 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Agnostic Federated Learning
Jun 25, 2024In the realm of medical imaging, leveraging large-scale datasets from various institutions is crucial for developing precise deep learning models, yet privacy concerns frequently impede data sharing. federated learning (FL) emerges as a prominent solution for preserving privacy while facilitating collaborative learning. However, its application in real-world scenarios faces several obstacles, such as task & data heterogeneity, label scarcity, non-identically distributed (non-IID) data, computational vaiation, etc. In real-world, medical institutions may not want to disclose their tasks to FL server and generalization challenge of out-of-network institutions with un-seen task want to join the on-going federated system. This study address task-agnostic and generalization problem on un-seen tasks by adapting self-supervised FL framework. Utilizing Vision Transformer (ViT) as consensus feature encoder for self-supervised pre-training, no initial labels required, the framework enabling effective representation learning across diverse datasets and tasks. Our extensive evaluations, using various real-world non-IID medical imaging datasets, validate our approach's efficacy, retaining 90\% of F1 accuracy with only 5\% of the training data typically required for centralized approaches and exhibiting superior adaptability to out-of-distribution task. The result indicate that federated learning architecture can be a potential approach toward multi-task foundation modeling.
MetisFL: An Embarrassingly Parallelized Controller for Scalable & Efficient Federated Learning Workflows
Nov 13, 2023



A Federated Learning (FL) system typically consists of two core processing entities: the federation controller and the learners. The controller is responsible for managing the execution of FL workflows across learners and the learners for training and evaluating federated models over their private datasets. While executing an FL workflow, the FL system has no control over the computational resources or data of the participating learners. Still, it is responsible for other operations, such as model aggregation, task dispatching, and scheduling. These computationally heavy operations generally need to be handled by the federation controller. Even though many FL systems have been recently proposed to facilitate the development of FL workflows, most of these systems overlook the scalability of the controller. To meet this need, we designed and developed a novel FL system called MetisFL, where the federation controller is the first-class citizen. MetisFL re-engineers all the operations conducted by the federation controller to accelerate the training of large-scale FL workflows. By quantitatively comparing MetisFL against other state-of-the-art FL systems, we empirically demonstrate that MetisFL leads to a 10-fold wall-clock time execution boost across a wide range of challenging FL workflows with increasing model sizes and federation sites.
Federated Learning over Harmonized Data Silos
May 15, 2023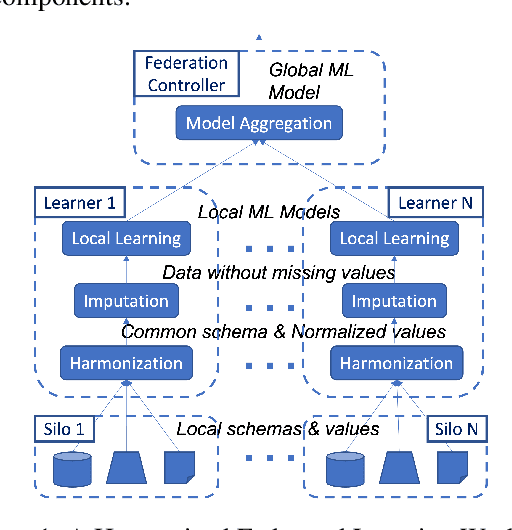



Federated Learning is a distributed machine learning approach that enables geographically distributed data silos to collaboratively learn a joint machine learning model without sharing data. Most of the existing work operates on unstructured data, such as images or text, or on structured data assumed to be consistent across the different sites. However, sites often have different schemata, data formats, data values, and access patterns. The field of data integration has developed many methods to address these challenges, including techniques for data exchange and query rewriting using declarative schema mappings, and for entity linkage. Therefore, we propose an architectural vision for an end-to-end Federated Learning and Integration system, incorporating the critical steps of data harmonization and data imputation, to spur further research on the intersection of data management information systems and machine learning.
Secure Federated Learning for Neuroimaging
May 11, 2022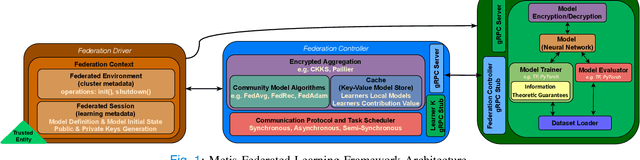
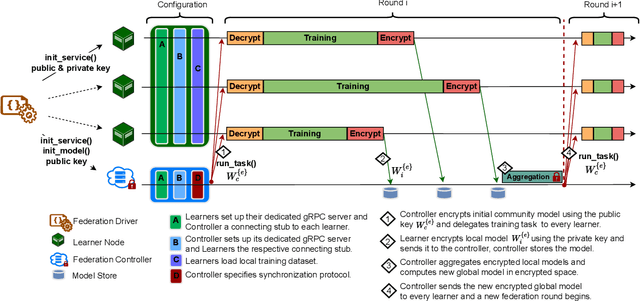
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
Performance Weighting for Robust Federated Learning Against Corrupted Sources
May 02, 2022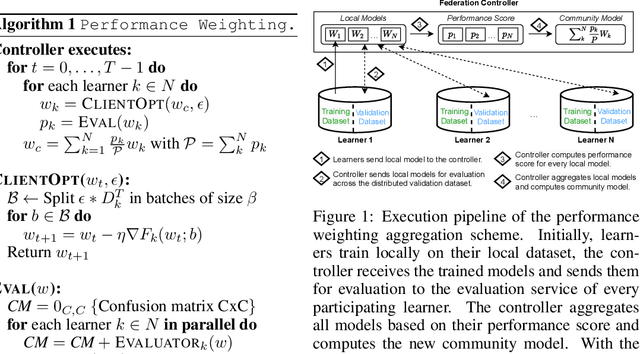
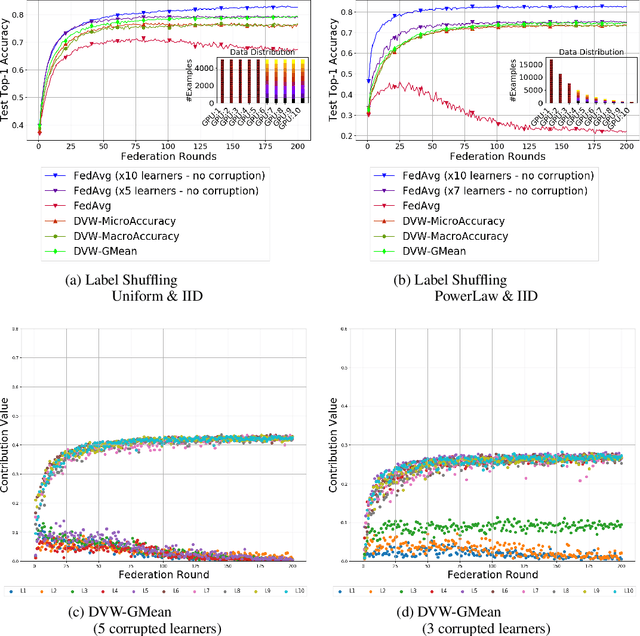
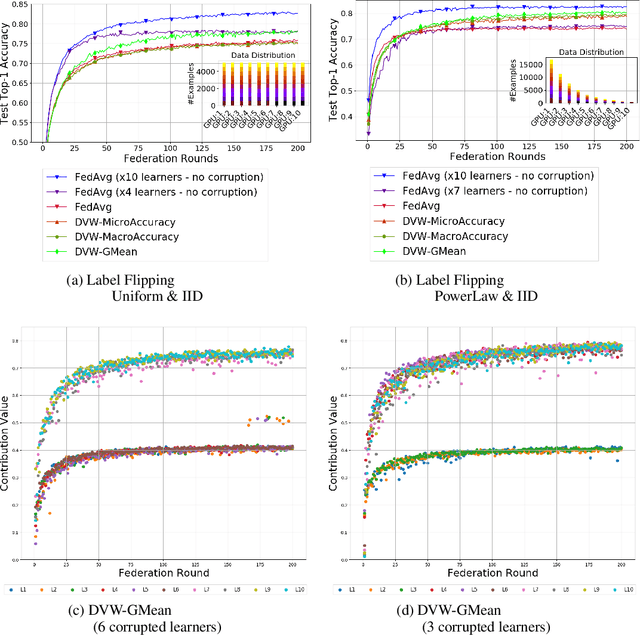
Federated Learning has emerged as a dominant computational paradigm for distributed machine learning. Its unique data privacy properties allow us to collaboratively train models while offering participating clients certain privacy-preserving guarantees. However, in real-world applications, a federated environment may consist of a mixture of benevolent and malicious clients, with the latter aiming to corrupt and degrade federated model's performance. Different corruption schemes may be applied such as model poisoning and data corruption. Here, we focus on the latter, the susceptibility of federated learning to various data corruption attacks. We show that the standard global aggregation scheme of local weights is inefficient in the presence of corrupted clients. To mitigate this problem, we propose a class of task-oriented performance-based methods computed over a distributed validation dataset with the goal to detect and mitigate corrupted clients. Specifically, we construct a robust weight aggregation scheme based on geometric mean and demonstrate its effectiveness under random label shuffling and targeted label flipping attacks.
Federated Progressive Sparsification (Purge, Merge, Tune)+
Apr 26, 2022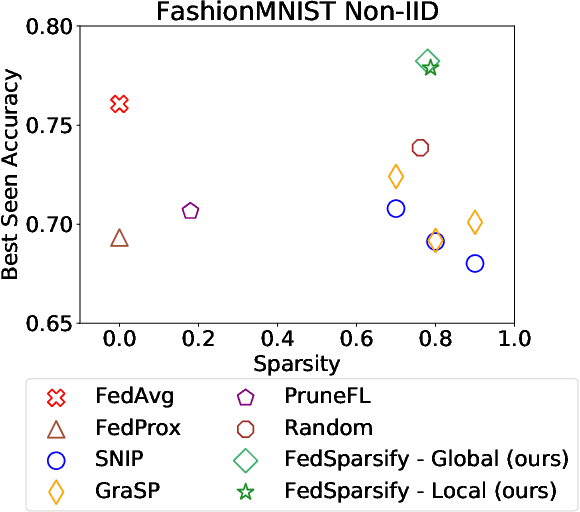
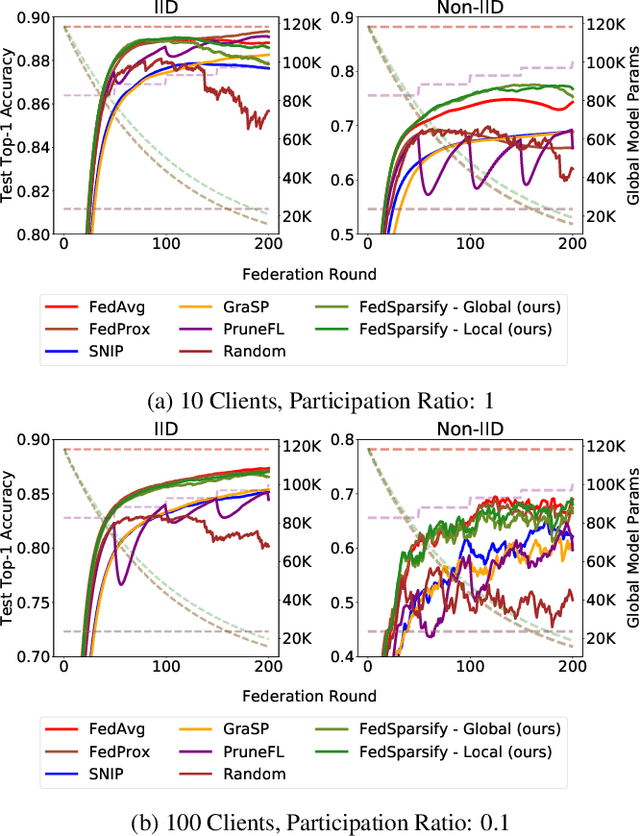
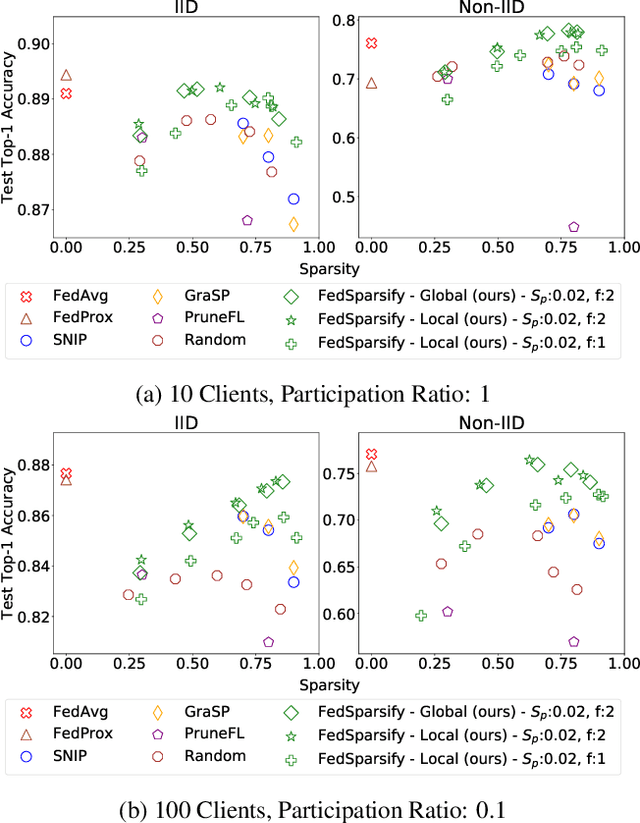
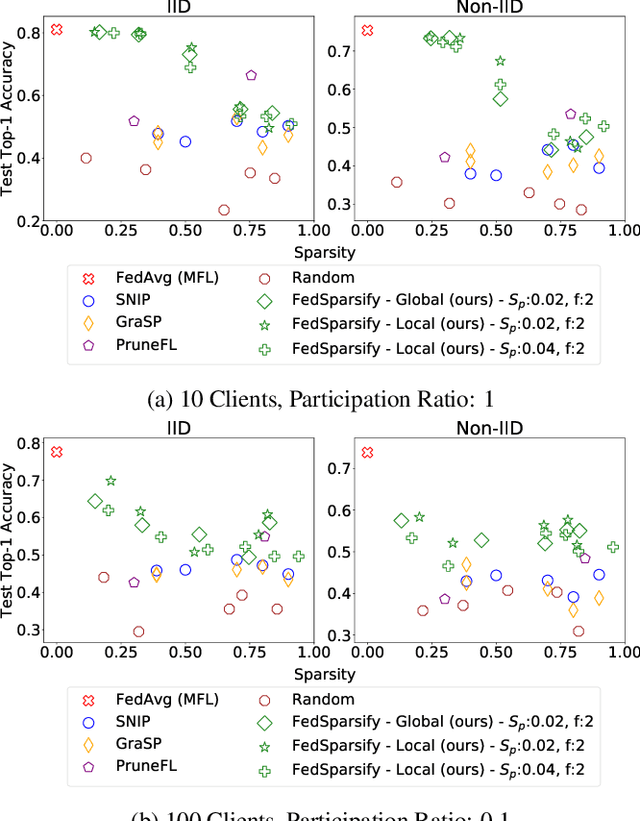
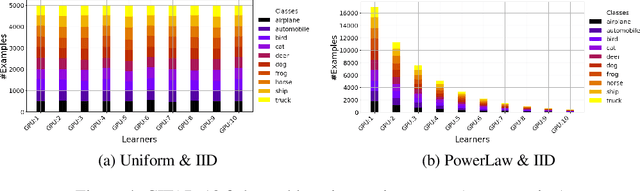
To improve federated training of neural networks, we develop FedSparsify, a sparsification strategy based on progressive weight magnitude pruning. Our method has several benefits. First, since the size of the network becomes increasingly smaller, computation and communication costs during training are reduced. Second, the models are incrementally constrained to a smaller set of parameters, which facilitates alignment/merging of the local models and improved learning performance at high sparsification rates. Third, the final sparsified model is significantly smaller, which improves inference efficiency and optimizes operations latency during encrypted communication. We show experimentally that FedSparsify learns a subnetwork of both high sparsity and learning performance. Our sparse models can reach a tenth of the size of the original model with the same or better accuracy compared to existing pruning and nonpruning baselines.
Secure Neuroimaging Analysis using Federated Learning with Homomorphic Encryption
Aug 07, 2021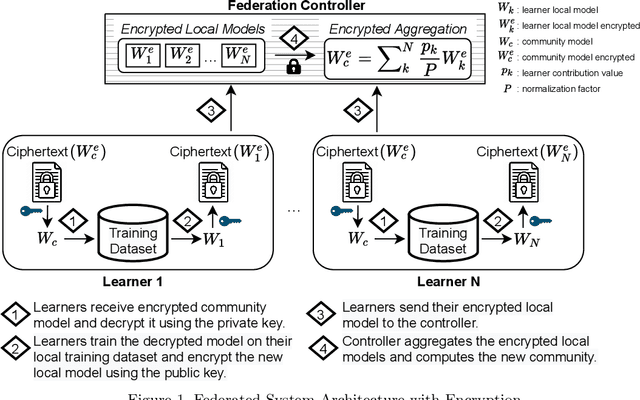
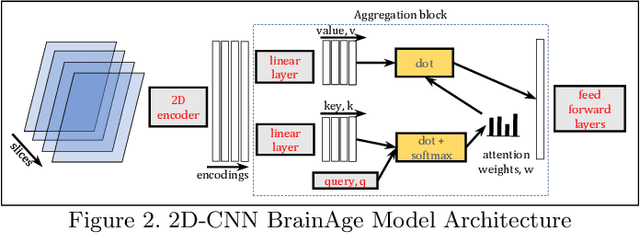
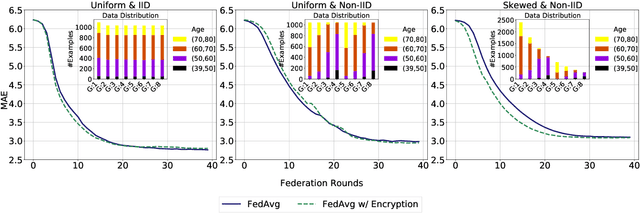
Federated learning (FL) enables distributed computation of machine learning models over various disparate, remote data sources, without requiring to transfer any individual data to a centralized location. This results in an improved generalizability of models and efficient scaling of computation as more sources and larger datasets are added to the federation. Nevertheless, recent membership attacks show that private or sensitive personal data can sometimes be leaked or inferred when model parameters or summary statistics are shared with a central site, requiring improved security solutions. In this work, we propose a framework for secure FL using fully-homomorphic encryption (FHE). Specifically, we use the CKKS construction, an approximate, floating point compatible scheme that benefits from ciphertext packing and rescaling. In our evaluation on large-scale brain MRI datasets, we use our proposed secure FL framework to train a deep learning model to predict a person's age from distributed MRI scans, a common benchmarking task, and demonstrate that there is no degradation in the learning performance between the encrypted and non-encrypted federated models.
Scaling Neuroscience Research using Federated Learning
Feb 16, 2021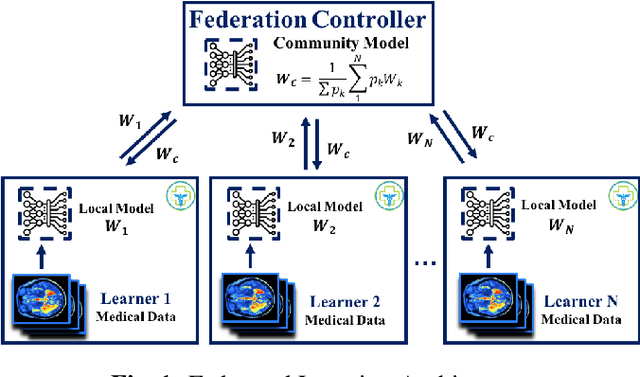



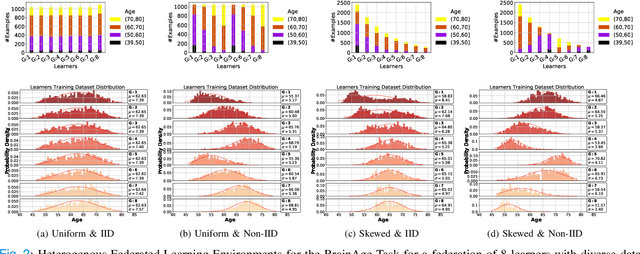
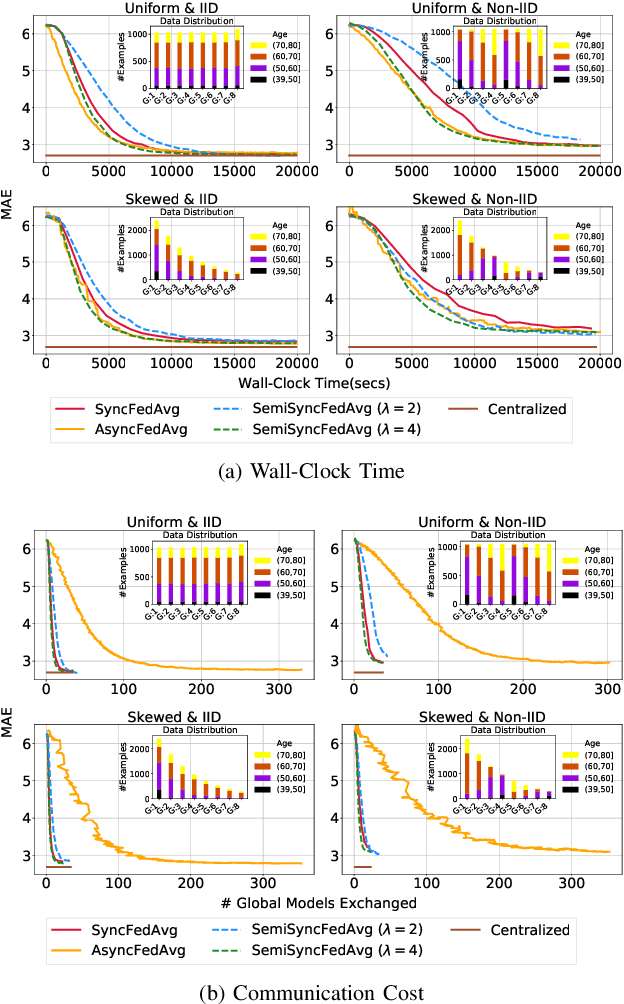
The amount of biomedical data continues to grow rapidly. However, the ability to analyze these data is limited due to privacy and regulatory concerns. Machine learning approaches that require data to be copied to a single location are hampered by the challenges of data sharing. Federated Learning is a promising approach to learn a joint model over data silos. This architecture does not share any subject data across sites, only aggregated parameters, often in encrypted environments, thus satisfying privacy and regulatory requirements. Here, we describe our Federated Learning architecture and training policies. We demonstrate our approach on a brain age prediction model on structural MRI scans distributed across multiple sites with diverse amounts of data and subject (age) distributions. In these heterogeneous environments, our Semi-Synchronous protocol provides faster convergence.
Semi-Synchronous Federated Learning
Feb 04, 2021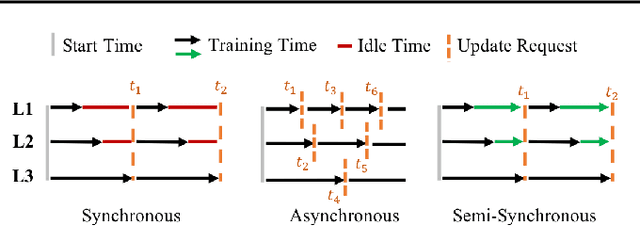
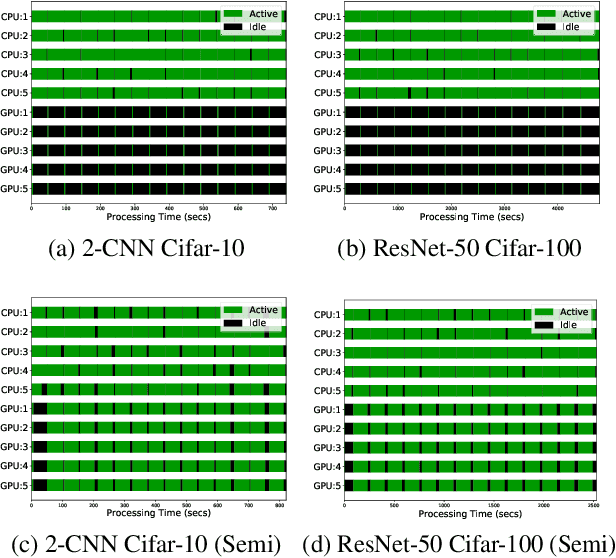
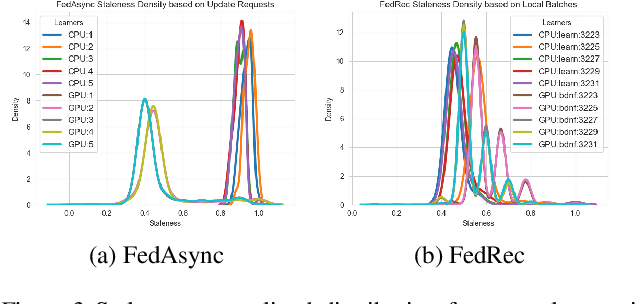
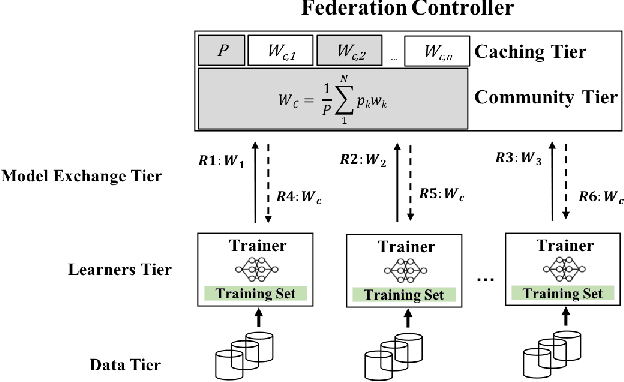
There are situations where data relevant to a machine learning problem are distributed among multiple locations that cannot share the data due to regulatory, competitiveness, or privacy reasons. For example, data present in users' cellphones, manufacturing data of companies in a given industrial sector, or medical records located at different hospitals. Federated Learning (FL) provides an approach to learn a joint model over all the available data across silos. In many cases, participating sites have different data distributions and computational capabilities. In these heterogeneous environments previous approaches exhibit poor performance: synchronous FL protocols are communication efficient, but have slow learning convergence; conversely, asynchronous FL protocols have faster convergence, but at a higher communication cost. Here we introduce a novel Semi-Synchronous Federated Learning protocol that mixes local models periodically with minimal idle time and fast convergence. We show through extensive experiments that our approach significantly outperforms previous work in data and computationally heterogeneous environments.
Accelerating Federated Learning in Heterogeneous Data and Computational Environments
Aug 25, 2020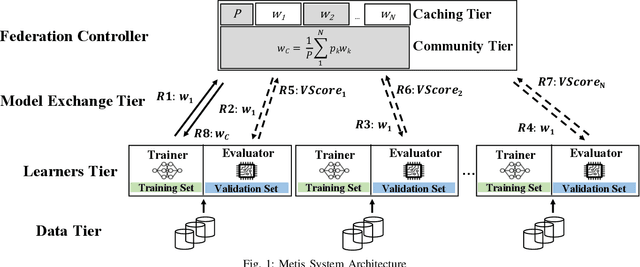
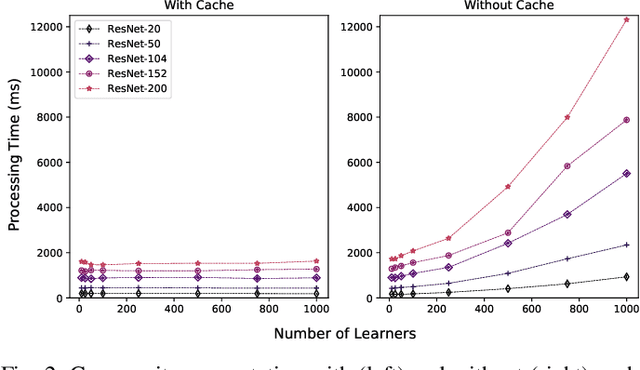
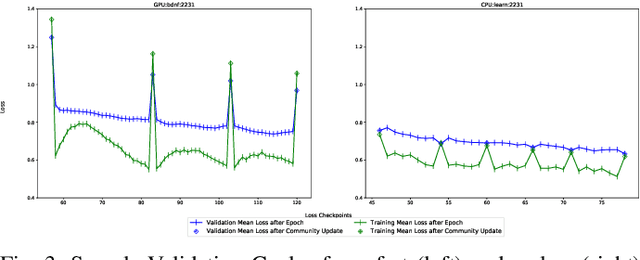
There are situations where data relevant to a machine learning problem are distributed among multiple locations that cannot share the data due to regulatory, competitiveness, or privacy reasons. For example, data present in users' cellphones, manufacturing data of companies in a given industrial sector, or medical records located at different hospitals. Moreover, participating sites often have different data distributions and computational capabilities. Federated Learning provides an approach to learn a joint model over all the available data in these environments. In this paper, we introduce a novel distributed validation weighting scheme (DVW), which evaluates the performance of a learner in the federation against a distributed validation set. Each learner reserves a small portion (e.g., 5%) of its local training examples as a validation dataset and allows other learners models to be evaluated against it. We empirically show that DVW results in better performance compared to established methods, such as FedAvg, both under synchronous and asynchronous communication protocols in data and computationally heterogeneous environments.