 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticip-AI: A Democratic Surveying Framework for Anticipating Future AI Use Cases, Harms and Benefits
Mar 21, 2024
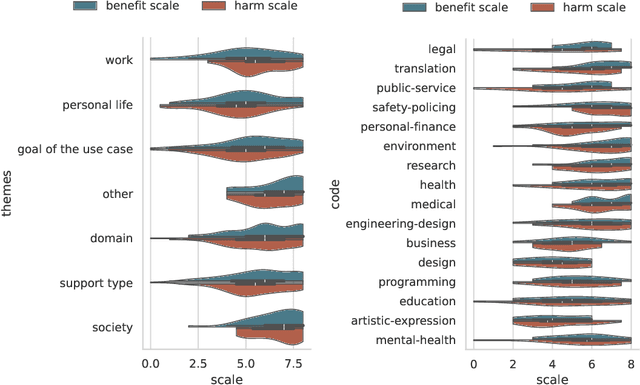
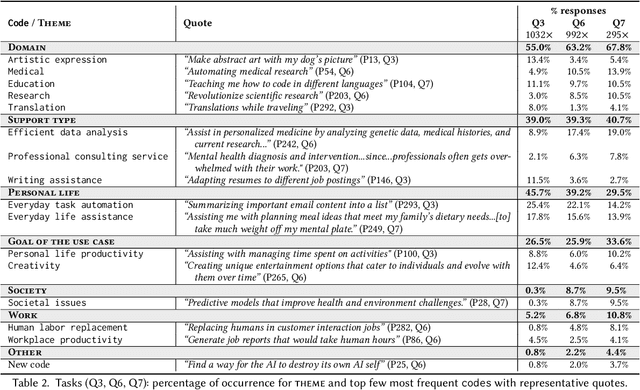
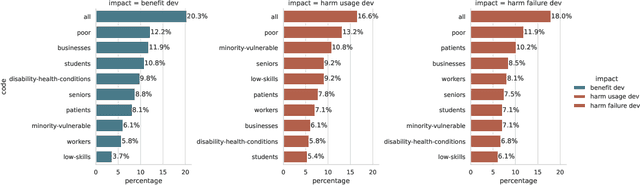
General purpose AI, such as ChatGPT, seems to have lowered the barriers for the public to use AI and harness its power. However, the governance and development of AI still remain in the hands of a few, and the pace of development is accelerating without proper assessment of risks. As a first step towards democratic governance and risk assessment of AI, we introduce Particip-AI, a framework to gather current and future AI use cases and their harms and benefits from non-expert public. Our framework allows us to study more nuanced and detailed public opinions on AI through collecting use cases, surfacing diverse harms through risk assessment under alternate scenarios (i.e., developing and not developing a use case), and illuminating tensions over AI development through making a concluding choice on its development. To showcase the promise of our framework towards guiding democratic AI, we gather responses from 295 demographically diverse participants. We find that participants' responses emphasize applications for personal life and society, contrasting with most current AI development's business focus. This shows the value of surfacing diverse harms that are complementary to expert assessments. Furthermore, we found that perceived impact of not developing use cases predicted participants' judgements of whether AI use cases should be developed, and highlighted lay users' concerns of techno-solutionism. We conclude with a discussion on how frameworks like Particip-AI can further guide democratic AI governance and regulation.
Measuring the Carbon Intensity of AI in Cloud Instances
Jun 10, 2022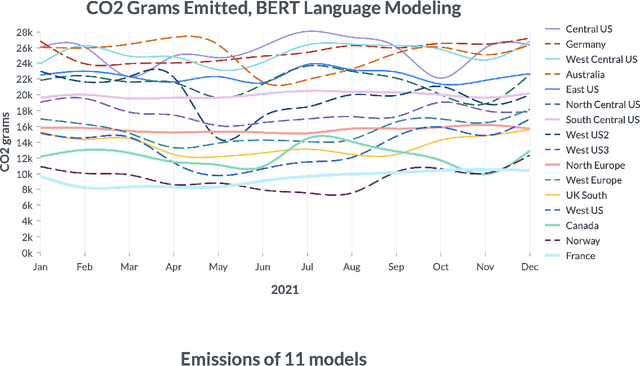

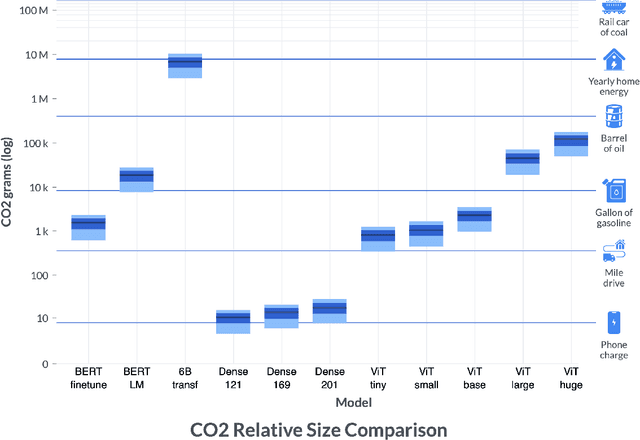

By providing unprecedented access to computational resources, cloud computing has enabled rapid growth in technologies such as machine learning, the computational demands of which incur a high energy cost and a commensurate carbon footprint. As a result, recent scholarship has called for better estimates of the greenhouse gas impact of AI: data scientists today do not have easy or reliable access to measurements of this information, precluding development of actionable tactics. Cloud providers presenting information about software carbon intensity to users is a fundamental stepping stone towards minimizing emissions. In this paper, we provide a framework for measuring software carbon intensity, and propose to measure operational carbon emissions by using location-based and time-specific marginal emissions data per energy unit. We provide measurements of operational software carbon intensity for a set of modern models for natural language processing and computer vision, and a wide range of model sizes, including pretraining of a 6.1 billion parameter language model. We then evaluate a suite of approaches for reducing emissions on the Microsoft Azure cloud compute platform: using cloud instances in different geographic regions, using cloud instances at different times of day, and dynamically pausing cloud instances when the marginal carbon intensity is above a certain threshold. We confirm previous results that the geographic region of the data center plays a significant role in the carbon intensity for a given cloud instance, and find that choosing an appropriate region can have the largest operational emissions reduction impact. We also show that the time of day has notable impact on operational software carbon intensity. Finally, we conclude with recommendations for how machine learning practitioners can use software carbon intensity information to reduce environmental impact.