LLM chains enable complex tasks by decomposing work into a sequence of sub-tasks. Crowdsourcing workflows similarly decompose complex tasks into smaller tasks for human crowdworkers. Chains address LLM errors analogously to the way crowdsourcing workflows address human error. To characterize opportunities for LLM chaining, we survey 107 papers across the crowdsourcing and chaining literature to construct a design space for chain development. The design space connects an LLM designer's objectives to strategies they can use to achieve those objectives, and tactics to implement each strategy. To explore how techniques from crowdsourcing may apply to chaining, we adapt crowdsourcing workflows to implement LLM chains across three case studies: creating a taxonomy, shortening text, and writing a short story. From the design space and our case studies, we identify which techniques transfer from crowdsourcing to LLM chaining and raise implications for future research and development.
In Search of Verifiability: Explanations Rarely Enable Complementary Performance in AI-Advised Decision Making
May 16, 2023The current literature on AI-advised decision making -- involving explainable AI systems advising human decision makers -- presents a series of inconclusive and confounding results. To synthesize these findings, we propose a simple theory that elucidates the frequent failure of AI explanations to engender appropriate reliance and complementary decision making performance. We argue explanations are only useful to the extent that they allow a human decision maker to verify the correctness of an AI's prediction, in contrast to other desiderata, e.g., interpretability or spelling out the AI's reasoning process. Prior studies find in many decision making contexts AI explanations do not facilitate such verification. Moreover, most contexts fundamentally do not allow verification, regardless of explanation method. We conclude with a discussion of potential approaches for more effective explainable AI-advised decision making and human-AI collaboration.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
An Interactive UI to Support Sensemaking over Collections of Parallel Texts
Mar 11, 2023



Scientists and science journalists, among others, often need to make sense of a large number of papers and how they compare with each other in scope, focus, findings, or any other important factors. However, with a large corpus of papers, it's cognitively demanding to pairwise compare and contrast them all with each other. Fully automating this review process would be infeasible, because it often requires domain-specific knowledge, as well as understanding what the context and motivations for the review are. While there are existing tools to help with the process of organizing and annotating papers for literature reviews, at the core they still rely on people to serially read through papers and manually make sense of relevant information. We present AVTALER, which combines peoples' unique skills, contextual awareness, and knowledge, together with the strength of automation. Given a set of comparable text excerpts from a paper corpus, it supports users in sensemaking and contrasting paper attributes by interactively aligning text excerpts in a table so that comparable details are presented in a shared column. AVTALER is based on a core alignment algorithm that makes use of modern NLP tools. Furthermore, AVTALER is a mixed-initiative system: users can interactively give the system constraints which are integrated into the alignment construction process.