 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolver-Aided Verification of Policy Compliance in Tool-Augmented LLM Agents
Mar 20, 2026Tool-augmented Large Language Models (TaLLMs) extend LLMs with the ability to invoke external tools, enabling them to interact with real-world environments. However, a major limitation in deploying TaLLMs in sensitive applications such as customer service and business process automation is a lack of reliable compliance with domain-specific operational policies regarding tool-use and agent behavior. Current approaches merely steer LLMs to adhere to policies by including policy descriptions in the LLM context, but these provide no guarantees that policy violations will be prevented. In this paper, we introduce an SMT solver-aided framework to enforce tool-use policy compliance in TaLLM agents. Specifically, we use an LLM-assisted, human-guided approach to translate natural-language-specified tool-use policies into formal logic (SMT-LIB-2.0) constraints over agent-observable state and tool arguments. At runtime, planned tool calls are intercepted and checked against the constraints using the Z3 solver as a pre-condition to the tool call. Tool invocations that violate the policy are blocked. We evaluated on the TauBench benchmark and demonstrate that solver-aided policy checking reduces policy violations while maintaining overall task accuracy. These results suggest that integrating formal reasoning into TaLLM execution can improve tool-call policy compliance and overall reliability.
Morello: Compiling Fast Neural Networks with Dynamic Programming and Spatial Compression
May 03, 2025

High-throughput neural network inference requires coordinating many optimization decisions, including parallel tiling, microkernel selection, and data layout. The product of these decisions forms a search space of programs which is typically intractably large. Existing approaches (e.g., auto-schedulers) often address this problem by sampling this space heuristically. In contrast, we introduce a dynamic-programming-based approach to explore more of the search space by iteratively decomposing large program specifications into smaller specifications reachable from a set of rewrites, then composing a final program from each rewrite that minimizes an affine cost model. To reduce memory requirements, we employ a novel memoization table representation, which indexes specifications by coordinates in $Z_{\geq 0}$ and compresses identical, adjacent solutions. This approach can visit a much larger set of programs than prior work. To evaluate the approach, we developed Morello, a compiler which lowers specifications roughly equivalent to a few-node XLA computation graph to x86. Notably, we found that an affine cost model is sufficient to surface high-throughput programs. For example, Morello synthesized a collection of matrix multiplication benchmarks targeting a Zen 1 CPU, including a 1x2048x16384, bfloat16-to-float32 vector-matrix multiply, which was integrated into Google's gemma.cpp.
AI-Assisted Assessment of Coding Practices in Modern Code Review
May 22, 2024



Modern code review is a process in which an incremental code contribution made by a code author is reviewed by one or more peers before it is committed to the version control system. An important element of modern code review is verifying that code contributions adhere to best practices. While some of these best practices can be automatically verified, verifying others is commonly left to human reviewers. This paper reports on the development, deployment, and evaluation of AutoCommenter, a system backed by a large language model that automatically learns and enforces coding best practices. We implemented AutoCommenter for four programming languages (C++, Java, Python, and Go) and evaluated its performance and adoption in a large industrial setting. Our evaluation shows that an end-to-end system for learning and enforcing coding best practices is feasible and has a positive impact on the developer workflow. Additionally, this paper reports on the challenges associated with deploying such a system to tens of thousands of developers and the corresponding lessons learned.
BLIP: Facilitating the Exploration of Undesirable Consequences of Digital Technologies
May 10, 2024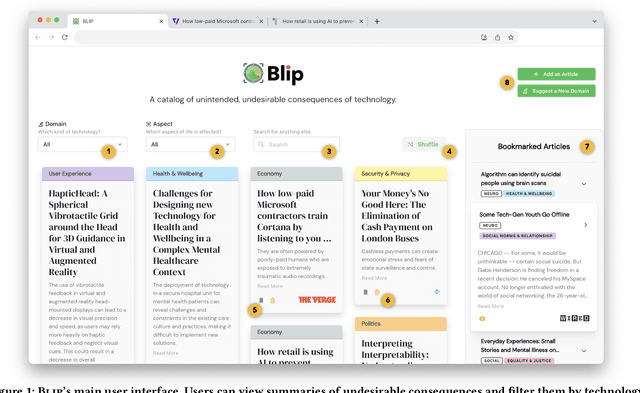
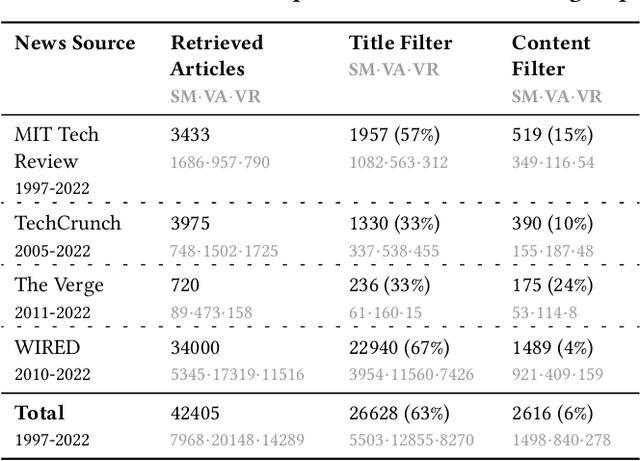
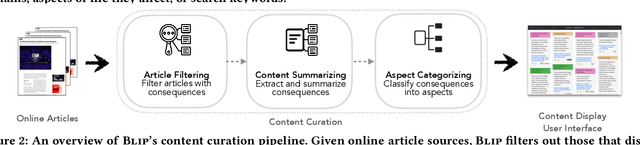
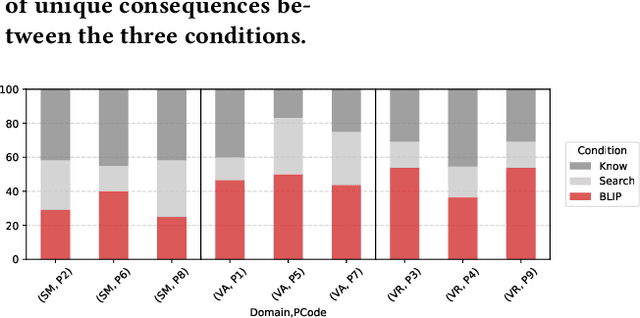
Digital technologies have positively transformed society, but they have also led to undesirable consequences not anticipated at the time of design or development. We posit that insights into past undesirable consequences can help researchers and practitioners gain awareness and anticipate potential adverse effects. To test this assumption, we introduce BLIP, a system that extracts real-world undesirable consequences of technology from online articles, summarizes and categorizes them, and presents them in an interactive, web-based interface. In two user studies with 15 researchers in various computer science disciplines, we found that BLIP substantially increased the number and diversity of undesirable consequences they could list in comparison to relying on prior knowledge or searching online. Moreover, BLIP helped them identify undesirable consequences relevant to their ongoing projects, made them aware of undesirable consequences they "had never considered," and inspired them to reflect on their own experiences with technology.
rTisane: Externalizing conceptual models for data analysis increases engagement with domain knowledge and improves statistical model quality
Oct 25, 2023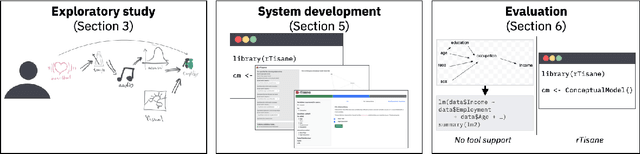
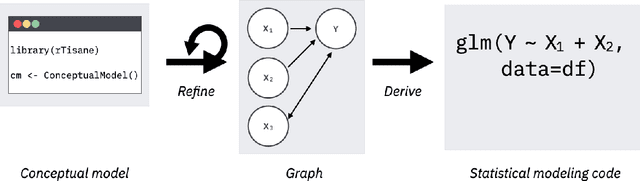
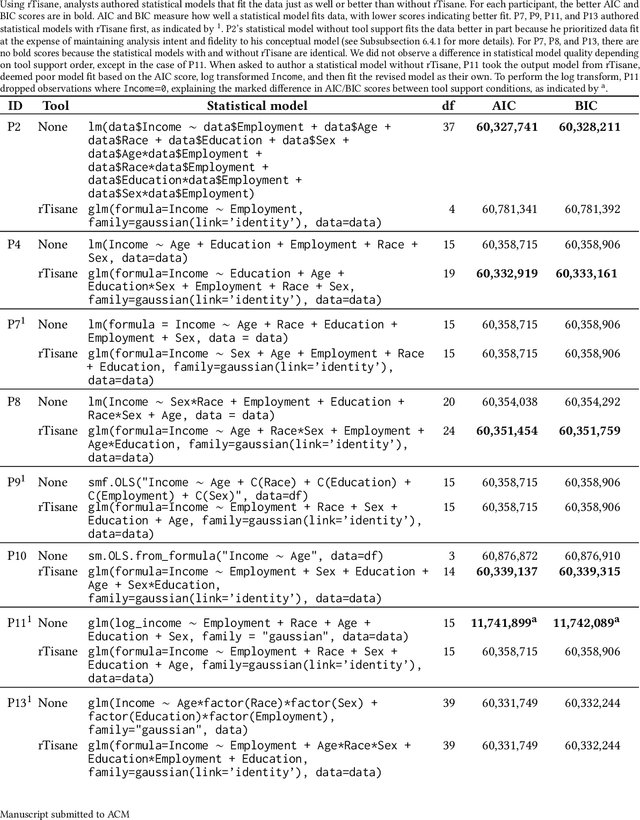
Statistical models should accurately reflect analysts' domain knowledge about variables and their relationships. While recent tools let analysts express these assumptions and use them to produce a resulting statistical model, it remains unclear what analysts want to express and how externalization impacts statistical model quality. This paper addresses these gaps. We first conduct an exploratory study of analysts using a domain-specific language (DSL) to express conceptual models. We observe a preference for detailing how variables relate and a desire to allow, and then later resolve, ambiguity in their conceptual models. We leverage these findings to develop rTisane, a DSL for expressing conceptual models augmented with an interactive disambiguation process. In a controlled evaluation, we find that rTisane's DSL helps analysts engage more deeply with and accurately externalize their assumptions. rTisane also leads to statistical models that match analysts' assumptions, maintain analysis intent, and better fit the data.
Repairing Brain-Computer Interfaces with Fault-Based Data Acquisition
Mar 20, 2022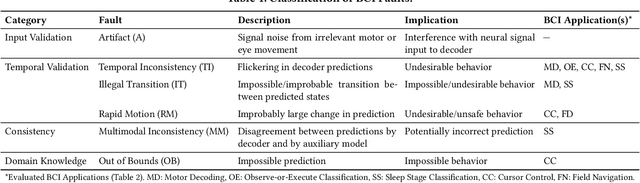
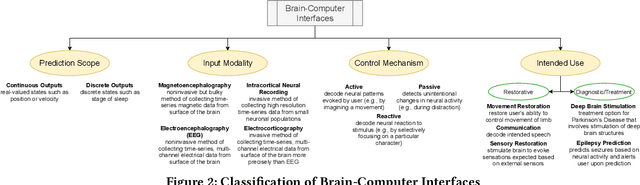


Brain-computer interfaces (BCIs) decode recorded neural signals from the brain and/or stimulate the brain with encoded neural signals. BCIs span both hardware and software and have a wide range of applications in restorative medicine, from restoring movement through prostheses and robotic limbs to restoring sensation and communication through spellers. BCIs also have applications in diagnostic medicine, e.g., providing clinicians with data for detecting seizures, sleep patterns, or emotions. Despite their promise, BCIs have not yet been adopted for long-term, day-to-day use because of challenges related to reliability and robustness, which are needed for safe operation in all scenarios. Ensuring safe operation currently requires hours of manual data collection and recalibration, involving both patients and clinicians. However, data collection is not targeted at eliminating specific faults in a BCI. This paper presents a new methodology for characterizing, detecting, and localizing faults in BCIs. Specifically, it proposes partial test oracles as a method for detecting faults and slice functions as a method for localizing faults to characteristic patterns in the input data or relevant tasks performed by the user. Through targeted data acquisition and retraining, the proposed methodology improves the correctness of BCIs. We evaluated the proposed methodology on five BCI applications. The results show that the proposed methodology (1) precisely localizes faults and (2) can significantly reduce the frequency of faults through retraining based on targeted, fault-based data acquisition. These results suggest that the proposed methodology is a promising step towards repairing faulty BCIs.
Tisane: Authoring Statistical Models via Formal Reasoning from Conceptual and Data Relationships
Jan 07, 2022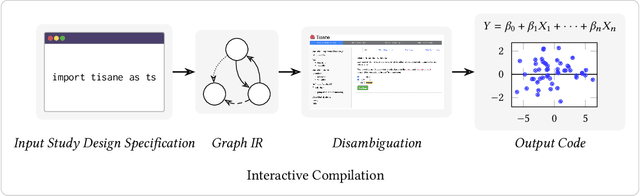
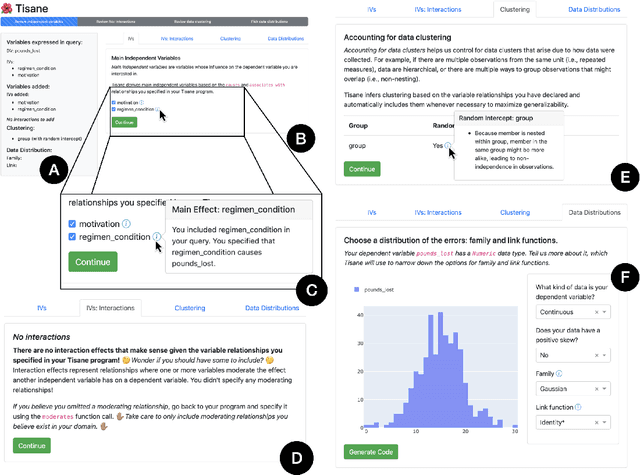
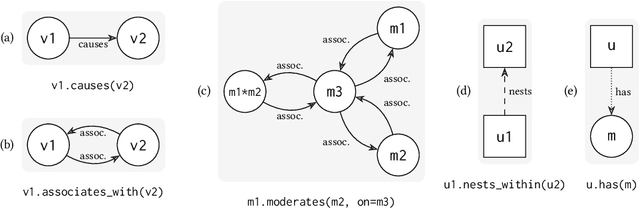
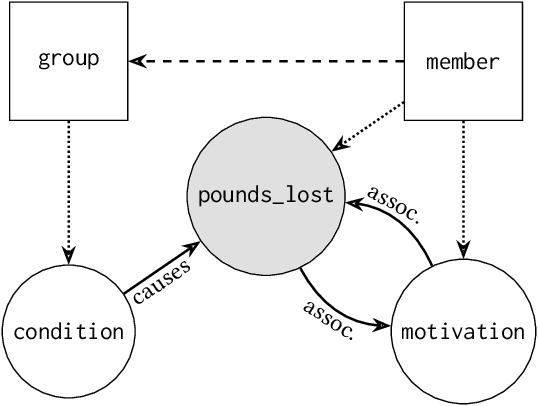
Proper statistical modeling incorporates domain theory about how concepts relate and details of how data were measured. However, data analysts currently lack tool support for recording and reasoning about domain assumptions, data collection, and modeling choices in an integrated manner, leading to mistakes that can compromise scientific validity. For instance, generalized linear mixed-effects models (GLMMs) help answer complex research questions, but omitting random effects impairs the generalizability of results. To address this need, we present Tisane, a mixed-initiative system for authoring generalized linear models with and without mixed-effects. Tisane introduces a study design specification language for expressing and asking questions about relationships between variables. Tisane contributes an interactive compilation process that represents relationships in a graph, infers candidate statistical models, and asks follow-up questions to disambiguate user queries to construct a valid model. In case studies with three researchers, we find that Tisane helps them focus on their goals and assumptions while avoiding past mistakes.