 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBookReconciler: An Open-Source Tool for Metadata Enrichment and Work-Level Clustering
Dec 17, 2025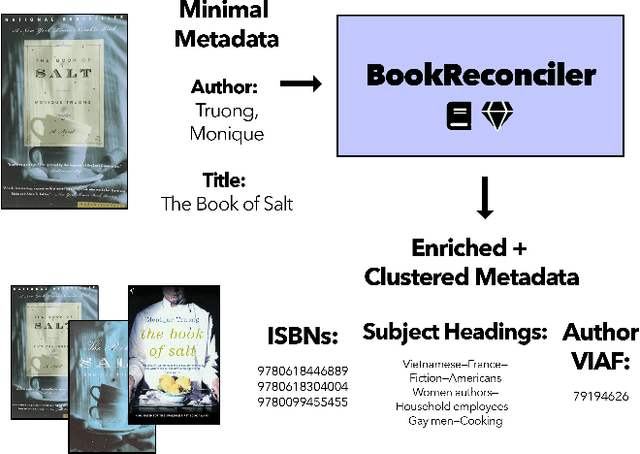
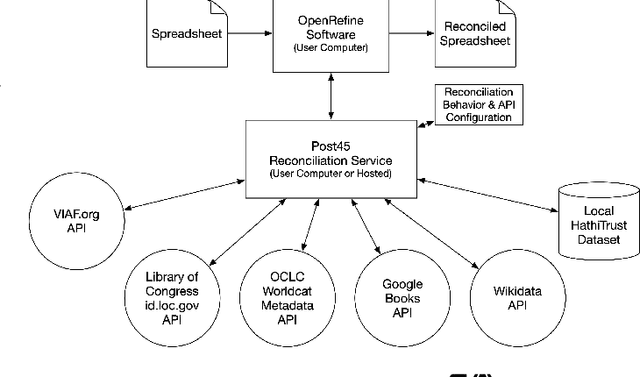
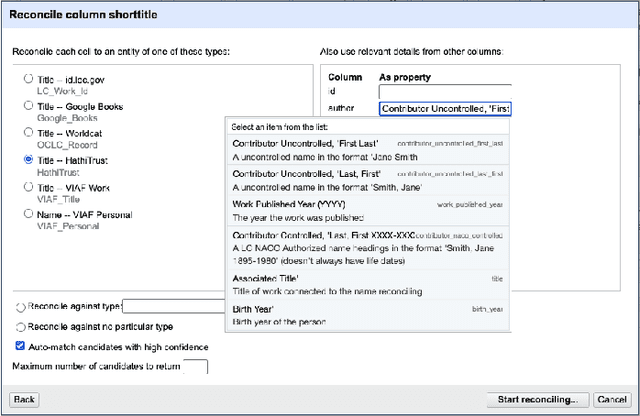
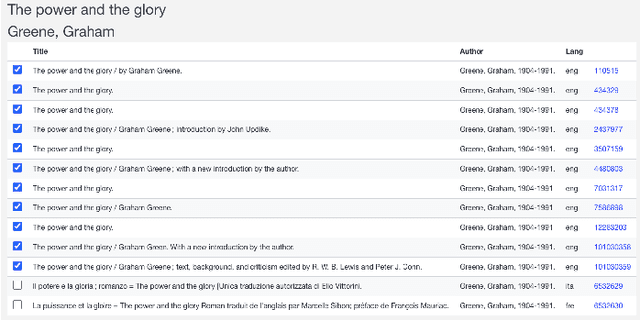
We present BookReconciler, an open-source tool for enhancing and clustering book data. BookReconciler allows users to take spreadsheets with minimal metadata, such as book title and author, and automatically 1) add authoritative, persistent identifiers like ISBNs 2) and cluster related Expressions and Manifestations of the same Work, e.g., different translations or editions. This enhancement makes it easier to combine related collections and analyze books at scale. The tool is currently designed as an extension for OpenRefine -- a popular software application -- and connects to major bibliographic services including the Library of Congress, VIAF, OCLC, HathiTrust, Google Books, and Wikidata. Our approach prioritizes human judgment. Through an interactive interface, users can manually evaluate matches and define the contours of a Work (e.g., to include translations or not). We evaluate reconciliation performance on datasets of U.S. prize-winning books and contemporary world fiction. BookReconciler achieves near-perfect accuracy for U.S. works but lower performance for global texts, reflecting structural weaknesses in bibliographic infrastructures for non-English and global literature. Overall, BookReconciler supports the reuse of bibliographic data across domains and applications, contributing to ongoing work in digital libraries and digital humanities.
* Published in the proceedings of the Joint Conference on Digital Libraries (JCDL) 2025, Resources
Provocations from the Humanities for Generative AI Research
Feb 26, 2025This paper presents a set of provocations for considering the uses, impact, and harms of generative AI from the perspective of humanities researchers. We provide a working definition of humanities research, summarize some of its most salient theories and methods, and apply these theories and methods to the current landscape of AI. Drawing from foundational work in critical data studies, along with relevant humanities scholarship, we elaborate eight claims with broad applicability to current conversations about generative AI: 1) Models make words, but people make meaning; 2) Generative AI requires an expanded definition of culture; 3) Generative AI can never be representative; 4) Bigger models are not always better models; 5) Not all training data is equivalent; 6) Openness is not an easy fix; 7) Limited access to compute enables corporate capture; and 8) AI universalism creates narrow human subjects. We conclude with a discussion of the importance of resisting the extraction of humanities research by computer science and related fields.
Does ChatGPT Have a Poetic Style?
Oct 20, 2024
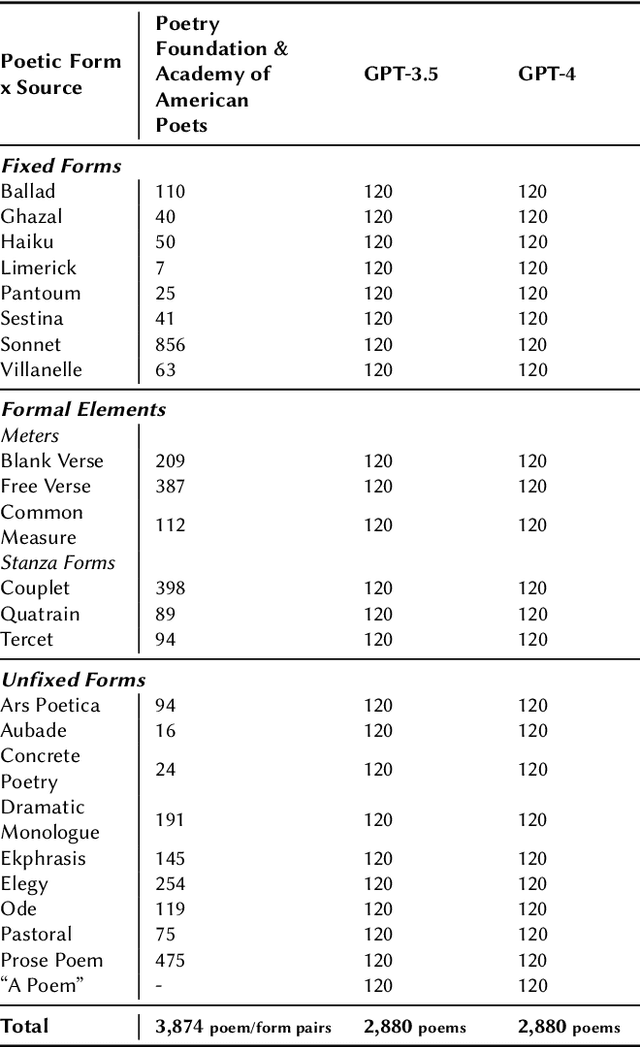

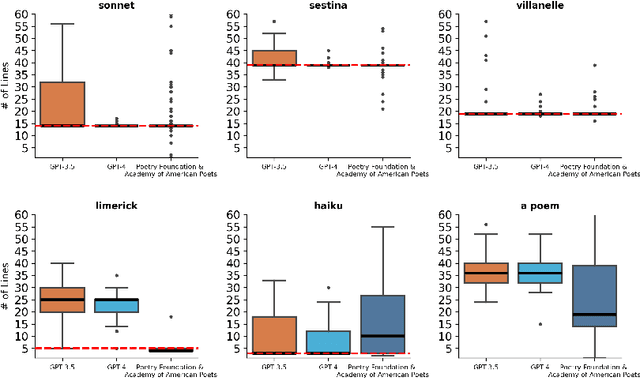
Generating poetry has become a popular application of LLMs, perhaps especially of OpenAI's widely-used chatbot ChatGPT. What kind of poet is ChatGPT? Does ChatGPT have its own poetic style? Can it successfully produce poems in different styles? To answer these questions, we prompt the GPT-3.5 and GPT-4 models to generate English-language poems in 24 different poetic forms and styles, about 40 different subjects, and in response to 3 different writing prompt templates. We then analyze the resulting 5.7k poems, comparing them to a sample of 3.7k poems from the Poetry Foundation and the Academy of American Poets. We find that the GPT models, especially GPT-4, can successfully produce poems in a range of both common and uncommon English-language forms in superficial yet noteworthy ways, such as by producing poems of appropriate lengths for sonnets (14 lines), villanelles (19 lines), and sestinas (39 lines). But the GPT models also exhibit their own distinct stylistic tendencies, both within and outside of these specific forms. Our results show that GPT poetry is much more constrained and uniform than human poetry, showing a strong penchant for rhyme, quatrains (4-line stanzas), iambic meter, first-person plural perspectives (we, us, our), and specific vocabulary like "heart," "embrace," "echo," and "whisper."
* CHR 2024: Computational Humanities Research Conference
Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets
Jun 27, 2024Large language models (LLMs) can now generate and recognize text in a wide range of styles and genres, including highly specialized, creative genres like poetry. But what do LLMs really know about poetry? What can they know about poetry? We develop a task to evaluate how well LLMs recognize a specific aspect of poetry, poetic form, for more than 20 forms and formal elements in the English language. Poetic form captures many different poetic features, including rhyme scheme, meter, and word or line repetition. We use this task to reflect on LLMs' current poetic capabilities, as well as the challenges and pitfalls of creating NLP benchmarks for poetry and for other creative tasks. In particular, we use this task to audit and reflect on the poems included in popular pretraining datasets. Our findings have implications for NLP researchers interested in model evaluation, digital humanities and cultural analytics scholars, and cultural heritage professionals.
The Afterlives of Shakespeare and Company in Online Social Readership
Jan 14, 2024



The growth of social reading platforms such as Goodreads and LibraryThing enables us to analyze reading activity at very large scale and in remarkable detail. But twenty-first century systems give us a perspective only on contemporary readers. Meanwhile, the digitization of the lending library records of Shakespeare and Company provides a window into the reading activity of an earlier, smaller community in interwar Paris. In this article, we explore the extent to which we can make comparisons between the Shakespeare and Company and Goodreads communities. By quantifying similarities and differences, we can identify patterns in how works have risen or fallen in popularity across these datasets. We can also measure differences in how works are received by measuring similarities and differences in co-reading patterns. Finally, by examining the complete networks of co-readership, we can observe changes in the overall structures of literary reception.
Riveter: Measuring Power and Social Dynamics Between Entities
Dec 15, 2023



Riveter provides a complete easy-to-use pipeline for analyzing verb connotations associated with entities in text corpora. We prepopulate the package with connotation frames of sentiment, power, and agency, which have demonstrated usefulness for capturing social phenomena, such as gender bias, in a broad range of corpora. For decades, lexical frameworks have been foundational tools in computational social science, digital humanities, and natural language processing, facilitating multifaceted analysis of text corpora. But working with verb-centric lexica specifically requires natural language processing skills, reducing their accessibility to other researchers. By organizing the language processing pipeline, providing complete lexicon scores and visualizations for all entities in a corpus, and providing functionality for users to target specific research questions, Riveter greatly improves the accessibility of verb lexica and can facilitate a broad range of future research.