 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXMD: An End-to-End Framework for Interactive Explanation-Based Debugging of NLP Models
Oct 30, 2022NLP models are susceptible to learning spurious biases (i.e., bugs) that work on some datasets but do not properly reflect the underlying task. Explanation-based model debugging aims to resolve spurious biases by showing human users explanations of model behavior, asking users to give feedback on the behavior, then using the feedback to update the model. While existing model debugging methods have shown promise, their prototype-level implementations provide limited practical utility. Thus, we propose XMD: the first open-source, end-to-end framework for explanation-based model debugging. Given task- or instance-level explanations, users can flexibly provide various forms of feedback via an intuitive, web-based UI. After receiving user feedback, XMD automatically updates the model in real time, by regularizing the model so that its explanations align with the user feedback. The new model can then be easily deployed into real-world applications via Hugging Face. Using XMD, we can improve the model's OOD performance on text classification tasks by up to 18%.
Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER
Oct 16, 2021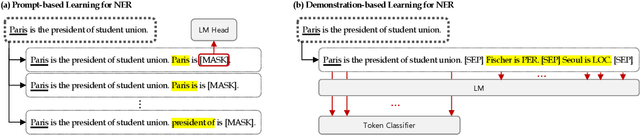
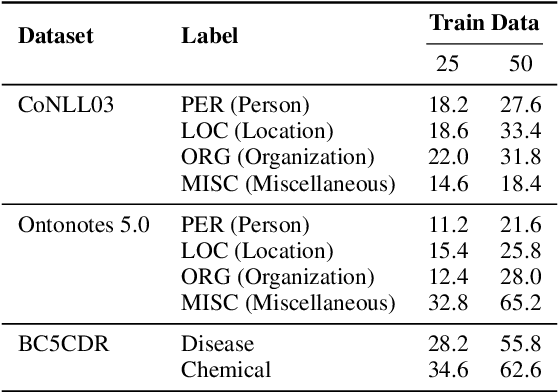

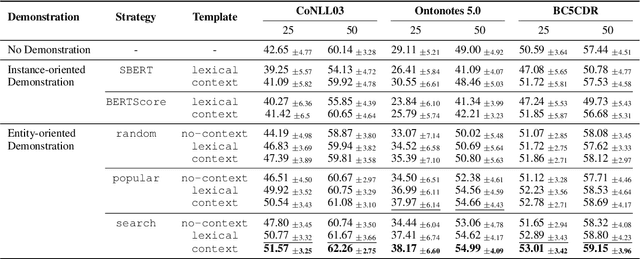
Recent advances in prompt-based learning have shown impressive results on few-shot text classification tasks by using cloze-style language prompts. There have been attempts on prompt-based learning for NER which use manually designed templates to predict entity types. However, these two-step methods may suffer from error propagation (from entity span detection), need to prompt for all possible text spans which is costly, and neglect the interdependency when predicting labels for different spans in a sentence. In this paper, we present a simple demonstration-based learning method for NER, which augments the prompt (learning context) with a few task demonstrations. Such demonstrations help the model learn the task better under low-resource settings and allow for span detection and classification over all tokens jointly. Here, we explore entity-oriented demonstration which selects an appropriate entity example per each entity type, and instance-oriented demonstration which retrieves a similar instance example. Through extensive experiments, we find empirically that showing entity example per each entity type, along with its example sentence, can improve the performance both in in-domain and cross-domain settings by 1-3 F1 score.