 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning LLMs to Ask Good Questions A Case Study in Clinical Reasoning
Feb 20, 2025Large language models (LLMs) often fail to ask effective questions under uncertainty, making them unreliable in domains where proactive information-gathering is essential for decisionmaking. We present ALFA, a framework that improves LLM question-asking by (i) decomposing the notion of a "good" question into a set of theory-grounded attributes (e.g., clarity, relevance), (ii) controllably synthesizing attribute-specific question variations, and (iii) aligning models via preference-based optimization to explicitly learn to ask better questions along these fine-grained attributes. Focusing on clinical reasoning as a case study, we introduce the MediQ-AskDocs dataset, composed of 17k real-world clinical interactions augmented with 80k attribute-specific preference pairs of follow-up questions, as well as a novel expert-annotated interactive healthcare QA task to evaluate question-asking abilities. Models aligned with ALFA reduce diagnostic errors by 56.6% on MediQ-AskDocs compared to SOTA instruction-tuned LLMs, with a question-level win-rate of 64.4% and strong generalizability. Our findings suggest that explicitly guiding question-asking with structured, fine-grained attributes offers a scalable path to improve LLMs, especially in expert application domains.
Particip-AI: A Democratic Surveying Framework for Anticipating Future AI Use Cases, Harms and Benefits
Mar 21, 2024
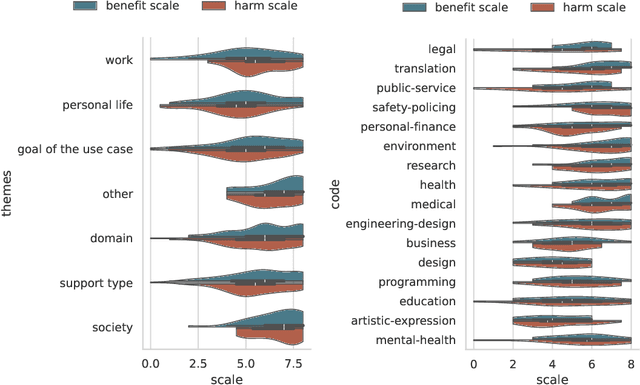
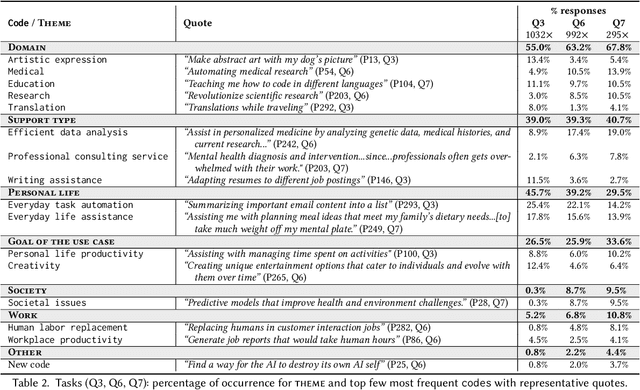
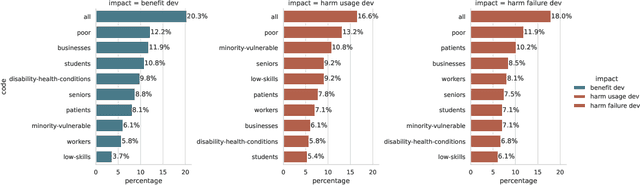
General purpose AI, such as ChatGPT, seems to have lowered the barriers for the public to use AI and harness its power. However, the governance and development of AI still remain in the hands of a few, and the pace of development is accelerating without proper assessment of risks. As a first step towards democratic governance and risk assessment of AI, we introduce Particip-AI, a framework to gather current and future AI use cases and their harms and benefits from non-expert public. Our framework allows us to study more nuanced and detailed public opinions on AI through collecting use cases, surfacing diverse harms through risk assessment under alternate scenarios (i.e., developing and not developing a use case), and illuminating tensions over AI development through making a concluding choice on its development. To showcase the promise of our framework towards guiding democratic AI, we gather responses from 295 demographically diverse participants. We find that participants' responses emphasize applications for personal life and society, contrasting with most current AI development's business focus. This shows the value of surfacing diverse harms that are complementary to expert assessments. Furthermore, we found that perceived impact of not developing use cases predicted participants' judgements of whether AI use cases should be developed, and highlighted lay users' concerns of techno-solutionism. We conclude with a discussion on how frameworks like Particip-AI can further guide democratic AI governance and regulation.
Riveter: Measuring Power and Social Dynamics Between Entities
Dec 15, 2023



Riveter provides a complete easy-to-use pipeline for analyzing verb connotations associated with entities in text corpora. We prepopulate the package with connotation frames of sentiment, power, and agency, which have demonstrated usefulness for capturing social phenomena, such as gender bias, in a broad range of corpora. For decades, lexical frameworks have been foundational tools in computational social science, digital humanities, and natural language processing, facilitating multifaceted analysis of text corpora. But working with verb-centric lexica specifically requires natural language processing skills, reducing their accessibility to other researchers. By organizing the language processing pipeline, providing complete lexicon scores and visualizations for all entities in a corpus, and providing functionality for users to target specific research questions, Riveter greatly improves the accessibility of verb lexica and can facilitate a broad range of future research.
Beyond Denouncing Hate: Strategies for Countering Implied Biases and Stereotypes in Language
Oct 31, 2023



Counterspeech, i.e., responses to counteract potential harms of hateful speech, has become an increasingly popular solution to address online hate speech without censorship. However, properly countering hateful language requires countering and dispelling the underlying inaccurate stereotypes implied by such language. In this work, we draw from psychology and philosophy literature to craft six psychologically inspired strategies to challenge the underlying stereotypical implications of hateful language. We first examine the convincingness of each of these strategies through a user study, and then compare their usages in both human- and machine-generated counterspeech datasets. Our results show that human-written counterspeech uses countering strategies that are more specific to the implied stereotype (e.g., counter examples to the stereotype, external factors about the stereotype's origins), whereas machine-generated counterspeech uses less specific strategies (e.g., generally denouncing the hatefulness of speech). Furthermore, machine-generated counterspeech often employs strategies that humans deem less convincing compared to human-produced counterspeech. Our findings point to the importance of accounting for the underlying stereotypical implications of speech when generating counterspeech and for better machine reasoning about anti-stereotypical examples.