 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Document Selection on Query-focused Text Analysis
Apr 13, 2026Analyses of document collections often require selecting what data to analyze, as not all documents are relevant to a particular research question and computational constraints preclude analyzing all documents, yet little work has examined effects of selection strategy choices. We systematically evaluate seven selection methods (from random selection to hybrid retrieval) on outputs from four text analyses methods (LDA, BERTopic, TopicGPT, HiCode) over two datasets with 26 open-ended queries. Our evaluation reveals practice guidance: semantic or hybrid retrieval offer strong go-to approaches that avoid the pitfalls of weaker selection strategies and the unnecessary compute overhead of more complicated ones. Overall, our evaluation framework establishes data selection as a methodological decision, rather than a practical necessity, inviting the development of new strategies.
What Makes a Good Response? An Empirical Analysis of Quality in Qualitative Interviews
Apr 06, 2026Qualitative interviews provide essential insights into human experiences when they elicit high-quality responses. While qualitative and NLP researchers have proposed various measures of interview quality, these measures lack validation that high-scoring responses actually contribute to the study's goals. In this work, we identify, implement, and evaluate 10 proposed measures of interview response quality to determine which are actually predictive of a response's contribution to the study findings. To conduct our analysis, we introduce the Qualitative Interview Corpus, a newly constructed dataset of 343 interview transcripts with 16,940 participant responses from 14 real research projects. We find that direct relevance to a key research question is the strongest predictor of response quality. We additionally find that two measures commonly used to evaluate NLP interview systems, clarity and surprisal-based informativeness, are not predictive of response quality. Our work provides analytic insights and grounded, scalable metrics to inform the design of qualitative studies and the evaluation of automated interview systems.
Does Local News Stay Local?: Online Content Shifts in Sinclair-Acquired Stations
Oct 08, 2025Local news stations are often considered to be reliable sources of non-politicized information, particularly local concerns that residents care about. Because these stations are trusted news sources, viewers are particularly susceptible to the information they report. The Sinclair Broadcast group is a broadcasting company that has acquired many local news stations in the last decade. We investigate the effects of local news stations being acquired by Sinclair: how does coverage change? We use computational methods to investigate changes in internet content put out by local news stations before and after being acquired by Sinclair and in comparison to national news outlets. We find that there is clear evidence that local news stations report more frequently on national news at the expense of local topics, and that their coverage of polarizing national topics increases.
SynthTextEval: Synthetic Text Data Generation and Evaluation for High-Stakes Domains
Jul 09, 2025We present SynthTextEval, a toolkit for conducting comprehensive evaluations of synthetic text. The fluency of large language model (LLM) outputs has made synthetic text potentially viable for numerous applications, such as reducing the risks of privacy violations in the development and deployment of AI systems in high-stakes domains. Realizing this potential, however, requires principled consistent evaluations of synthetic data across multiple dimensions: its utility in downstream systems, the fairness of these systems, the risk of privacy leakage, general distributional differences from the source text, and qualitative feedback from domain experts. SynthTextEval allows users to conduct evaluations along all of these dimensions over synthetic data that they upload or generate using the toolkit's generation module. While our toolkit can be run over any data, we highlight its functionality and effectiveness over datasets from two high-stakes domains: healthcare and law. By consolidating and standardizing evaluation metrics, we aim to improve the viability of synthetic text, and in-turn, privacy-preservation in AI development.
Evaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
Oct 10, 2024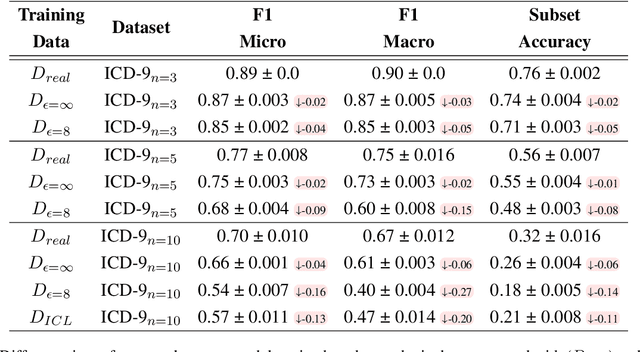


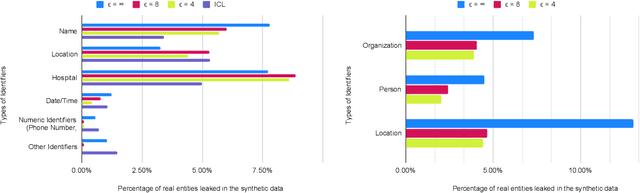
The difficulty of anonymizing text data hinders the development and deployment of NLP in high-stakes domains that involve private data, such as healthcare and social services. Poorly anonymized sensitive data cannot be easily shared with annotators or external researchers, nor can it be used to train public models. In this work, we explore the feasibility of using synthetic data generated from differentially private language models in place of real data to facilitate the development of NLP in these domains without compromising privacy. In contrast to prior work, we generate synthetic data for real high-stakes domains, and we propose and conduct use-inspired evaluations to assess data quality. Our results show that prior simplistic evaluations have failed to highlight utility, privacy, and fairness issues in the synthetic data. Overall, our work underscores the need for further improvements to synthetic data generation for it to be a viable way to enable privacy-preserving data sharing.
Locating Information Gaps and Narrative Inconsistencies Across Languages: A Case Study of LGBT People Portrayals on Wikipedia
Oct 05, 2024



To explain social phenomena and identify systematic biases, much research in computational social science focuses on comparative text analyses. These studies often rely on coarse corpus-level statistics or local word-level analyses, mainly in English. We introduce the InfoGap method -- an efficient and reliable approach to locating information gaps and inconsistencies in articles at the fact level, across languages. We evaluate InfoGap by analyzing LGBT people's portrayals, across 2.7K biography pages on English, Russian, and French Wikipedias. We find large discrepancies in factual coverage across the languages. Moreover, our analysis reveals that biographical facts carrying negative connotations are more likely to be highlighted in Russian Wikipedia. Crucially, InfoGap both facilitates large scale analyses, and pinpoints local document- and fact-level information gaps, laying a new foundation for targeted and nuanced comparative language analysis at scale.
pathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.
Designing an Evaluation Framework for Large Language Models in Astronomy Research
May 30, 2024


Large Language Models (LLMs) are shifting how scientific research is done. It is imperative to understand how researchers interact with these models and how scientific sub-communities like astronomy might benefit from them. However, there is currently no standard for evaluating the use of LLMs in astronomy. Therefore, we present the experimental design for an evaluation study on how astronomy researchers interact with LLMs. We deploy a Slack chatbot that can answer queries from users via Retrieval-Augmented Generation (RAG); these responses are grounded in astronomy papers from arXiv. We record and anonymize user questions and chatbot answers, user upvotes and downvotes to LLM responses, user feedback to the LLM, and retrieved documents and similarity scores with the query. Our data collection method will enable future dynamic evaluations of LLM tools for astronomy.
Riveter: Measuring Power and Social Dynamics Between Entities
Dec 15, 2023



Riveter provides a complete easy-to-use pipeline for analyzing verb connotations associated with entities in text corpora. We prepopulate the package with connotation frames of sentiment, power, and agency, which have demonstrated usefulness for capturing social phenomena, such as gender bias, in a broad range of corpora. For decades, lexical frameworks have been foundational tools in computational social science, digital humanities, and natural language processing, facilitating multifaceted analysis of text corpora. But working with verb-centric lexica specifically requires natural language processing skills, reducing their accessibility to other researchers. By organizing the language processing pipeline, providing complete lexicon scores and visualizations for all entities in a corpus, and providing functionality for users to target specific research questions, Riveter greatly improves the accessibility of verb lexica and can facilitate a broad range of future research.
Developing Speech Processing Pipelines for Police Accountability
Jun 09, 2023Police body-worn cameras have the potential to improve accountability and transparency in policing. Yet in practice, they result in millions of hours of footage that is never reviewed. We investigate the potential of large pre-trained speech models for facilitating reviews, focusing on ASR and officer speech detection in footage from traffic stops. Our proposed pipeline includes training data alignment and filtering, fine-tuning with resource constraints, and combining officer speech detection with ASR for a fully automated approach. We find that (1) fine-tuning strongly improves ASR performance on officer speech (WER=12-13%), (2) ASR on officer speech is much more accurate than on community member speech (WER=43.55-49.07%), (3) domain-specific tasks like officer speech detection and diarization remain challenging. Our work offers practical applications for reviewing body camera footage and general guidance for adapting pre-trained speech models to noisy multi-speaker domains.