 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmulet: Putting Complex Multi-Turn Conversations on the Stand with LLM Juries
May 26, 2025


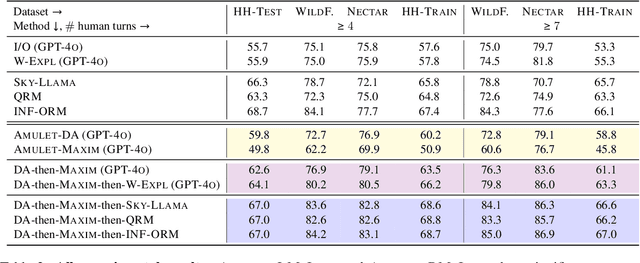
Today, large language models are widely used as judges to evaluate responses from other language models. Hence, it is imperative to benchmark and improve these LLM-judges on real-world language model usage: a typical human-assistant conversation is lengthy, and shows significant diversity in topics, intents, and requirements across turns, e.g. social interactions, task requests, feedback. We present Amulet, a framework that leverages pertinent linguistic concepts of dialog-acts and maxims to improve the accuracy of LLM-judges on preference data with complex, multi-turn conversational context. Amulet presents valuable insights about (a) the communicative structures and intents present in the conversation (dialog acts), and (b) the satisfaction of conversational principles (maxims) by the preference responses, and uses them to make judgments. On four challenging datasets, Amulet shows that (a) humans frequently (60 to 70 percent of the time) change their intents from one turn of the conversation to the next, and (b) in 75 percent of instances, the preference responses can be differentiated via dialog acts and/or maxims, reiterating the latter's significance in judging such data. Amulet can be used either as a judge by applying the framework to a single LLM, or integrated into a jury with different LLM judges; our judges and juries show strong improvements on relevant baselines for all four datasets.
Prismatic Synthesis: Gradient-based Data Diversification Boosts Generalization in LLM Reasoning
May 26, 2025Effective generalization in language models depends critically on the diversity of their training data. Yet existing diversity metrics often fall short of this goal, relying on surface-level heuristics that are decoupled from model behavior. This motivates us to ask: What kind of diversity in training data actually drives generalization in language models -- and how can we measure and amplify it? Through large-scale empirical analyses spanning over 300 training runs, carefully controlled for data scale and quality, we show that data diversity can be a strong predictor of generalization in LLM reasoning -- as measured by average model performance on unseen out-of-distribution benchmarks. We introduce G-Vendi, a metric that quantifies diversity via the entropy of model-induced gradients. Despite using a small off-the-shelf proxy model for gradients, G-Vendi consistently outperforms alternative measures, achieving strong correlation (Spearman's $\rho \approx 0.9$) with out-of-distribution (OOD) performance on both natural language inference (NLI) and math reasoning tasks. Building on this insight, we present Prismatic Synthesis, a framework for generating diverse synthetic data by targeting underrepresented regions in gradient space. Experimental results show that Prismatic Synthesis consistently improves model performance as we scale synthetic data -- not just on in-distribution test but across unseen, out-of-distribution benchmarks -- significantly outperforming state-of-the-art models that rely on 20 times larger data generator than ours. For example, PrismMath-7B, our model distilled from a 32B LLM, outperforms R1-Distill-Qwen-7B -- the same base model trained on proprietary data generated by 671B R1 -- on 6 out of 7 challenging benchmarks.
AI as Humanity's Salieri: Quantifying Linguistic Creativity of Language Models via Systematic Attribution of Machine Text against Web Text
Oct 05, 2024Creativity has long been considered one of the most difficult aspect of human intelligence for AI to mimic. However, the rise of Large Language Models (LLMs), like ChatGPT, has raised questions about whether AI can match or even surpass human creativity. We present CREATIVITY INDEX as the first step to quantify the linguistic creativity of a text by reconstructing it from existing text snippets on the web. CREATIVITY INDEX is motivated by the hypothesis that the seemingly remarkable creativity of LLMs may be attributable in large part to the creativity of human-written texts on the web. To compute CREATIVITY INDEX efficiently, we introduce DJ SEARCH, a novel dynamic programming algorithm that can search verbatim and near-verbatim matches of text snippets from a given document against the web. Experiments reveal that the CREATIVITY INDEX of professional human authors is on average 66.2% higher than that of LLMs, and that alignment reduces the CREATIVITY INDEX of LLMs by an average of 30.1%. In addition, we find that distinguished authors like Hemingway exhibit measurably higher CREATIVITY INDEX compared to other human writers. Finally, we demonstrate that CREATIVITY INDEX can be used as a surprisingly effective criterion for zero-shot machine text detection, surpassing the strongest existing zero-shot system, DetectGPT, by a significant margin of 30.2%, and even outperforming the strongest supervised system, GhostBuster, in five out of six domains.
StyleRemix: Interpretable Authorship Obfuscation via Distillation and Perturbation of Style Elements
Aug 28, 2024



Authorship obfuscation, rewriting a text to intentionally obscure the identity of the author, is an important but challenging task. Current methods using large language models (LLMs) lack interpretability and controllability, often ignoring author-specific stylistic features, resulting in less robust performance overall. To address this, we develop StyleRemix, an adaptive and interpretable obfuscation method that perturbs specific, fine-grained style elements of the original input text. StyleRemix uses pre-trained Low Rank Adaptation (LoRA) modules to rewrite an input specifically along various stylistic axes (e.g., formality and length) while maintaining low computational cost. StyleRemix outperforms state-of-the-art baselines and much larger LLMs in a variety of domains as assessed by both automatic and human evaluation. Additionally, we release AuthorMix, a large set of 30K high-quality, long-form texts from a diverse set of 14 authors and 4 domains, and DiSC, a parallel corpus of 1,500 texts spanning seven style axes in 16 unique directions
STEER: Unified Style Transfer with Expert Reinforcement
Nov 13, 2023



While text style transfer has many applications across natural language processing, the core premise of transferring from a single source style is unrealistic in a real-world setting. In this work, we focus on arbitrary style transfer: rewriting a text from an arbitrary, unknown style to a target style. We propose STEER: Unified Style Transfer with Expert Reinforcement, a unified frame-work developed to overcome the challenge of limited parallel data for style transfer. STEER involves automatically generating a corpus of style-transfer pairs using a product of experts during decoding. The generated offline data is then used to pre-train an initial policy before switching to online, off-policy reinforcement learning for further improvements via fine-grained reward signals. STEER is unified and can transfer to multiple target styles from an arbitrary, unknown source style, making it particularly flexible and efficient. Experimental results on a challenging dataset with text from a diverse set of styles demonstrate state-of-the-art results compared to competitive baselines. Remarkably, STEER outperforms the 175B parameter instruction-tuned GPT-3 on overall style transfer quality, despite being 226 times smaller in size. We also show STEER is robust, maintaining its style transfer capabilities on out-of-domain data, and surpassing nearly all baselines across various styles. The success of our method highlights the potential of RL algorithms when augmented with controllable decoding to overcome the challenge of limited data supervision.
Tailoring Self-Rationalizers with Multi-Reward Distillation
Nov 06, 2023Large language models (LMs) are capable of generating free-text rationales to aid question answering. However, prior work 1) suggests that useful self-rationalization is emergent only at significant scales (e.g., 175B parameter GPT-3); and 2) focuses largely on downstream performance, ignoring the semantics of the rationales themselves, e.g., are they faithful, true, and helpful for humans? In this work, we enable small-scale LMs (approx. 200x smaller than GPT-3) to generate rationales that not only improve downstream task performance, but are also more plausible, consistent, and diverse, assessed both by automatic and human evaluation. Our method, MaRio (Multi-rewArd RatIOnalization), is a multi-reward conditioned self-rationalization algorithm that optimizes multiple distinct properties like plausibility, diversity and consistency. Results on five difficult question-answering datasets StrategyQA, QuaRel, OpenBookQA, NumerSense and QASC show that not only does MaRio improve task accuracy, but it also improves the self-rationalization quality of small LMs across the aforementioned axes better than a supervised fine-tuning (SFT) baseline. Extensive human evaluations confirm that MaRio rationales are preferred vs. SFT rationales, as well as qualitative improvements in plausibility and consistency.
Inference-Time Policy Adapters (IPA): Tailoring Extreme-Scale LMs without Fine-tuning
May 24, 2023Large language models excel at a variety of language tasks when prompted with examples or instructions. Yet controlling these models through prompting alone is limited. Tailoring language models through fine-tuning (e.g., via reinforcement learning) can be effective, but it is expensive and requires model access. We propose Inference-time Policy Adapters (IPA), which efficiently tailors a language model such as GPT-3 without fine-tuning it. IPA guides a large base model during decoding time through a lightweight policy adaptor trained to optimize an arbitrary user objective with reinforcement learning. On five challenging text generation tasks, such as toxicity reduction and open-domain generation, IPA consistently brings significant improvements over off-the-shelf language models. It outperforms competitive baseline methods, sometimes even including expensive fine-tuning. In particular, tailoring GPT-2 with IPA can outperform GPT-3, while tailoring GPT- 3 with IPA brings a major performance boost over GPT-3 (and sometimes even over GPT-4). Our promising results highlight the potential of IPA as a lightweight alternative to tailoring extreme-scale language models.
Self-Refine: Iterative Refinement with Self-Feedback
Mar 30, 2023



Like people, LLMs do not always generate the best text for a given generation problem on their first try (e.g., summaries, answers, explanations). Just as people then refine their text, we introduce SELF-REFINE, a framework for similarly improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an output using an LLM, then allow the same model to provide multi-aspect feedback for its own output; finally, the same model refines its previously generated output given its own feedback. Unlike earlier work, our iterative refinement framework does not require supervised training data or reinforcement learning, and works with a single LLM. We experiment with 7 diverse tasks, ranging from review rewriting to math reasoning, demonstrating that our approach outperforms direct generation. In all tasks, outputs generated with SELF-REFINE are preferred by humans and by automated metrics over those generated directly with GPT-3.5 and GPT-4, improving on average by absolute 20% across tasks.
Detoxifying Text with MaRCo: Controllable Revision with Experts and Anti-Experts
Dec 20, 2022



Text detoxification has the potential to mitigate the harms of toxicity by rephrasing text to remove offensive meaning, but subtle toxicity remains challenging to tackle. We introduce MaRCo, a detoxification algorithm that combines controllable generation and text rewriting methods using a Product of Experts with autoencoder language models (LMs). MaRCo uses likelihoods under a non-toxic LM (expert) and a toxic LM (anti-expert) to find candidate words to mask and potentially replace. We evaluate our method on several subtle toxicity and microaggressions datasets, and show that it not only outperforms baselines on automatic metrics, but MaRCo's rewrites are preferred 2.1 $\times$ more in human evaluation. Its applicability to instances of subtle toxicity is especially promising, demonstrating a path forward for addressing increasingly elusive online hate.
Rainier: Reinforced Knowledge Introspector for Commonsense Question Answering
Oct 06, 2022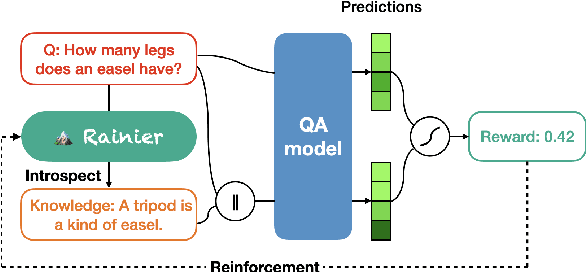
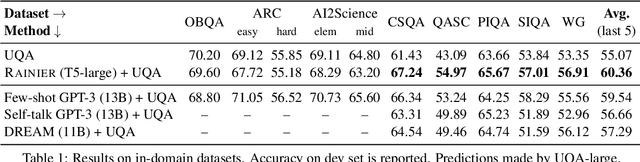
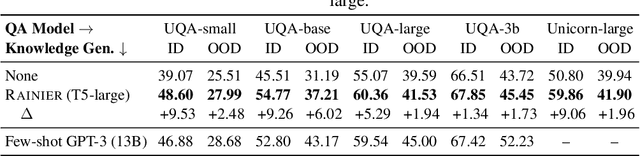

Knowledge underpins reasoning. Recent research demonstrates that when relevant knowledge is provided as additional context to commonsense question answering (QA), it can substantially enhance the performance even on top of state-of-the-art. The fundamental challenge is where and how to find such knowledge that is high quality and on point with respect to the question; knowledge retrieved from knowledge bases are incomplete and knowledge generated from language models are inconsistent. We present Rainier, or Reinforced Knowledge Introspector, that learns to generate contextually relevant knowledge in response to given questions. Our approach starts by imitating knowledge generated by GPT-3, then learns to generate its own knowledge via reinforcement learning where rewards are shaped based on the increased performance on the resulting question answering. Rainier demonstrates substantial and consistent performance gains when tested over 9 different commonsense benchmarks: including 5 in-domain benchmarks that are seen during reinforcement learning, as well as 4 out-of-domain benchmarks that are kept unseen. Our work is the first to report that knowledge generated by models that are orders of magnitude smaller than GPT-3, even without direct supervision on the knowledge itself, can exceed the quality of knowledge elicited from GPT-3 for commonsense QA.