 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrospective X Training: Feedback Conditioning Improves Scaling Across all LLM Training Stages
May 19, 2026We tackle the question of how to scale more efficiently across the many, ever-growing stages of current LLM training pipelines. Our guiding intuition stems from the fact that the dynamics of later stages of the pipeline, e.g. post-training, can be used to inform earlier stages such as pre-training. To this end, we propose Introspective Training (or IXT), inspired by offline reward-conditioned reinforcement learning and applicable to any stage of training. IXT uses a thinking reward model to annotate data with natural language critique based feedback, enabling quality aware training from the earliest stages of the pipeline. Models are then trained by prefix-conditioning the data with the generated feedback -- ensuring that not all tokens are treated equally starting much earlier in training than usual. Comprehensive experiments on 7.5-12B transformer-based dense LLMs trained from scratch all the way up to 18 Trillion tokens seen show that our method: bends scaling curves resulting in up to 2.8x more compute efficiency generally; and reaches performance levels unachievable for models trained otherwise in domains such as math and code.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Mar 19, 2026Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.
iGRPO: Self-Feedback-Driven LLM Reasoning
Feb 09, 2026Large Language Models (LLMs) have shown promise in solving complex mathematical problems, yet they still fall short of producing accurate and consistent solutions. Reinforcement Learning (RL) is a framework for aligning these models with task-specific rewards, improving overall quality and reliability. Group Relative Policy Optimization (GRPO) is an efficient, value-function-free alternative to Proximal Policy Optimization (PPO) that leverages group-relative reward normalization. We introduce Iterative Group Relative Policy Optimization (iGRPO), a two-stage extension of GRPO that adds dynamic self-conditioning through model-generated drafts. In Stage 1, iGRPO samples multiple exploratory drafts and selects the highest-reward draft using the same scalar reward signal used for optimization. In Stage 2, it appends this best draft to the original prompt and applies a GRPO-style update on draft-conditioned refinements, training the policy to improve beyond its strongest prior attempt. Under matched rollout budgets, iGRPO consistently outperforms GRPO across base models (e.g., Nemotron-H-8B-Base-8K and DeepSeek-R1 Distilled), validating its effectiveness on diverse reasoning benchmarks. Moreover, applying iGRPO to OpenReasoning-Nemotron-7B trained on AceReason-Math achieves new state-of-the-art results of 85.62\% and 79.64\% on AIME24 and AIME25, respectively. Ablations further show that the refinement wrapper generalizes beyond GRPO variants, benefits from a generative judge, and alters learning dynamics by delaying entropy collapse. These results underscore the potential of iterative, self-feedback-based RL for advancing verifiable mathematical reasoning.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
Long Grounded Thoughts: Distilling Compositional Visual Reasoning Chains at Scale
Nov 07, 2025Recent progress in multimodal reasoning has been driven largely by undisclosed datasets and proprietary data synthesis recipes, leaving open questions about how to systematically build large-scale, vision-centric reasoning datasets, particularly for tasks that go beyond visual math. In this work, we introduce a new reasoning data generation framework spanning diverse skills and levels of complexity with over 1M high-quality synthetic vision-centric questions. The dataset also includes preference data and instruction prompts supporting both offline and online RL. Our synthesis framework proceeds in two stages: (1) scale; and (2) complexity. Reasoning traces are then synthesized through a two-stage process that leverages VLMs and reasoning LLMs, producing CoT traces for VLMs that capture the richness and diverse cognitive behaviors found in frontier reasoning models. Remarkably, we show that finetuning Qwen2.5-VL-7B on our data outperforms all open-data baselines across all evaluated vision-centric benchmarks, and even surpasses strong closed-data models such as MiMo-VL-7B-RL on V* Bench, CV-Bench and MMStar-V. Perhaps most surprising, despite being entirely vision-centric, our data transfers positively to text-only reasoning (MMLU-Pro) and audio reasoning (MMAU), demonstrating its effectiveness. Similarly, despite not containing videos or embodied visual data, we observe notable gains when evaluating on a single-evidence embodied QA benchmark (NiEH). Finally, we use our data to analyze the entire VLM post-training pipeline. Our empirical analysis highlights that (i) SFT on high-quality data with non-linear reasoning traces is essential for effective online RL, (ii) staged offline RL matches online RL's performance while reducing compute demands, and (iii) careful SFT on high quality data can substantially improve out-of-domain, cross-modality transfer.
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Oct 21, 2025

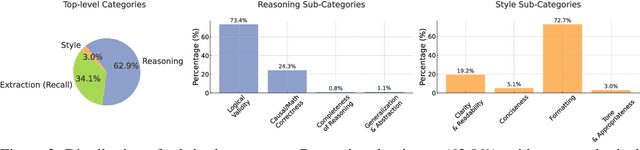

Evaluating progress in large language models (LLMs) is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9\% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench
Bias in Gender Bias Benchmarks: How Spurious Features Distort Evaluation
Sep 09, 2025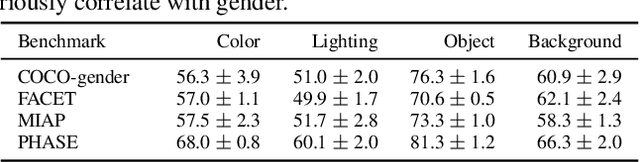

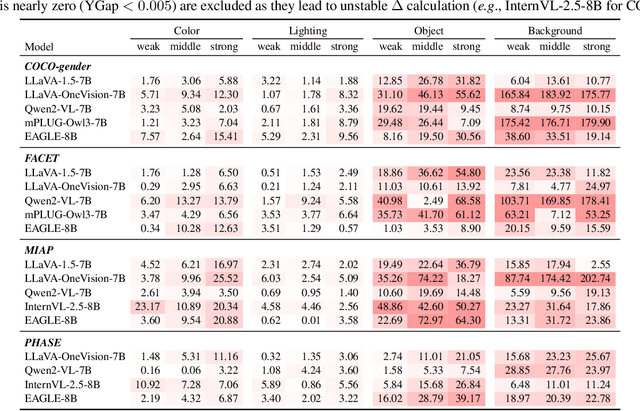

Gender bias in vision-language foundation models (VLMs) raises concerns about their safe deployment and is typically evaluated using benchmarks with gender annotations on real-world images. However, as these benchmarks often contain spurious correlations between gender and non-gender features, such as objects and backgrounds, we identify a critical oversight in gender bias evaluation: Do spurious features distort gender bias evaluation? To address this question, we systematically perturb non-gender features across four widely used benchmarks (COCO-gender, FACET, MIAP, and PHASE) and various VLMs to quantify their impact on bias evaluation. Our findings reveal that even minimal perturbations, such as masking just 10% of objects or weakly blurring backgrounds, can dramatically alter bias scores, shifting metrics by up to 175% in generative VLMs and 43% in CLIP variants. This suggests that current bias evaluations often reflect model responses to spurious features rather than gender bias, undermining their reliability. Since creating spurious feature-free benchmarks is fundamentally challenging, we recommend reporting bias metrics alongside feature-sensitivity measurements to enable a more reliable bias assessment.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact Verifiers
Jun 16, 2025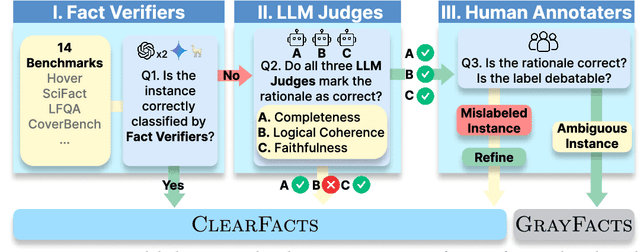

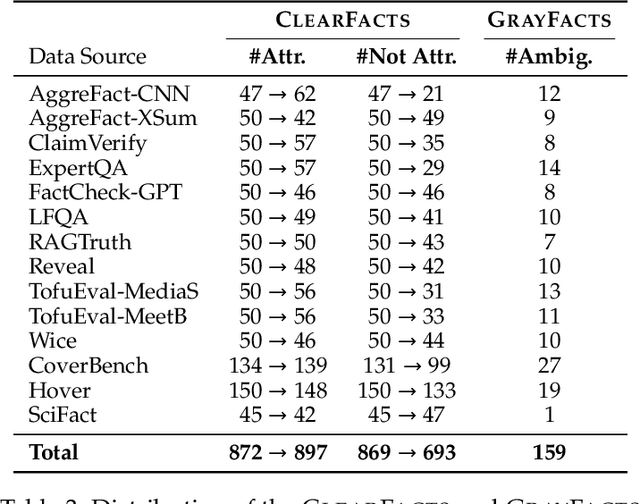
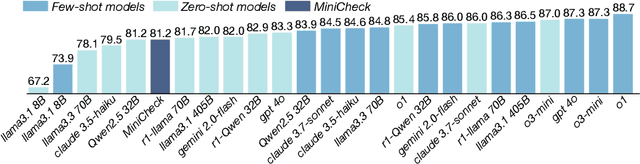
Fact verification is essential for ensuring the reliability of LLM applications. In this study, we evaluate 12 pre-trained LLMs and one specialized fact-verifier, including frontier LLMs and open-weight reasoning LLMs, using a collection of examples from 14 fact-checking benchmarks. We share three findings intended to guide future development of more robust fact verifiers. First, we highlight the importance of addressing annotation errors and ambiguity in datasets, demonstrating that approximately 16\% of ambiguous or incorrectly labeled data substantially influences model rankings. Neglecting this issue may result in misleading conclusions during comparative evaluations, and we suggest using a systematic pipeline utilizing LLM-as-a-judge to help identify these issues at scale. Second, we discover that frontier LLMs with few-shot in-context examples, often overlooked in previous works, achieve top-tier performance. We therefore recommend future studies include comparisons with these simple yet highly effective baselines. Lastly, despite their effectiveness, frontier LLMs incur substantial costs, motivating the development of small, fine-tuned fact verifiers. We show that these small models still have room for improvement, particularly on instances that require complex reasoning. Encouragingly, we demonstrate that augmenting training with synthetic multi-hop reasoning data significantly enhances their capabilities in such instances. We release our code, model, and dataset at https://github.com/just1nseo/verifying-the-verifiers