 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Progressive Sparsification (Purge, Merge, Tune)+
Paper and Code
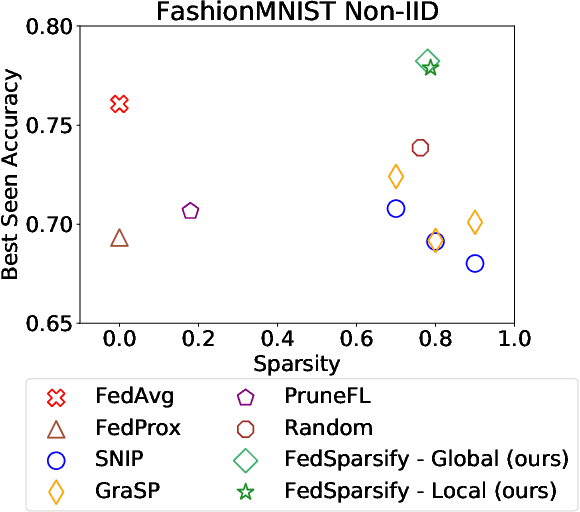
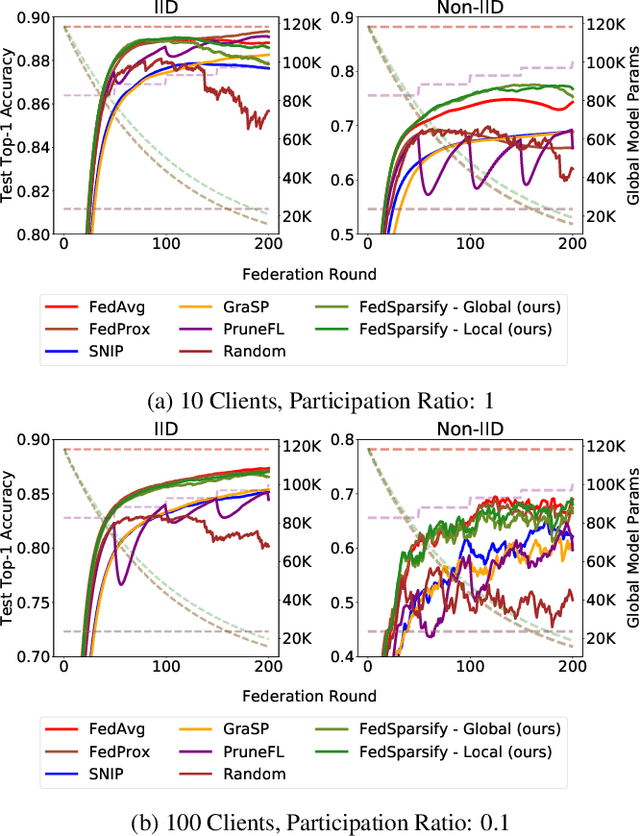
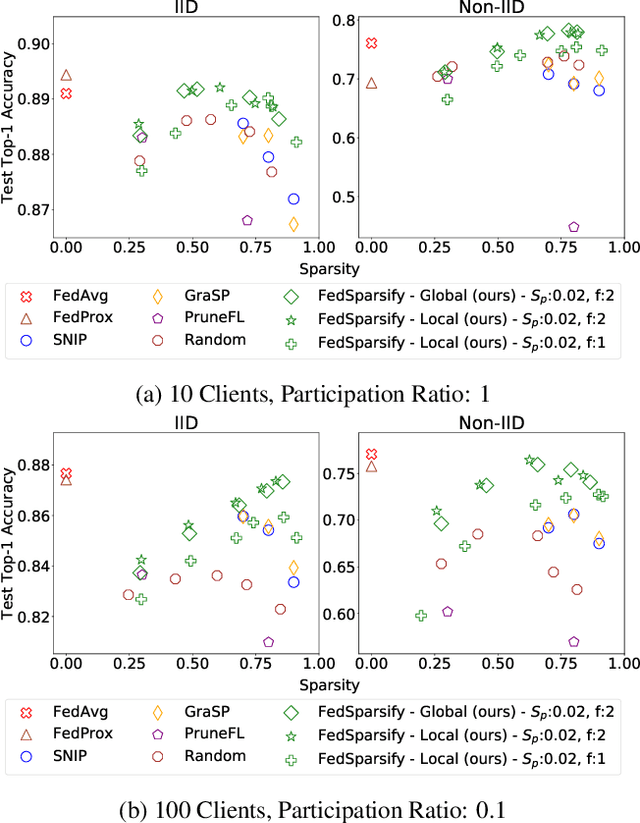
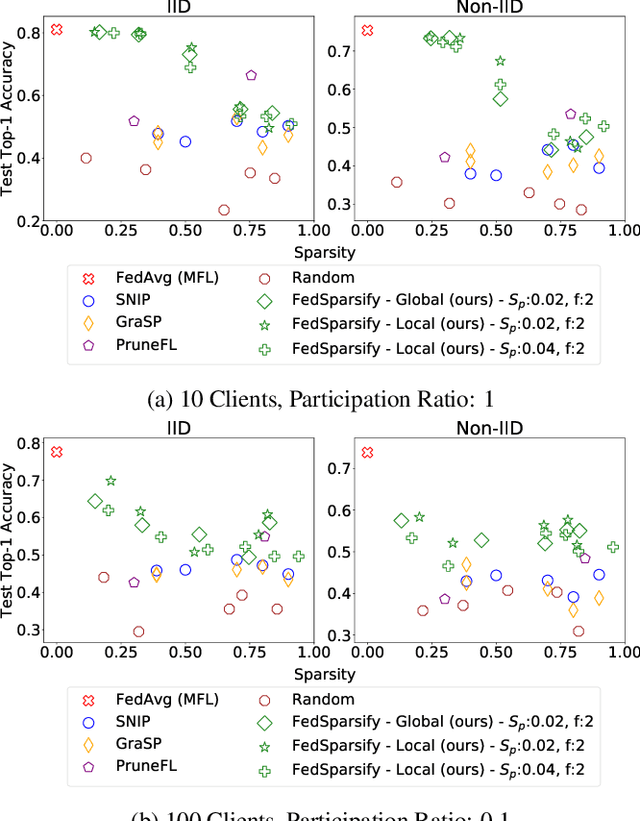
To improve federated training of neural networks, we develop FedSparsify, a sparsification strategy based on progressive weight magnitude pruning. Our method has several benefits. First, since the size of the network becomes increasingly smaller, computation and communication costs during training are reduced. Second, the models are incrementally constrained to a smaller set of parameters, which facilitates alignment/merging of the local models and improved learning performance at high sparsification rates. Third, the final sparsified model is significantly smaller, which improves inference efficiency and optimizes operations latency during encrypted communication. We show experimentally that FedSparsify learns a subnetwork of both high sparsity and learning performance. Our sparse models can reach a tenth of the size of the original model with the same or better accuracy compared to existing pruning and nonpruning baselines.