 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Narrative Content in Web-scale LLM Pretraining Data
Jun 17, 2026The narrative composition of web-scale LLM pretraining corpora remains largely unexplored even though narrative is a fundamental mode of human communication. We present the first fine-grained study of narrative features in Dolma, a 3-trillion-token open pretraining corpus. Drawing on narrative theory, we design a framework spanning three core narrative elements (agency, setting, and events) operationalized as 11 interpretable dimensions. After sampling and annotating a diverse set of 400 passages, we finetune and validate NarraBERT, a RoBERTa-based model for fine-grained narrative prediction. We apply NarraBERT to 3M passages, resulting in a new dataset, NarraDolma. We find (i) narrative structure is measurable at scale across extremely heterogeneous data, (ii) we uncover a continuous, multidimensional narrative structure underlying web text, and (iii) narrative qualities are unequally distributed across pretraining sources and topics in ways that current curation practices neither measure nor account for. Our framework, dataset, and analyses provide a foundation for understanding how narrative qualities are distributed in LLM pretraining data and for studying how data composition affects narrative reasoning tasks. We publicly release NarraDolma and NarraBERT.
LLM-Generated or Human-Written? Comparing Review and Non-Review Papers on ArXiv
Jan 19, 2026ArXiv recently prohibited the upload of unpublished review papers to its servers in the Computer Science domain, citing a high prevalence of LLM-generated content in these categories. However, this decision was not accompanied by quantitative evidence. In this work, we investigate this claim by measuring the proportion of LLM-generated content in review vs. non-review research papers in recent years. Using two high-quality detection methods, we find a substantial increase in LLM-generated content across both review and non-review papers, with a higher prevalence in review papers. However, when considering the number of LLM-generated papers published in each category, the estimates of non-review LLM-generated papers are almost six times higher. Furthermore, we find that this policy will affect papers in certain domains far more than others, with the CS subdiscipline Computers & Society potentially facing cuts of 50%. Our analysis provides an evidence-based framework for evaluating such policy decisions, and we release our code to facilitate future investigations at: https://github.com/yanaiela/llm-review-arxiv.
Social Story Frames: Contextual Reasoning about Narrative Intent and Reception
Dec 17, 2025Reading stories evokes rich interpretive, affective, and evaluative responses, such as inferences about narrative intent or judgments about characters. Yet, computational models of reader response are limited, preventing nuanced analyses. To address this gap, we introduce SocialStoryFrames, a formalism for distilling plausible inferences about reader response, such as perceived author intent, explanatory and predictive reasoning, affective responses, and value judgments, using conversational context and a taxonomy grounded in narrative theory, linguistic pragmatics, and psychology. We develop two models, SSF-Generator and SSF-Classifier, validated through human surveys (N=382 participants) and expert annotations, respectively. We conduct pilot analyses to showcase the utility of the formalism for studying storytelling at scale. Specifically, applying our models to SSF-Corpus, a curated dataset of 6,140 social media stories from diverse contexts, we characterize the frequency and interdependence of storytelling intents, and we compare and contrast narrative practices (and their diversity) across communities. By linking fine-grained, context-sensitive modeling with a generic taxonomy of reader responses, SocialStoryFrames enable new research into storytelling in online communities.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
Multi-Modal Framing Analysis of News
Mar 26, 2025



Automated frame analysis of political communication is a popular task in computational social science that is used to study how authors select aspects of a topic to frame its reception. So far, such studies have been narrow, in that they use a fixed set of pre-defined frames and focus only on the text, ignoring the visual contexts in which those texts appear. Especially for framing in the news, this leaves out valuable information about editorial choices, which include not just the written article but also accompanying photographs. To overcome such limitations, we present a method for conducting multi-modal, multi-label framing analysis at scale using large (vision-)language models. Grounding our work in framing theory, we extract latent meaning embedded in images used to convey a certain point and contrast that to the text by comparing the respective frames used. We also identify highly partisan framing of topics with issue-specific frame analysis found in prior qualitative work. We demonstrate a method for doing scalable integrative framing analysis of both text and image in news, providing a more complete picture for understanding media bias.
Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
Mar 15, 2025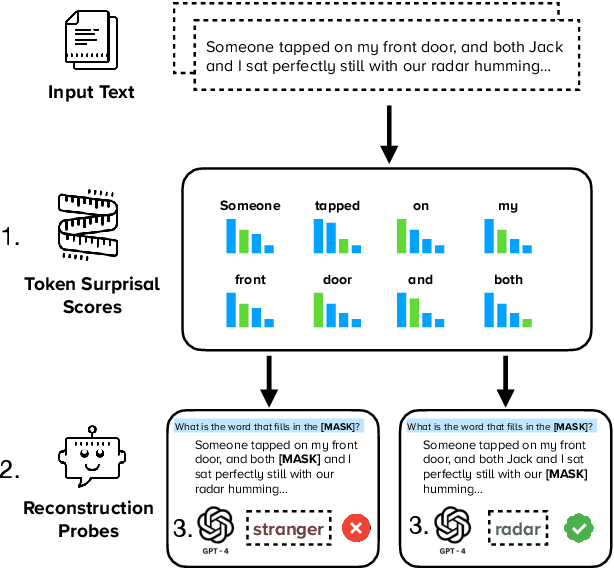

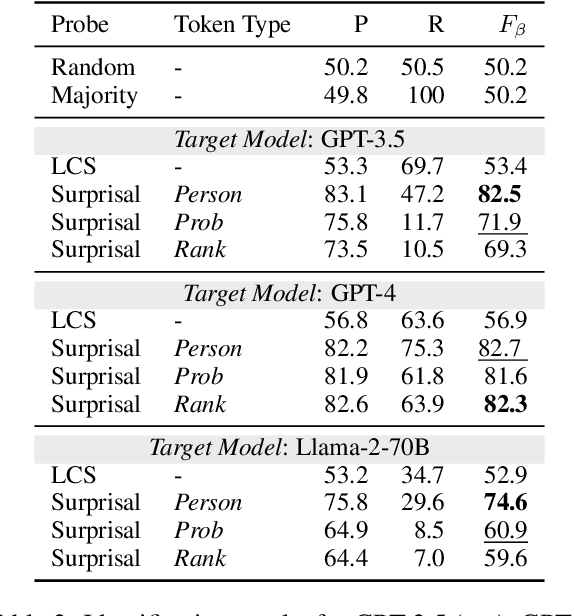
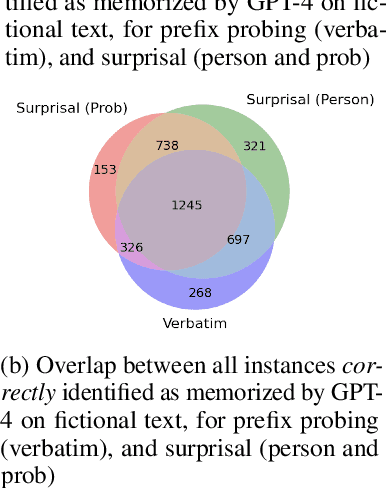
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. This lack of transparency creates multiple challenges: it limits external oversight and inspection of LLMs for issues such as copyright infringement, it undermines the agency of data authors, and it hinders scientific research on critical issues such as data contamination and data selection. How can we recover what training data is known to LLMs? In this work, we demonstrate a new method to identify training data known to proprietary LLMs like GPT-4 without requiring any access to model weights or token probabilities, by using information-guided probes. Our work builds on a key observation: text passages with high surprisal are good search material for memorization probes. By evaluating a model's ability to successfully reconstruct high-surprisal tokens in text, we can identify a surprising number of texts memorized by LLMs.
Provocations from the Humanities for Generative AI Research
Feb 26, 2025This paper presents a set of provocations for considering the uses, impact, and harms of generative AI from the perspective of humanities researchers. We provide a working definition of humanities research, summarize some of its most salient theories and methods, and apply these theories and methods to the current landscape of AI. Drawing from foundational work in critical data studies, along with relevant humanities scholarship, we elaborate eight claims with broad applicability to current conversations about generative AI: 1) Models make words, but people make meaning; 2) Generative AI requires an expanded definition of culture; 3) Generative AI can never be representative; 4) Bigger models are not always better models; 5) Not all training data is equivalent; 6) Openness is not an easy fix; 7) Limited access to compute enables corporate capture; and 8) AI universalism creates narrow human subjects. We conclude with a discussion of the importance of resisting the extraction of humanities research by computer science and related fields.
Automatic Detection of Research Values from Scientific Abstracts Across Computer Science Subfields
Feb 26, 2025The field of Computer science (CS) has rapidly evolved over the past few decades, providing computational tools and methodologies to various fields and forming new interdisciplinary communities. This growth in CS has significantly impacted institutional practices and relevant research communities. Therefore, it is crucial to explore what specific research values, known as basic and fundamental beliefs that guide or motivate research attitudes or actions, CS-related research communities promote. Prior research has manually analyzed research values from a small sample of machine learning papers. No prior work has studied the automatic detection of research values in CS from large-scale scientific texts across different research subfields. This paper introduces a detailed annotation scheme featuring ten research values that guide CS-related research. Based on the scheme, we build value classifiers to scale up the analysis and present a systematic study over 226,600 paper abstracts from 32 CS-related subfields and 86 popular publishing venues over ten years.
LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions
Oct 30, 2024



The rise of large language models (LLMs) has led many researchers to consider their usage for scientific work. Some have found benefits using LLMs to augment or automate aspects of their research pipeline, while others have urged caution due to risks and ethical concerns. Yet little work has sought to quantify and characterize how researchers use LLMs and why. We present the first large-scale survey of 816 verified research article authors to understand how the research community leverages and perceives LLMs as research tools. We examine participants' self-reported LLM usage, finding that 81% of researchers have already incorporated LLMs into different aspects of their research workflow. We also find that traditionally disadvantaged groups in academia (non-White, junior, and non-native English speaking researchers) report higher LLM usage and perceived benefits, suggesting potential for improved research equity. However, women, non-binary, and senior researchers have greater ethical concerns, potentially hindering adoption.
CulturalBench: a Robust, Diverse and Challenging Benchmark on Measuring the (Lack of) Cultural Knowledge of LLMs
Oct 03, 2024



To make large language models (LLMs) more helpful across diverse cultures, it is essential to have effective cultural knowledge benchmarks to measure and track our progress. Effective benchmarks need to be robust, diverse, and challenging. We introduce CulturalBench: a set of 1,227 human-written and human-verified questions for effectively assessing LLMs' cultural knowledge, covering 45 global regions including the underrepresented ones like Bangladesh, Zimbabwe, and Peru. Questions - each verified by five independent annotators - span 17 diverse topics ranging from food preferences to greeting etiquettes. We evaluate models on two setups: CulturalBench-Easy and CulturalBench-Hard which share the same questions but asked differently. We find that LLMs are sensitive to such difference in setups (e.g., GPT-4o with 27.3% difference). Compared to human performance (92.6% accuracy), CulturalBench-Hard is more challenging for frontier LLMs with the best performing model (GPT-4o) at only 61.5% and the worst (Llama3-8b) at 21.4%. Moreover, we find that LLMs often struggle with tricky questions that have multiple correct answers (e.g., What utensils do the Chinese usually use?), revealing a tendency to converge to a single answer. Our results also indicate that OpenAI GPT-4o substantially outperform other proprietary and open source models in questions related to all but one region (Oceania). Nonetheless, all models consistently underperform on questions related to South America and the Middle East.