 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating the Untranslatable: An Operationalizable Ontology for Untranslatability
Jun 15, 2026Untranslatability, cases where meaning cannot be directly preserved across languages, is well-studied in linguistics but underexplored in NLP. As machine translation (MT) systems improve on standard benchmarks, their limitations increasingly concentrate in such cases, where translation cannot be reduced to one-to-one equivalence. We introduce a structured ontology of untranslatability along with a taxonomy of compensation strategies, which are specific techniques to convey meaning under these untranslatable circumstances. We operationalize this framework into a multilingual dataset of untranslatable sentences paired with strategy-based translations, enabling controlled analysis of translation behavior. Initial human preference studies suggest that translation quality depends on the strategy used, with consistent preferences for outputs that include explanatory context, known as the Annotation compensation strategy. Our framework and dataset provide a foundation for studying and modeling strategy-informed machine translation.
ELI-Why: Evaluating the Pedagogical Utility of Language Model Explanations
Jun 17, 2025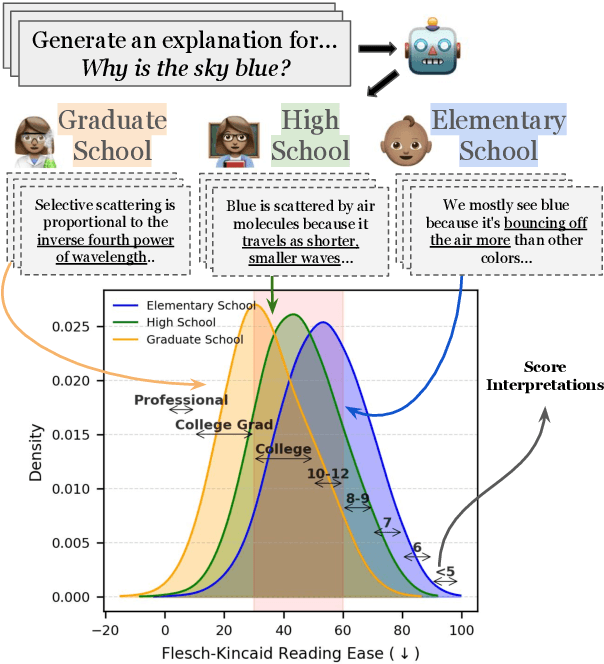
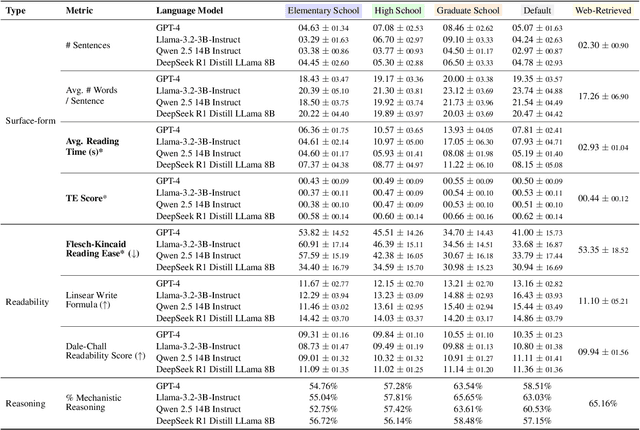
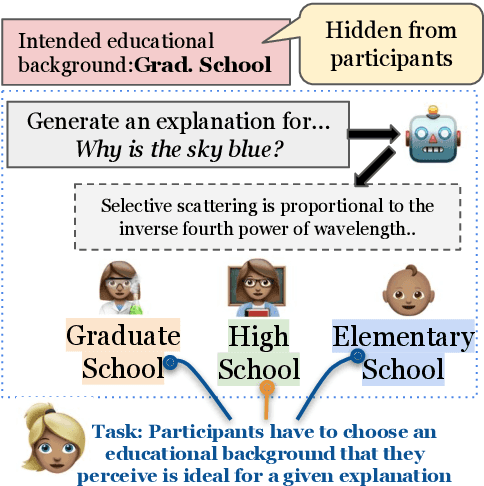

Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-Why, a benchmark of 13.4K "Why" questions to evaluate the pedagogical capabilities of language models. We then conduct two extensive human studies to assess the utility of language model-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations' fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for lay human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Across all educational backgrounds, users deemed GPT-4-generated explanations 20% less suited on average to their informational needs, when compared to explanations curated by lay people. Additionally, automated evaluation metrics reveal that explanations generated across different language model families for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness.
Amulet: Putting Complex Multi-Turn Conversations on the Stand with LLM Juries
May 26, 2025


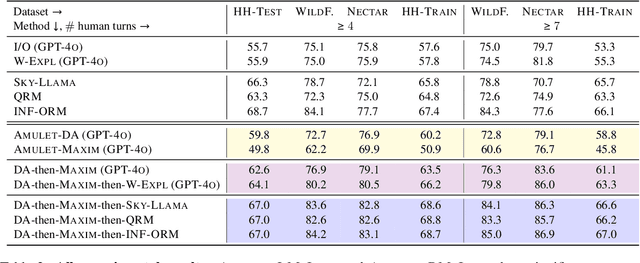
Today, large language models are widely used as judges to evaluate responses from other language models. Hence, it is imperative to benchmark and improve these LLM-judges on real-world language model usage: a typical human-assistant conversation is lengthy, and shows significant diversity in topics, intents, and requirements across turns, e.g. social interactions, task requests, feedback. We present Amulet, a framework that leverages pertinent linguistic concepts of dialog-acts and maxims to improve the accuracy of LLM-judges on preference data with complex, multi-turn conversational context. Amulet presents valuable insights about (a) the communicative structures and intents present in the conversation (dialog acts), and (b) the satisfaction of conversational principles (maxims) by the preference responses, and uses them to make judgments. On four challenging datasets, Amulet shows that (a) humans frequently (60 to 70 percent of the time) change their intents from one turn of the conversation to the next, and (b) in 75 percent of instances, the preference responses can be differentiated via dialog acts and/or maxims, reiterating the latter's significance in judging such data. Amulet can be used either as a judge by applying the framework to a single LLM, or integrated into a jury with different LLM judges; our judges and juries show strong improvements on relevant baselines for all four datasets.
Improving LLM Personas via Rationalization with Psychological Scaffolds
Apr 25, 2025Language models prompted with a user description or persona can predict a user's preferences and opinions, but existing approaches to building personas -- based solely on a user's demographic attributes and/or prior judgments -- fail to capture the underlying reasoning behind said user judgments. We introduce PB&J (Psychology of Behavior and Judgments), a framework that improves LLM personas by incorporating rationales of why a user might make specific judgments. These rationales are LLM-generated, and aim to reason about a user's behavior on the basis of their experiences, personality traits or beliefs. This is done using psychological scaffolds -- structured frameworks grounded in theories such as the Big 5 Personality Traits and Primal World Beliefs -- that help provide structure to the generated rationales. Experiments on public opinion and movie preference prediction tasks demonstrate that LLM personas augmented with PB&J rationales consistently outperform methods using only a user's demographics and/or judgments. Additionally, LLM personas constructed using scaffolds describing user beliefs perform competitively with those using human-written rationales.
CoKe: Customizable Fine-Grained Story Evaluation via Chain-of-Keyword Rationalization
Mar 21, 2025Evaluating creative text such as human-written stories using language models has always been a challenging task -- owing to the subjectivity of multi-annotator ratings. To mimic the thinking process of humans, chain of thought (CoT) generates free-text explanations that help guide a model's predictions and Self-Consistency (SC) marginalizes predictions over multiple generated explanations. In this study, we discover that the widely-used self-consistency reasoning methods cause suboptimal results due to an objective mismatch between generating 'fluent-looking' explanations vs. actually leading to a good rating prediction for an aspect of a story. To overcome this challenge, we propose $\textbf{C}$hain-$\textbf{o}$f-$\textbf{Ke}$ywords (CoKe), that generates a sequence of keywords $\textit{before}$ generating a free-text rationale, that guide the rating prediction of our evaluation language model. Then, we generate a diverse set of such keywords, and aggregate the scores corresponding to these generations. On the StoryER dataset, CoKe based on our small fine-tuned evaluation models not only reach human-level performance and significantly outperform GPT-4 with a 2x boost in correlation with human annotators, but also requires drastically less number of parameters.
OATH-Frames: Characterizing Online Attitudes Towards Homelessness with LLM Assistants
Jun 21, 2024



Warning: Contents of this paper may be upsetting. Public attitudes towards key societal issues, expressed on online media, are of immense value in policy and reform efforts, yet challenging to understand at scale. We study one such social issue: homelessness in the U.S., by leveraging the remarkable capabilities of large language models to assist social work experts in analyzing millions of posts from Twitter. We introduce a framing typology: Online Attitudes Towards Homelessness (OATH) Frames: nine hierarchical frames capturing critiques, responses and perceptions. We release annotations with varying degrees of assistance from language models, with immense benefits in scaling: 6.5x speedup in annotation time while only incurring a 3 point F1 reduction in performance with respect to the domain experts. Our experiments demonstrate the value of modeling OATH-Frames over existing sentiment and toxicity classifiers. Our large-scale analysis with predicted OATH-Frames on 2.4M posts on homelessness reveal key trends in attitudes across states, time periods and vulnerable populations, enabling new insights on the issue. Our work provides a general framework to understand nuanced public attitudes at scale, on issues beyond homelessness.
Tailoring Self-Rationalizers with Multi-Reward Distillation
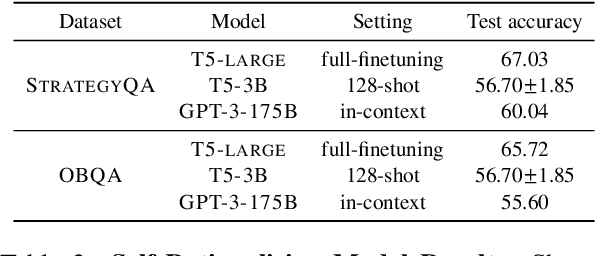
Nov 06, 2023Large language models (LMs) are capable of generating free-text rationales to aid question answering. However, prior work 1) suggests that useful self-rationalization is emergent only at significant scales (e.g., 175B parameter GPT-3); and 2) focuses largely on downstream performance, ignoring the semantics of the rationales themselves, e.g., are they faithful, true, and helpful for humans? In this work, we enable small-scale LMs (approx. 200x smaller than GPT-3) to generate rationales that not only improve downstream task performance, but are also more plausible, consistent, and diverse, assessed both by automatic and human evaluation. Our method, MaRio (Multi-rewArd RatIOnalization), is a multi-reward conditioned self-rationalization algorithm that optimizes multiple distinct properties like plausibility, diversity and consistency. Results on five difficult question-answering datasets StrategyQA, QuaRel, OpenBookQA, NumerSense and QASC show that not only does MaRio improve task accuracy, but it also improves the self-rationalization quality of small LMs across the aforementioned axes better than a supervised fine-tuning (SFT) baseline. Extensive human evaluations confirm that MaRio rationales are preferred vs. SFT rationales, as well as qualitative improvements in plausibility and consistency.
Are Machine Rationales (Not) Useful to Humans? Measuring and Improving Human Utility of Free-Text Rationales
May 11, 2023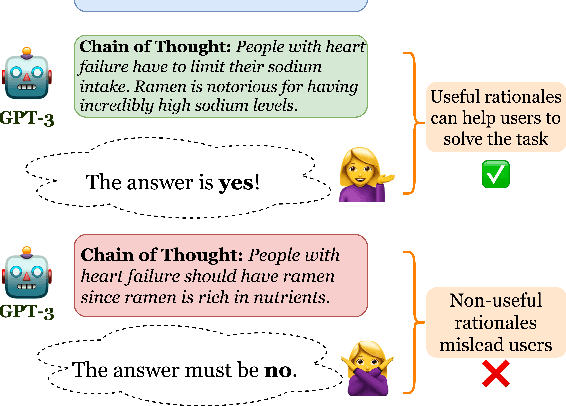


Among the remarkable emergent capabilities of large language models (LMs) is free-text rationalization; beyond a certain scale, large LMs are capable of generating seemingly useful rationalizations, which in turn, can dramatically enhance their performances on leaderboards. This phenomenon raises a question: can machine generated rationales also be useful for humans, especially when lay humans try to answer questions based on those machine rationales? We observe that human utility of existing rationales is far from satisfactory, and expensive to estimate with human studies. Existing metrics like task performance of the LM generating the rationales, or similarity between generated and gold rationales are not good indicators of their human utility. While we observe that certain properties of rationales like conciseness and novelty are correlated with their human utility, estimating them without human involvement is challenging. We show that, by estimating a rationale's helpfulness in answering similar unseen instances, we can measure its human utility to a better extent. We also translate this finding into an automated score, GEN-U, that we propose, which can help improve LMs' ability to generate rationales with better human utility, while maintaining most of its task performance. Lastly, we release all code and collected data with this project.
KNIFE: Knowledge Distillation with Free-Text Rationales
Dec 19, 2022Free-text rationales (FTRs) follow how humans communicate by explaining reasoning processes via natural language. A number of recent works have studied how to improve language model (LM) generalization by using FTRs to teach LMs the correct reasoning processes behind correct task outputs. These prior works aim to learn from FTRs by appending them to the LM input or target output, but this may introduce an input distribution shift or conflict with the task objective, respectively. We propose KNIFE, which distills FTR knowledge from an FTR-augmented teacher LM (takes both task input and FTR) to a student LM (takes only task input), which is used for inference. Crucially, the teacher LM's forward computation has a bottleneck stage in which all of its FTR states are masked out, which pushes knowledge from the FTR states into the task input/output states. Then, FTR knowledge is distilled to the student LM by training its task input/output states to align with the teacher LM's. On two question answering datasets, we show that KNIFE significantly outperforms existing FTR learning methods, in both fully-supervised and low-resource settings.
XMD: An End-to-End Framework for Interactive Explanation-Based Debugging of NLP Models
Oct 30, 2022NLP models are susceptible to learning spurious biases (i.e., bugs) that work on some datasets but do not properly reflect the underlying task. Explanation-based model debugging aims to resolve spurious biases by showing human users explanations of model behavior, asking users to give feedback on the behavior, then using the feedback to update the model. While existing model debugging methods have shown promise, their prototype-level implementations provide limited practical utility. Thus, we propose XMD: the first open-source, end-to-end framework for explanation-based model debugging. Given task- or instance-level explanations, users can flexibly provide various forms of feedback via an intuitive, web-based UI. After receiving user feedback, XMD automatically updates the model in real time, by regularizing the model so that its explanations align with the user feedback. The new model can then be easily deployed into real-world applications via Hugging Face. Using XMD, we can improve the model's OOD performance on text classification tasks by up to 18%.