 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes ChatGPT Have a Poetic Style?
Oct 20, 2024
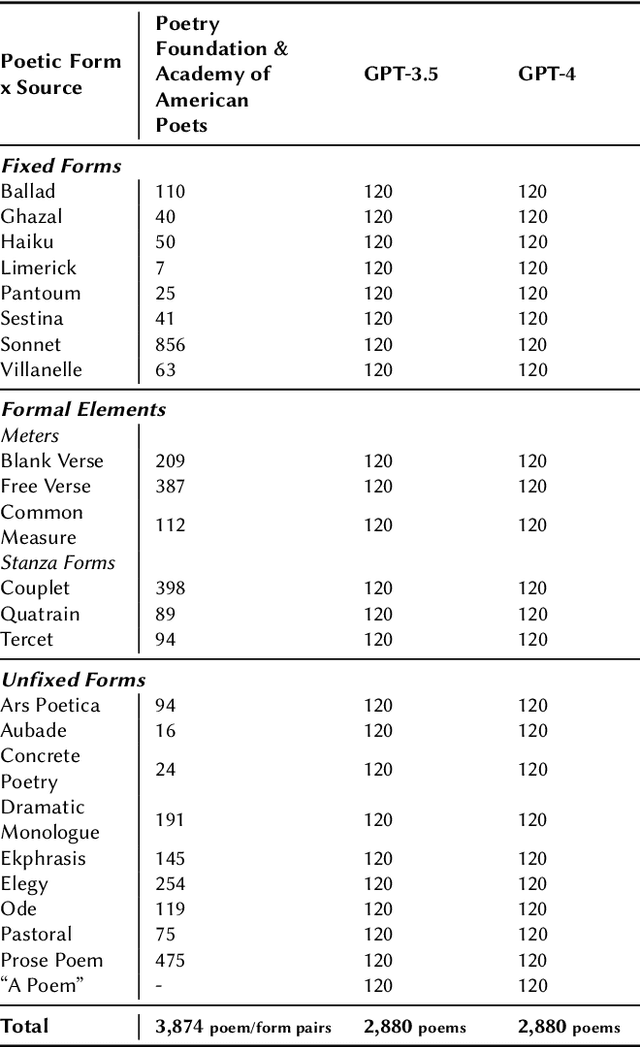

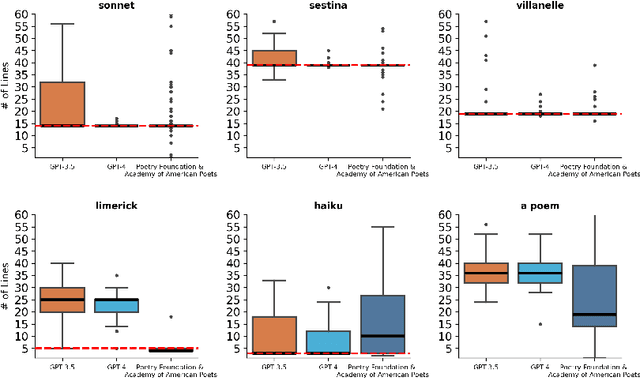
Generating poetry has become a popular application of LLMs, perhaps especially of OpenAI's widely-used chatbot ChatGPT. What kind of poet is ChatGPT? Does ChatGPT have its own poetic style? Can it successfully produce poems in different styles? To answer these questions, we prompt the GPT-3.5 and GPT-4 models to generate English-language poems in 24 different poetic forms and styles, about 40 different subjects, and in response to 3 different writing prompt templates. We then analyze the resulting 5.7k poems, comparing them to a sample of 3.7k poems from the Poetry Foundation and the Academy of American Poets. We find that the GPT models, especially GPT-4, can successfully produce poems in a range of both common and uncommon English-language forms in superficial yet noteworthy ways, such as by producing poems of appropriate lengths for sonnets (14 lines), villanelles (19 lines), and sestinas (39 lines). But the GPT models also exhibit their own distinct stylistic tendencies, both within and outside of these specific forms. Our results show that GPT poetry is much more constrained and uniform than human poetry, showing a strong penchant for rhyme, quatrains (4-line stanzas), iambic meter, first-person plural perspectives (we, us, our), and specific vocabulary like "heart," "embrace," "echo," and "whisper."
* CHR 2024: Computational Humanities Research Conference
Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets
Jun 27, 2024Large language models (LLMs) can now generate and recognize text in a wide range of styles and genres, including highly specialized, creative genres like poetry. But what do LLMs really know about poetry? What can they know about poetry? We develop a task to evaluate how well LLMs recognize a specific aspect of poetry, poetic form, for more than 20 forms and formal elements in the English language. Poetic form captures many different poetic features, including rhyme scheme, meter, and word or line repetition. We use this task to reflect on LLMs' current poetic capabilities, as well as the challenges and pitfalls of creating NLP benchmarks for poetry and for other creative tasks. In particular, we use this task to audit and reflect on the poems included in popular pretraining datasets. Our findings have implications for NLP researchers interested in model evaluation, digital humanities and cultural analytics scholars, and cultural heritage professionals.