 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy does in-context learning fail sometimes? Evaluating in-context learning on open and closed questions
Jul 02, 2024



We measure the performance of in-context learning as a function of task novelty and difficulty for open and closed questions. For that purpose, we created a novel benchmark consisting of hard scientific questions, each paired with a context of various relevancy. We show that counter-intuitively, a context that is more aligned with the topic does not always help more than a less relevant context. This effect is especially visible for open questions and questions of high difficulty or novelty. This result reveals a fundamental difference between the treatment of close-form and open-form questions by large-language models and shows a need for a more robust evaluation of in-context learning on the variety of different types of questions. It also poses a new question of how to optimally select a context for large language models, especially in the context of Retrieval Augmented Generation (RAG) systems. Our results suggest that the answer to this question can be highly application-dependent and might be contingent on factors including the format of the question, the perceived difficulty level of the questions, and the novelty or popularity of the information we seek.
Context Matters: Data-Efficient Augmentation of Large Language Models for Scientific Applications
Dec 21, 2023In this paper, we explore the challenges inherent to Large Language Models (LLMs) like GPT-4, particularly their propensity for hallucinations, logic mistakes, and incorrect conclusions when tasked with answering complex questions. The capacity of LLMs to present erroneous answers in a coherent and semantically rigorous manner further complicates the detection of factual inaccuracies. This issue is especially pronounced in fields that require specialized expertise. Our work delves into these challenges, aiming to enhance the understanding and mitigation of such errors, thereby contributing to the improvement of LLM accuracy and reliability in scientific and other specialized domains. Our findings reveal a non-linear relationship between the context's relevancy and the answers' measured quality. In addition, we demonstrate that with the correct calibration, it is possible to automate the grading procedure -- a finding suggesting that, at least to some degree, the LLMs can be used to self-examine the quality of their own performance. Finally, we describe an experimental platform that can be seen as a proof-of-concept of the techniques described in this work.
Performance Weighting for Robust Federated Learning Against Corrupted Sources
May 02, 2022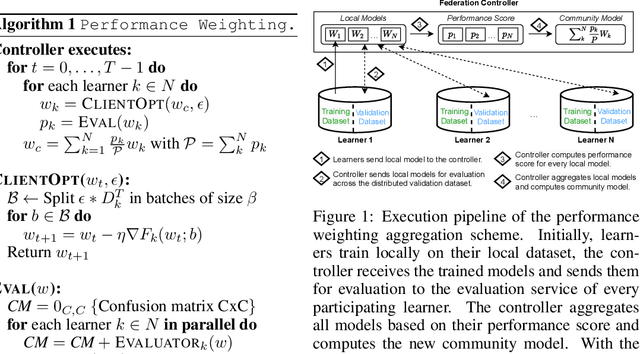
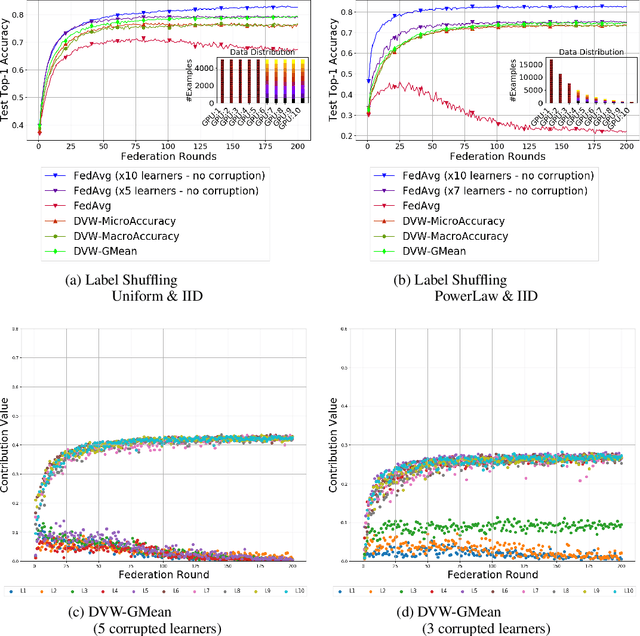
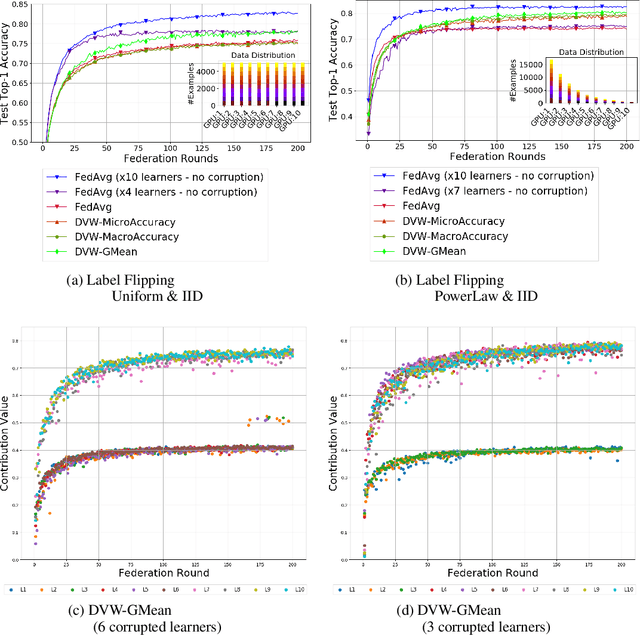
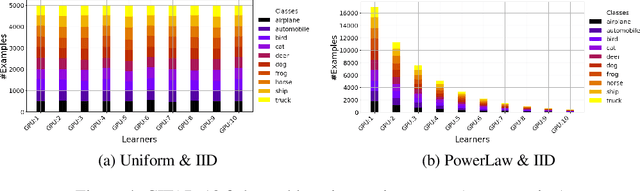
Federated Learning has emerged as a dominant computational paradigm for distributed machine learning. Its unique data privacy properties allow us to collaboratively train models while offering participating clients certain privacy-preserving guarantees. However, in real-world applications, a federated environment may consist of a mixture of benevolent and malicious clients, with the latter aiming to corrupt and degrade federated model's performance. Different corruption schemes may be applied such as model poisoning and data corruption. Here, we focus on the latter, the susceptibility of federated learning to various data corruption attacks. We show that the standard global aggregation scheme of local weights is inefficient in the presence of corrupted clients. To mitigate this problem, we propose a class of task-oriented performance-based methods computed over a distributed validation dataset with the goal to detect and mitigate corrupted clients. Specifically, we construct a robust weight aggregation scheme based on geometric mean and demonstrate its effectiveness under random label shuffling and targeted label flipping attacks.
Inferring topological transitions in pattern-forming processes with self-supervised learning
Mar 19, 2022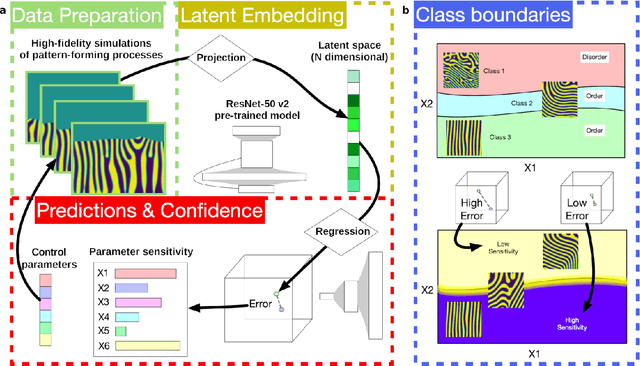
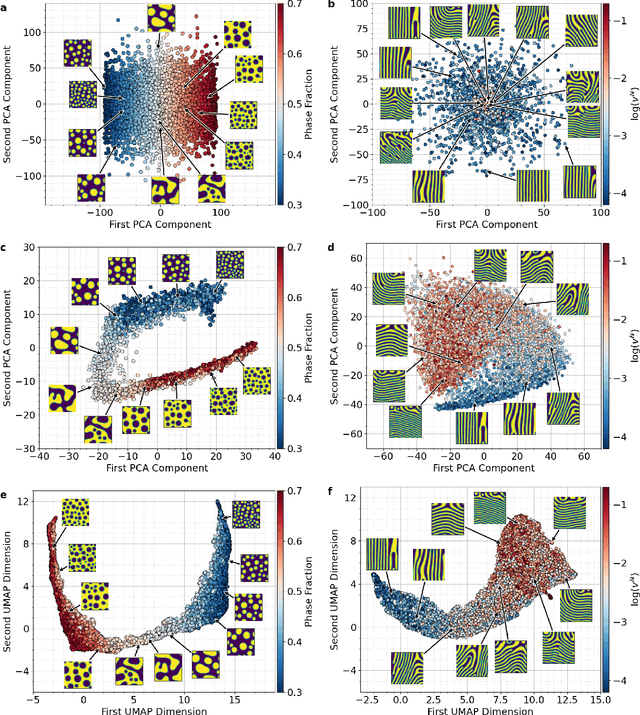
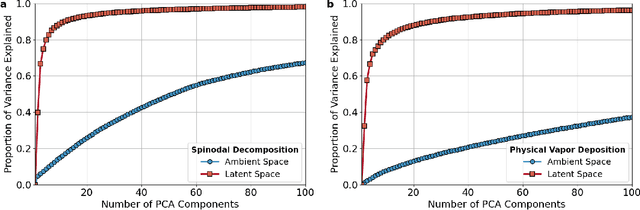
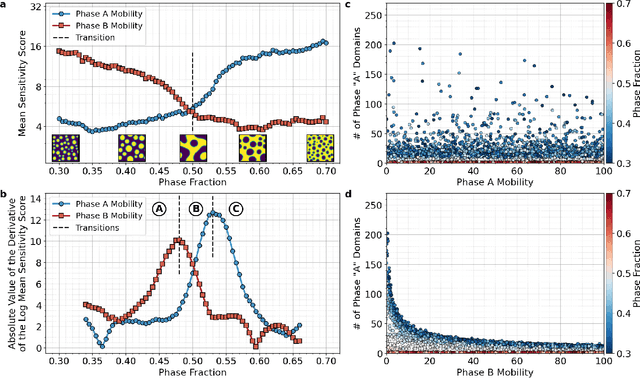
The identification and classification of transitions in topological and microstructural regimes in pattern-forming processes is critical for understanding and fabricating microstructurally precise novel materials in many application domains. Unfortunately, relevant microstructure transitions may depend on process parameters in subtle and complex ways that are not captured by the classic theory of phase transition. While supervised machine learning methods may be useful for identifying transition regimes, they need labels which require prior knowledge of order parameters or relevant structures. Motivated by the universality principle for dynamical systems, we instead use a self-supervised approach to solve the inverse problem of predicting process parameters from observed microstructures using neural networks. This approach does not require labeled data about the target task of predicting microstructure transitions. We show that the difficulty of performing this prediction task is related to the goal of discovering microstructure regimes, because qualitative changes in microstructural patterns correspond to changes in uncertainty for our self-supervised prediction problem. We demonstrate the value of our approach by automatically discovering transitions in microstructural regimes in two distinct pattern-forming processes: the spinodal decomposition of a two-phase mixture and the formation of concentration modulations of binary alloys during physical vapor deposition of thin films. This approach opens a promising path forward for discovering and understanding unseen or hard-to-detect transition regimes, and ultimately for controlling complex pattern-forming processes.
Emulating Quantum Dynamics with Neural Networks via Knowledge Distillation
Mar 19, 2022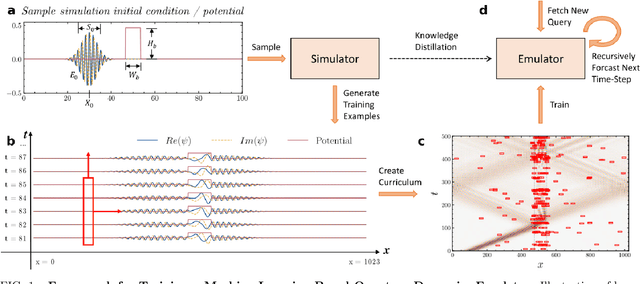
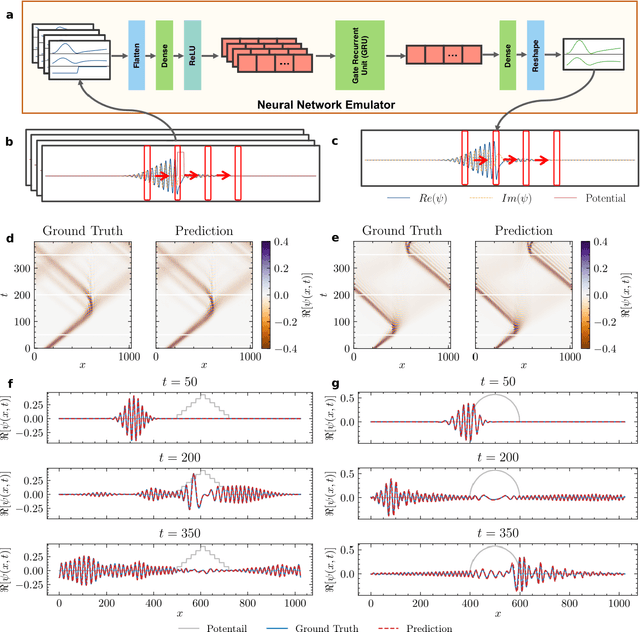
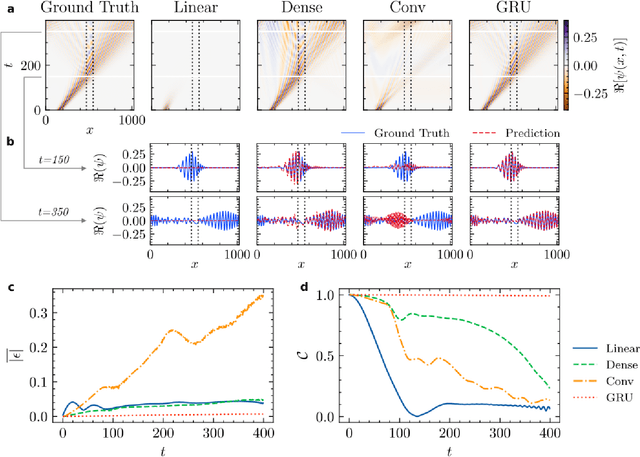
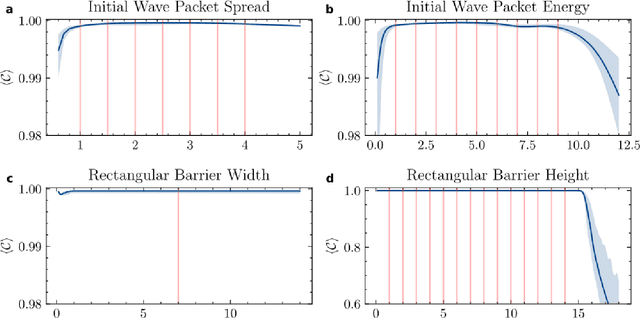
High-fidelity quantum dynamics emulators can be used to predict the time evolution of complex physical systems. Here, we introduce an efficient training framework for constructing machine learning-based emulators. Our approach is based on the idea of knowledge distillation and uses elements of curriculum learning. It works by constructing a set of simple, but rich-in-physics training examples (a curriculum). These examples are used by the emulator to learn the general rules describing the time evolution of a quantum system (knowledge distillation). The goal is not only to obtain high-quality predictions, but also to examine the process of how the emulator learns the physics of the underlying problem. This allows us to discover new facts about the physical system, detect symmetries, and measure relative importance of the contributing physical processes. We illustrate this approach by training an artificial neural network to predict the time evolution of quantum wave packages propagating through a potential landscape. We focus on the question of how the emulator learns the rules of quantum dynamics from the curriculum of simple training examples and to which extent it can generalize the acquired knowledge to solve more challenging cases.