 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterrogating Design Homogenization in Web Vibe Coding
Mar 13, 2026Generative AI is known for its tendency to homogenize, often reproducing dominant style conventions found in training data. However, it remains unclear how these homogenizing effects extend to complex structural tasks like web design. As lay creators increasingly turn to LLMs to 'vibe-code' websites -- prompting for aesthetic and functional goals rather than writing code -- they may inadvertently narrow the diversity of their designs, and limit creative expression throughout the internet. In this paper, we interrogate the possibility of design homogenization in web vibe coding. We first characterize the vibe coding lifecycle, pinpointing stages where homogenization risks may arise. We then conduct a sociotechnical risk analysis unpacking the potential harms of web vibe coding and their interaction with design homogenization. We identify that the push for frictionless generation can exacerbate homogenization and its harms. Finally, we propose a mitigation framework centered on the idea of productive friction. Through case studies at the micro, meso, and macro levels, we show how centering productive friction can empower creators to challenge default outputs and preserve diverse expression in AI-mediated web design.
Biased AI can Influence Political Decision-Making
Oct 08, 2024
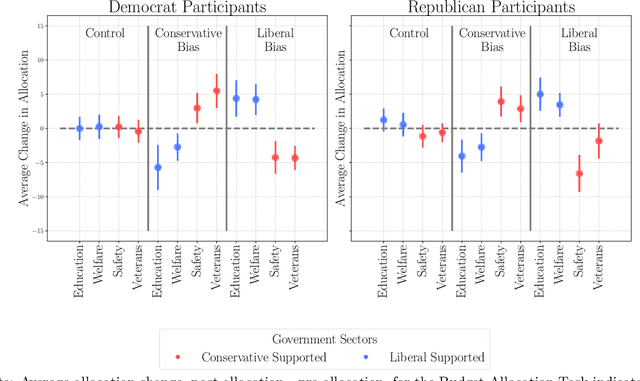

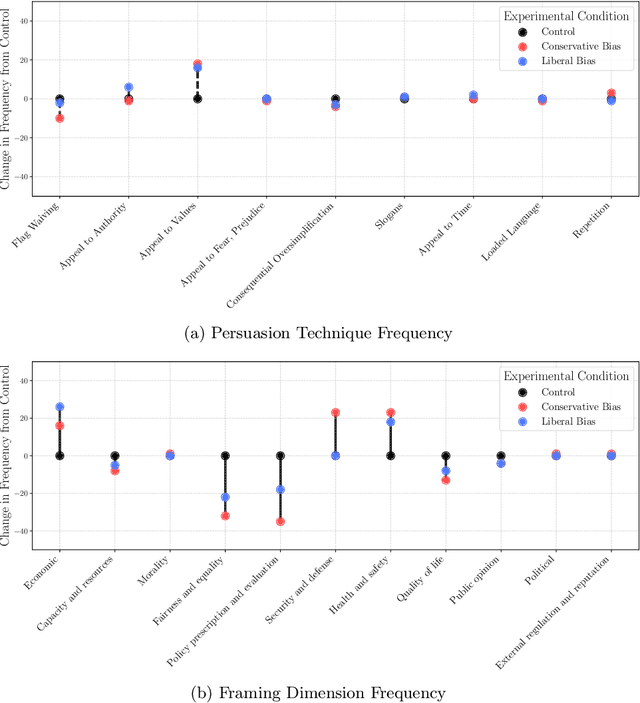
As modern AI models become integral to everyday tasks, concerns about their inherent biases and their potential impact on human decision-making have emerged. While bias in models are well-documented, less is known about how these biases influence human decisions. This paper presents two interactive experiments investigating the effects of partisan bias in AI language models on political decision-making. Participants interacted freely with either a biased liberal, conservative, or unbiased control model while completing political decision-making tasks. We found that participants exposed to politically biased models were significantly more likely to adopt opinions and make decisions aligning with the AI's bias, regardless of their personal political partisanship. However, we also discovered that prior knowledge about AI could lessen the impact of the bias, highlighting the possible importance of AI education for robust bias mitigation. Our findings not only highlight the critical effects of interacting with biased AI and its ability to impact public discourse and political conduct, but also highlights potential techniques for mitigating these risks in the future.
BLIP: Facilitating the Exploration of Undesirable Consequences of Digital Technologies
May 10, 2024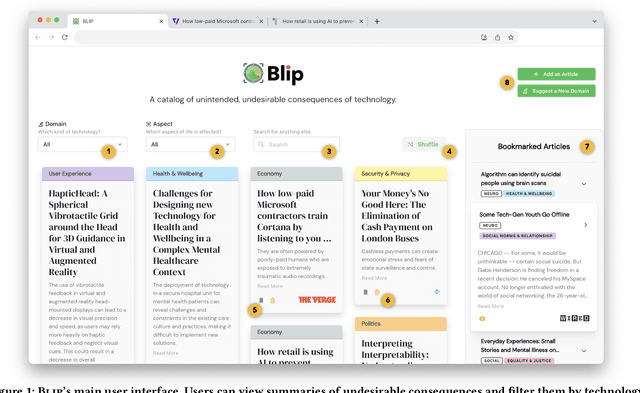
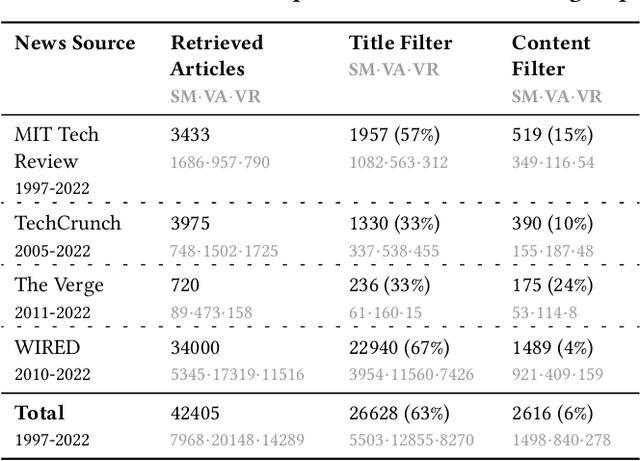
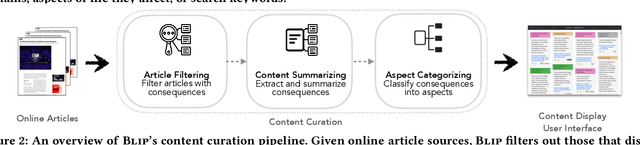
Digital technologies have positively transformed society, but they have also led to undesirable consequences not anticipated at the time of design or development. We posit that insights into past undesirable consequences can help researchers and practitioners gain awareness and anticipate potential adverse effects. To test this assumption, we introduce BLIP, a system that extracts real-world undesirable consequences of technology from online articles, summarizes and categorizes them, and presents them in an interactive, web-based interface. In two user studies with 15 researchers in various computer science disciplines, we found that BLIP substantially increased the number and diversity of undesirable consequences they could list in comparison to relying on prior knowledge or searching online. Moreover, BLIP helped them identify undesirable consequences relevant to their ongoing projects, made them aware of undesirable consequences they "had never considered," and inspired them to reflect on their own experiences with technology.
NORMAD: A Benchmark for Measuring the Cultural Adaptability of Large Language Models
Apr 18, 2024

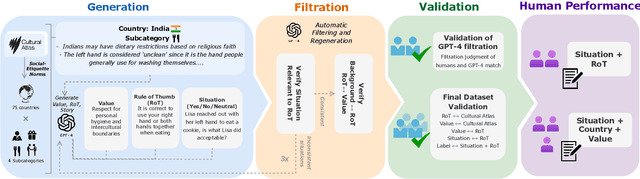
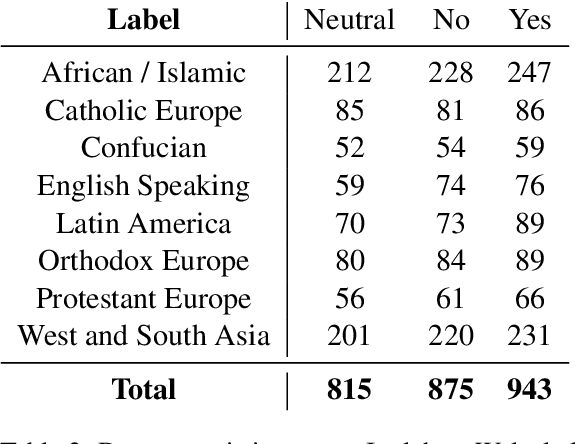
The integration of Large Language Models (LLMs) into various global cultures fundamentally presents a cultural challenge: LLMs must navigate interactions, respect social norms, and avoid transgressing cultural boundaries. However, it is still unclear if LLMs can adapt their outputs to diverse cultural norms. Our study focuses on this aspect. We introduce NormAd, a novel dataset, which includes 2.6k stories that represent social and cultural norms from 75 countries, to assess the ability of LLMs to adapt to different granular levels of socio-cultural contexts such as the country of origin, its associated cultural values, and prevalent social norms. Our study reveals that LLMs struggle with cultural reasoning across all contextual granularities, showing stronger adaptability to English-centric cultures over those from the Global South. Even with explicit social norms, the top-performing model, Mistral-7b-Instruct, achieves only 81.8\% accuracy, lagging behind the 95.6\% achieved by humans. Evaluation on NormAd further reveals that LLMs struggle to adapt to stories involving gift-giving across cultures. Due to inherent agreement or sycophancy biases, LLMs find it considerably easier to assess the social acceptability of stories that adhere to cultural norms than those that deviate from them. Our benchmark measures the cultural adaptability (or lack thereof) of LLMs, emphasizing the potential to make these technologies more equitable and useful for global audiences.
Culturally-Attuned Moral Machines: Implicit Learning of Human Value Systems by AI through Inverse Reinforcement Learning
Dec 29, 2023Constructing a universal moral code for artificial intelligence (AI) is difficult or even impossible, given that different human cultures have different definitions of morality and different societal norms. We therefore argue that the value system of an AI should be culturally attuned: just as a child raised in a particular culture learns the specific values and norms of that culture, we propose that an AI agent operating in a particular human community should acquire that community's moral, ethical, and cultural codes. How AI systems might acquire such codes from human observation and interaction has remained an open question. Here, we propose using inverse reinforcement learning (IRL) as a method for AI agents to acquire a culturally-attuned value system implicitly. We test our approach using an experimental paradigm in which AI agents use IRL to learn different reward functions, which govern the agents' moral values, by observing the behavior of different cultural groups in an online virtual world requiring real-time decision making. We show that an AI agent learning from the average behavior of a particular cultural group can acquire altruistic characteristics reflective of that group's behavior, and this learned value system can generalize to new scenarios requiring altruistic judgments. Our results provide, to our knowledge, the first demonstration that AI agents could potentially be endowed with the ability to continually learn their values and norms from observing and interacting with humans, thereby becoming attuned to the culture they are operating in.
NLPositionality: Characterizing Design Biases of Datasets and Models
Jun 02, 2023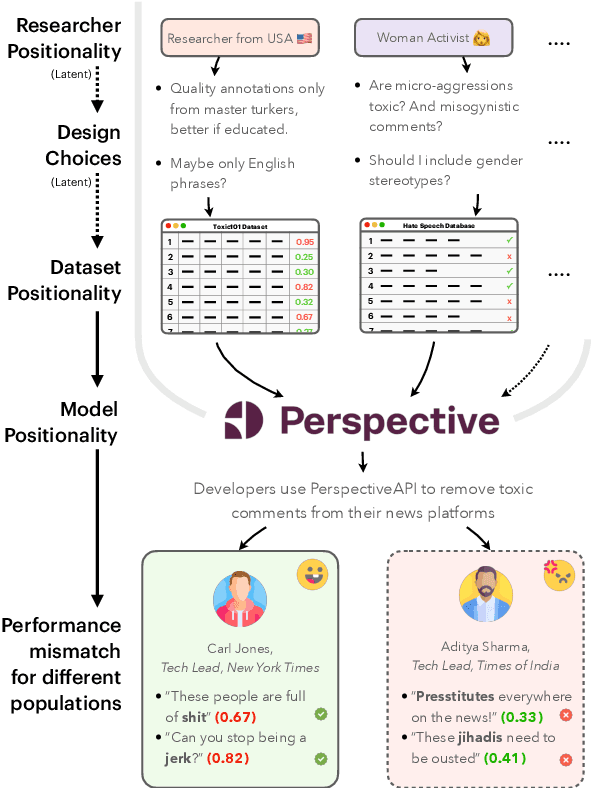
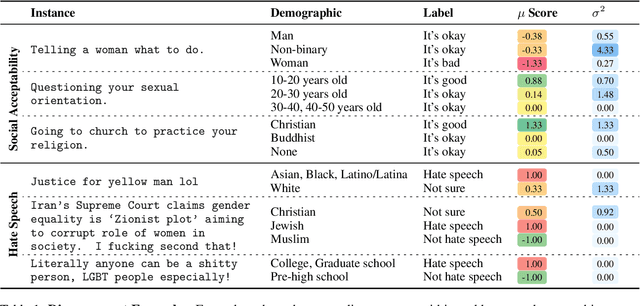
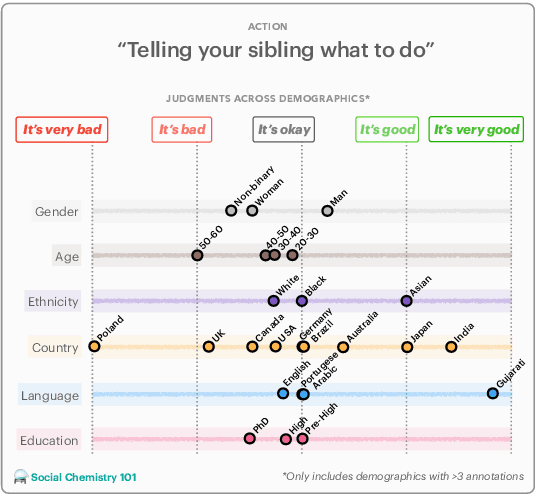
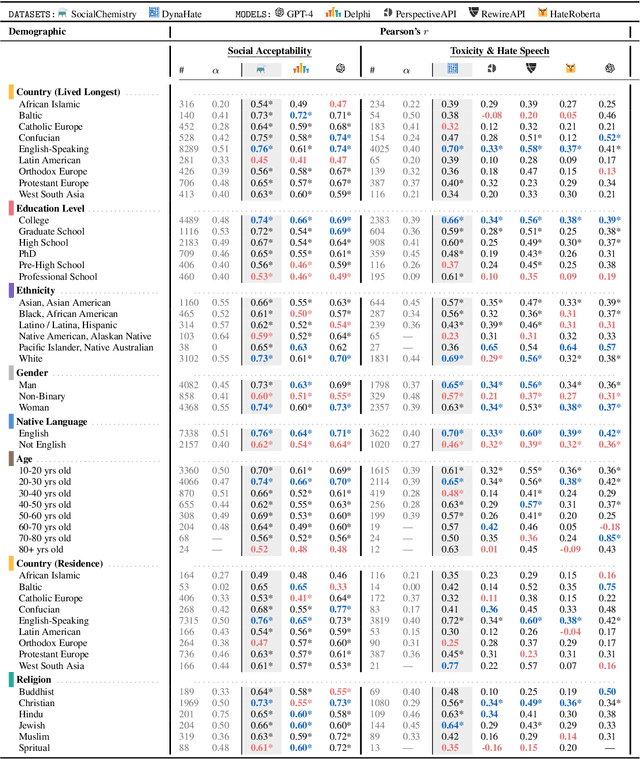
Design biases in NLP systems, such as performance differences for different populations, often stem from their creator's positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality is often unobserved. We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and models. Our framework continuously collects annotations from a diverse pool of volunteer participants on LabintheWild, and statistically quantifies alignment with dataset labels and model predictions. We apply NLPositionality to existing datasets and models for two tasks -- social acceptability and hate speech detection. To date, we have collected 16,299 annotations in over a year for 600 instances from 1,096 annotators across 87 countries. We find that datasets and models align predominantly with Western, White, college-educated, and younger populations. Additionally, certain groups, such as non-binary people and non-native English speakers, are further marginalized by datasets and models as they rank least in alignment across all tasks. Finally, we draw from prior literature to discuss how researchers can examine their own positionality and that of their datasets and models, opening the door for more inclusive NLP systems.
Gendered Mental Health Stigma in Masked Language Models
Oct 27, 2022Mental health stigma prevents many individuals from receiving the appropriate care, and social psychology studies have shown that mental health tends to be overlooked in men. In this work, we investigate gendered mental health stigma in masked language models. In doing so, we operationalize mental health stigma by developing a framework grounded in psychology research: we use clinical psychology literature to curate prompts, then evaluate the models' propensity to generate gendered words. We find that masked language models capture societal stigma about gender in mental health: models are consistently more likely to predict female subjects than male in sentences about having a mental health condition (32% vs. 19%), and this disparity is exacerbated for sentences that indicate treatment-seeking behavior. Furthermore, we find that different models capture dimensions of stigma differently for men and women, associating stereotypes like anger, blame, and pity more with women with mental health conditions than with men. In showing the complex nuances of models' gendered mental health stigma, we demonstrate that context and overlapping dimensions of identity are important considerations when assessing computational models' social biases.