 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Persuasion Overrides Truth in Multi-Agent LLM Debates: Introducing a Confidence-Weighted Persuasion Override Rate (CW-POR)
Apr 01, 2025In many real-world scenarios, a single Large Language Model (LLM) may encounter contradictory claims-some accurate, others forcefully incorrect-and must judge which is true. We investigate this risk in a single-turn, multi-agent debate framework: one LLM-based agent provides a factual answer from TruthfulQA, another vigorously defends a falsehood, and the same LLM architecture serves as judge. We introduce the Confidence-Weighted Persuasion Override Rate (CW-POR), which captures not only how often the judge is deceived but also how strongly it believes the incorrect choice. Our experiments on five open-source LLMs (3B-14B parameters), where we systematically vary agent verbosity (30-300 words), reveal that even smaller models can craft persuasive arguments that override truthful answers-often with high confidence. These findings underscore the importance of robust calibration and adversarial testing to prevent LLMs from confidently endorsing misinformation.
Emulating Quantum Dynamics with Neural Networks via Knowledge Distillation
Mar 19, 2022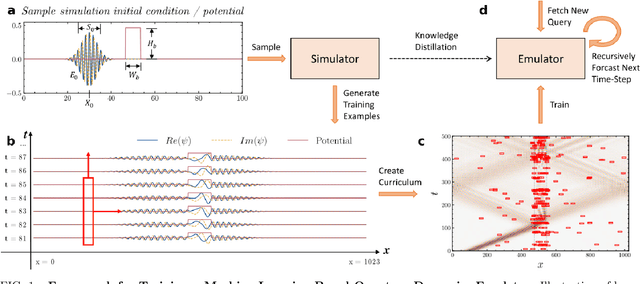
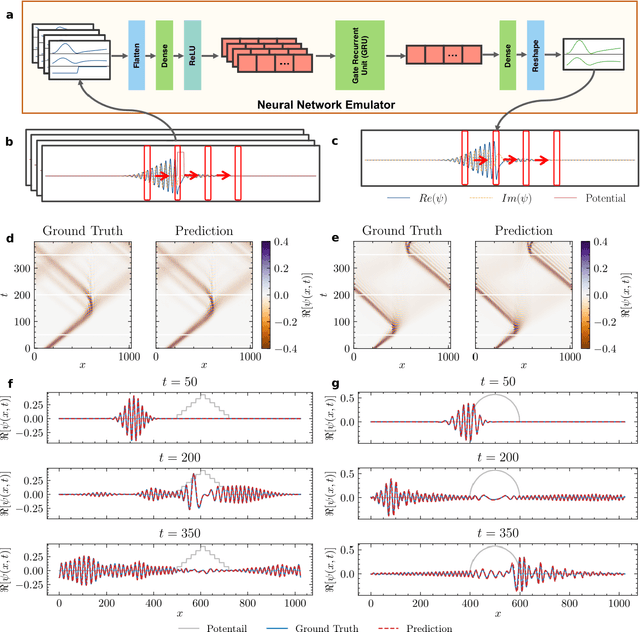
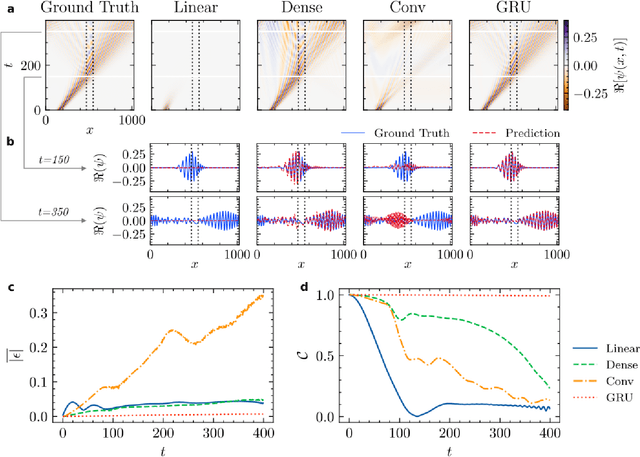
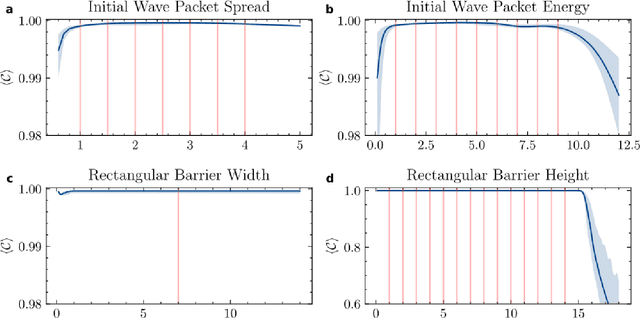
High-fidelity quantum dynamics emulators can be used to predict the time evolution of complex physical systems. Here, we introduce an efficient training framework for constructing machine learning-based emulators. Our approach is based on the idea of knowledge distillation and uses elements of curriculum learning. It works by constructing a set of simple, but rich-in-physics training examples (a curriculum). These examples are used by the emulator to learn the general rules describing the time evolution of a quantum system (knowledge distillation). The goal is not only to obtain high-quality predictions, but also to examine the process of how the emulator learns the physics of the underlying problem. This allows us to discover new facts about the physical system, detect symmetries, and measure relative importance of the contributing physical processes. We illustrate this approach by training an artificial neural network to predict the time evolution of quantum wave packages propagating through a potential landscape. We focus on the question of how the emulator learns the rules of quantum dynamics from the curriculum of simple training examples and to which extent it can generalize the acquired knowledge to solve more challenging cases.
Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER
Oct 16, 2021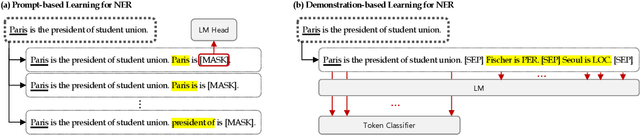
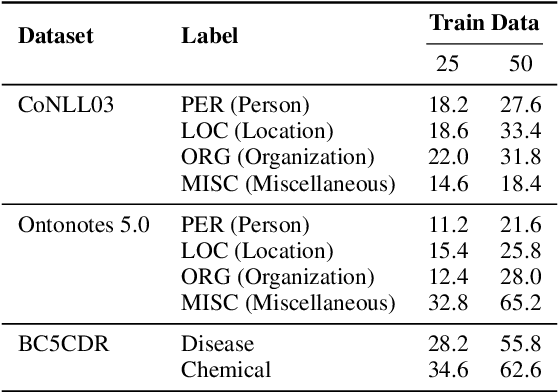

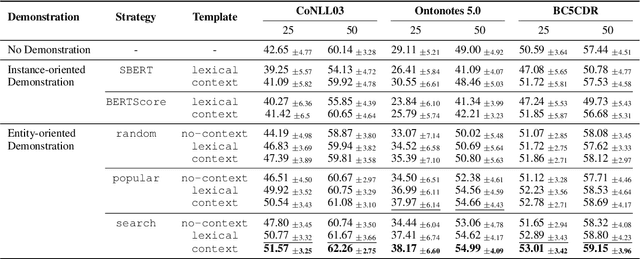
Recent advances in prompt-based learning have shown impressive results on few-shot text classification tasks by using cloze-style language prompts. There have been attempts on prompt-based learning for NER which use manually designed templates to predict entity types. However, these two-step methods may suffer from error propagation (from entity span detection), need to prompt for all possible text spans which is costly, and neglect the interdependency when predicting labels for different spans in a sentence. In this paper, we present a simple demonstration-based learning method for NER, which augments the prompt (learning context) with a few task demonstrations. Such demonstrations help the model learn the task better under low-resource settings and allow for span detection and classification over all tokens jointly. Here, we explore entity-oriented demonstration which selects an appropriate entity example per each entity type, and instance-oriented demonstration which retrieves a similar instance example. Through extensive experiments, we find empirically that showing entity example per each entity type, along with its example sentence, can improve the performance both in in-domain and cross-domain settings by 1-3 F1 score.
AutoTriggER: Named Entity Recognition with Auxiliary Trigger Extraction
Sep 10, 2021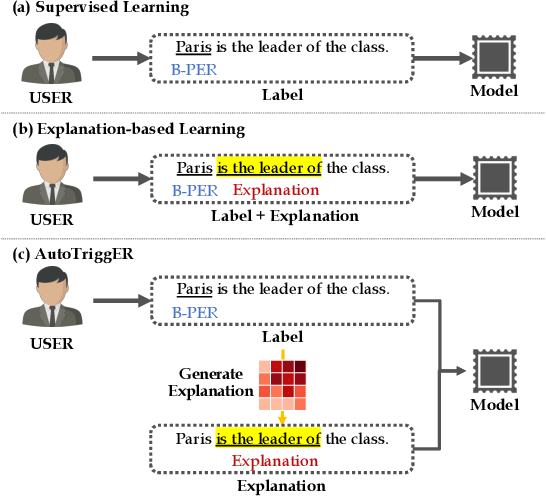
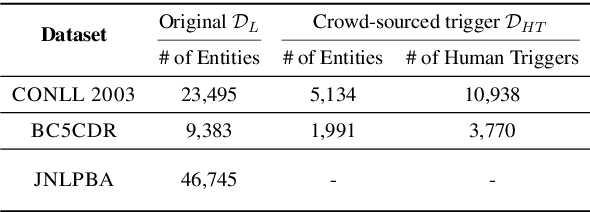

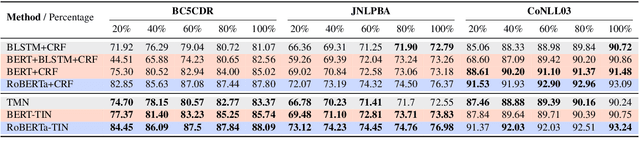
Deep neural models for low-resource named entity recognition (NER) have shown impressive results by leveraging distant super-vision or other meta-level information (e.g. explanation). However, the costs of acquiring such additional information are generally prohibitive, especially in domains where existing resources (e.g. databases to be used for distant supervision) may not exist. In this paper, we present a novel two-stage framework (AutoTriggER) to improve NER performance by automatically generating and leveraging "entity triggers" which are essentially human-readable clues in the text that can help guide the model to make better decisions. Thus, the framework is able to both create and leverage auxiliary supervision by itself. Through experiments on three well-studied NER datasets, we show that our automatically extracted triggers are well-matched to human triggers, and AutoTriggER improves performance over a RoBERTa-CRFarchitecture by nearly 0.5 F1 points on average and much more in a low resource setting.