 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLADE: Benchmarking Language Model Agents for Data-Driven Science
Aug 20, 2024Data-driven scientific discovery requires the iterative integration of scientific domain knowledge, statistical expertise, and an understanding of data semantics to make nuanced analytical decisions, e.g., about which variables, transformations, and statistical models to consider. LM-based agents equipped with planning, memory, and code execution capabilities have the potential to support data-driven science. However, evaluating agents on such open-ended tasks is challenging due to multiple valid approaches, partially correct steps, and different ways to express the same decisions. To address these challenges, we present BLADE, a benchmark to automatically evaluate agents' multifaceted approaches to open-ended research questions. BLADE consists of 12 datasets and research questions drawn from existing scientific literature, with ground truth collected from independent analyses by expert data scientists and researchers. To automatically evaluate agent responses, we developed corresponding computational methods to match different representations of analyses to this ground truth. Though language models possess considerable world knowledge, our evaluation shows that they are often limited to basic analyses. However, agents capable of interacting with the underlying data demonstrate improved, but still non-optimal, diversity in their analytical decision making. Our work enables the evaluation of agents for data-driven science and provides researchers deeper insights into agents' analysis approaches.
Concept Induction: Analyzing Unstructured Text with High-Level Concepts Using LLooM
Apr 18, 2024
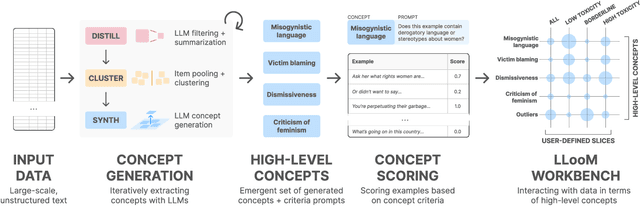


Data analysts have long sought to turn unstructured text data into meaningful concepts. Though common, topic modeling and clustering focus on lower-level keywords and require significant interpretative work. We introduce concept induction, a computational process that instead produces high-level concepts, defined by explicit inclusion criteria, from unstructured text. For a dataset of toxic online comments, where a state-of-the-art BERTopic model outputs "women, power, female," concept induction produces high-level concepts such as "Criticism of traditional gender roles" and "Dismissal of women's concerns." We present LLooM, a concept induction algorithm that leverages large language models to iteratively synthesize sampled text and propose human-interpretable concepts of increasing generality. We then instantiate LLooM in a mixed-initiative text analysis tool, enabling analysts to shift their attention from interpreting topics to engaging in theory-driven analysis. Through technical evaluations and four analysis scenarios ranging from literature review to content moderation, we find that LLooM's concepts improve upon the prior art of topic models in terms of quality and data coverage. In expert case studies, LLooM helped researchers to uncover new insights even from familiar datasets, for example by suggesting a previously unnoticed concept of attacks on out-party stances in a political social media dataset.
Designing LLM Chains by Adapting Techniques from Crowdsourcing Workflows
Dec 20, 2023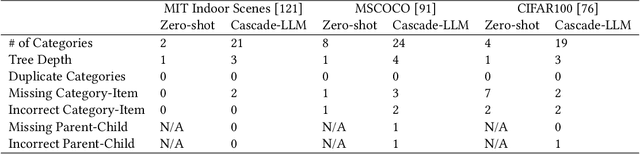


LLM chains enable complex tasks by decomposing work into a sequence of sub-tasks. Crowdsourcing workflows similarly decompose complex tasks into smaller tasks for human crowdworkers. Chains address LLM errors analogously to the way crowdsourcing workflows address human error. To characterize opportunities for LLM chaining, we survey 107 papers across the crowdsourcing and chaining literature to construct a design space for chain development. The design space connects an LLM designer's objectives to strategies they can use to achieve those objectives, and tactics to implement each strategy. To explore how techniques from crowdsourcing may apply to chaining, we adapt crowdsourcing workflows to implement LLM chains across three case studies: creating a taxonomy, shortening text, and writing a short story. From the design space and our case studies, we identify which techniques transfer from crowdsourcing to LLM chaining and raise implications for future research and development.
rTisane: Externalizing conceptual models for data analysis increases engagement with domain knowledge and improves statistical model quality
Oct 25, 2023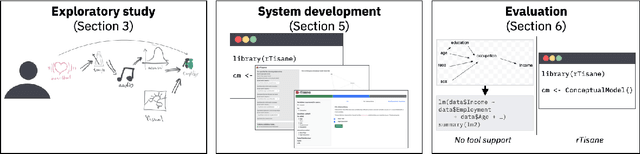
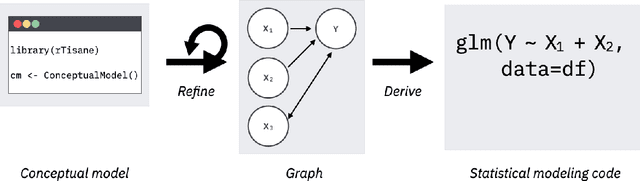
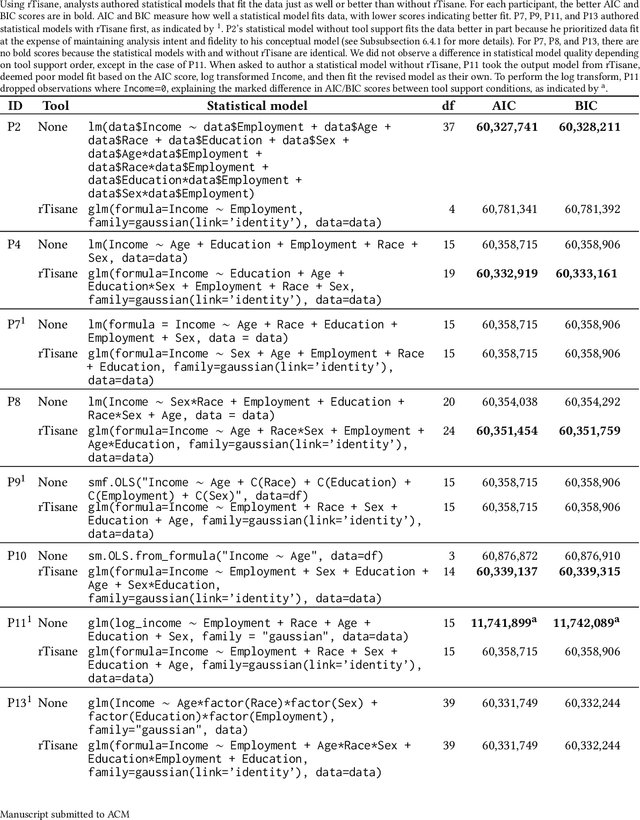
Statistical models should accurately reflect analysts' domain knowledge about variables and their relationships. While recent tools let analysts express these assumptions and use them to produce a resulting statistical model, it remains unclear what analysts want to express and how externalization impacts statistical model quality. This paper addresses these gaps. We first conduct an exploratory study of analysts using a domain-specific language (DSL) to express conceptual models. We observe a preference for detailing how variables relate and a desire to allow, and then later resolve, ambiguity in their conceptual models. We leverage these findings to develop rTisane, a DSL for expressing conceptual models augmented with an interactive disambiguation process. In a controlled evaluation, we find that rTisane's DSL helps analysts engage more deeply with and accurately externalize their assumptions. rTisane also leads to statistical models that match analysts' assumptions, maintain analysis intent, and better fit the data.
ScatterShot: Interactive In-context Example Curation for Text Transformation
Feb 14, 2023



The in-context learning capabilities of LLMs like GPT-3 allow annotators to customize an LLM to their specific tasks with a small number of examples. However, users tend to include only the most obvious patterns when crafting examples, resulting in underspecified in-context functions that fall short on unseen cases. Further, it is hard to know when "enough" examples have been included even for known patterns. In this work, we present ScatterShot, an interactive system for building high-quality demonstration sets for in-context learning. ScatterShot iteratively slices unlabeled data into task-specific patterns, samples informative inputs from underexplored or not-yet-saturated slices in an active learning manner, and helps users label more efficiently with the help of an LLM and the current example set. In simulation studies on two text perturbation scenarios, ScatterShot sampling improves the resulting few-shot functions by 4-5 percentage points over random sampling, with less variance as more examples are added. In a user study, ScatterShot greatly helps users in covering different patterns in the input space and labeling in-context examples more efficiently, resulting in better in-context learning and less user effort.
Tisane: Authoring Statistical Models via Formal Reasoning from Conceptual and Data Relationships
Jan 07, 2022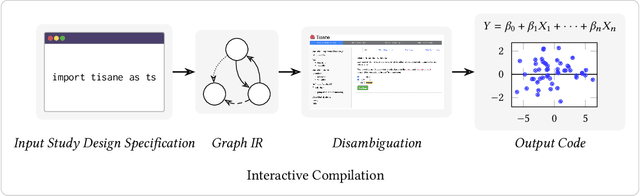
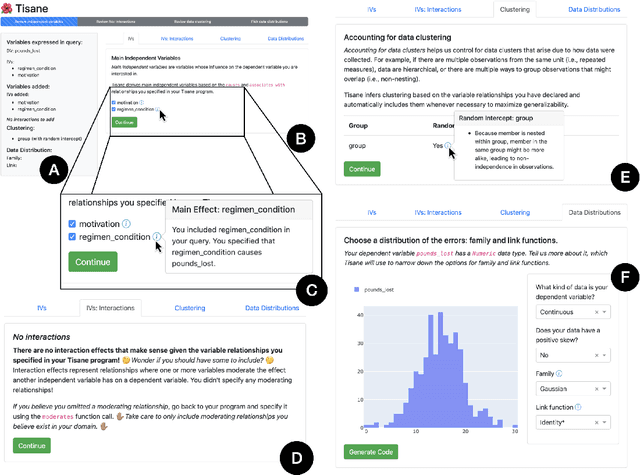
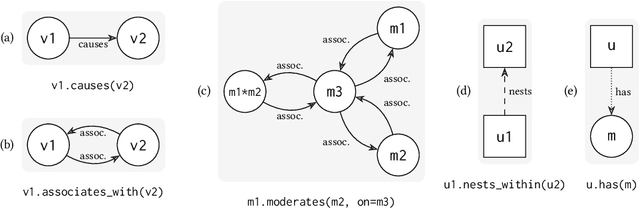
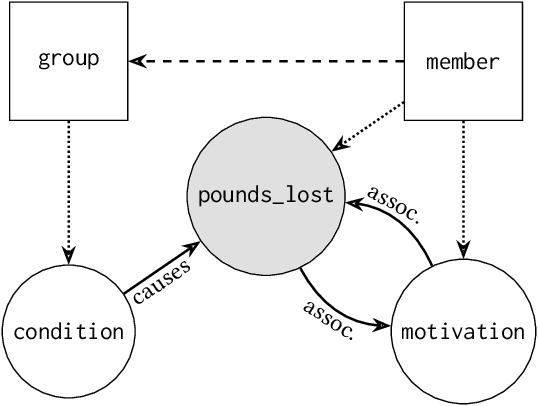
Proper statistical modeling incorporates domain theory about how concepts relate and details of how data were measured. However, data analysts currently lack tool support for recording and reasoning about domain assumptions, data collection, and modeling choices in an integrated manner, leading to mistakes that can compromise scientific validity. For instance, generalized linear mixed-effects models (GLMMs) help answer complex research questions, but omitting random effects impairs the generalizability of results. To address this need, we present Tisane, a mixed-initiative system for authoring generalized linear models with and without mixed-effects. Tisane introduces a study design specification language for expressing and asking questions about relationships between variables. Tisane contributes an interactive compilation process that represents relationships in a graph, infers candidate statistical models, and asks follow-up questions to disambiguate user queries to construct a valid model. In case studies with three researchers, we find that Tisane helps them focus on their goals and assumptions while avoiding past mistakes.
Polyjuice: Automated, General-purpose Counterfactual Generation
Jan 01, 2021

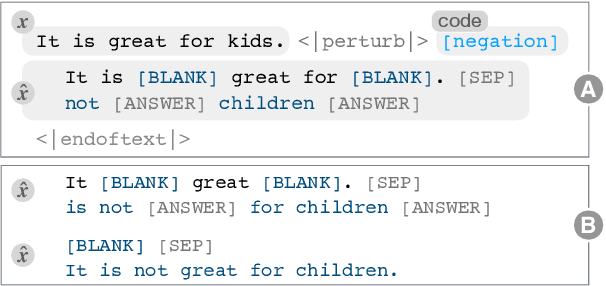

Counterfactual examples have been shown to be useful for many applications, including calibrating, evaluating, and explaining model decision boundaries. However, previous methods for generating such counterfactual examples have been tightly tailored to a specific application, used a limited range of linguistic patterns, or are hard to scale. We propose to disentangle counterfactual generation from its use cases, i.e., gather general-purpose counterfactuals first, and then select them for specific applications. We frame the automated counterfactual generation as text generation, and finetune GPT-2 into a generator, Polyjuice, which produces fluent and diverse counterfactuals. Our method also allows control over where perturbations happen and what they do. We show Polyjuice supports multiple use cases: by generating diverse counterfactuals for humans to label, Polyjuice helps produce high-quality datasets for model training and evaluation, requiring 40% less human effort. When used to generate explanations, Polyjuice helps augment feature attribution methods to reveal models' erroneous behaviors.
CORAL: COde RepresentAtion Learning with Weakly-Supervised Transformers for Analyzing Data Analysis
Aug 28, 2020
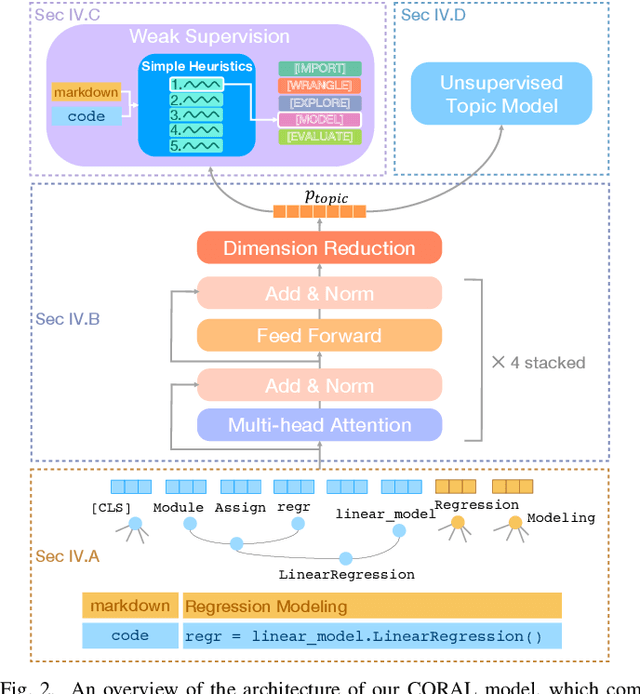
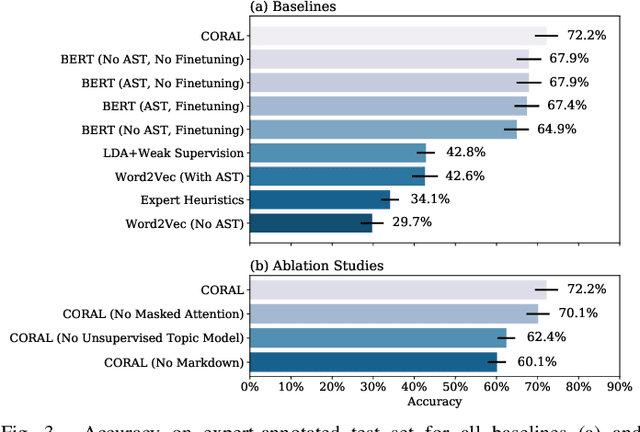

Large scale analysis of source code, and in particular scientific source code, holds the promise of better understanding the data science process, identifying analytical best practices, and providing insights to the builders of scientific toolkits. However, large corpora have remained unanalyzed in depth, as descriptive labels are absent and require expert domain knowledge to generate. We propose a novel weakly supervised transformer-based architecture for computing joint representations of code from both abstract syntax trees and surrounding natural language comments. We then evaluate the model on a new classification task for labeling computational notebook cells as stages in the data analysis process from data import to wrangling, exploration, modeling, and evaluation. We show that our model, leveraging only easily-available weak supervision, achieves a 38% increase in accuracy over expert-supplied heuristics and outperforms a suite of baselines. Our model enables us to examine a set of 118,000 Jupyter Notebooks to uncover common data analysis patterns. Focusing on notebooks with relationships to academic articles, we conduct the largest ever study of scientific code and find that notebook composition correlates with the citation count of corresponding papers.