 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Federated Learning in Heterogeneous Data and Computational Environments
Paper and Code
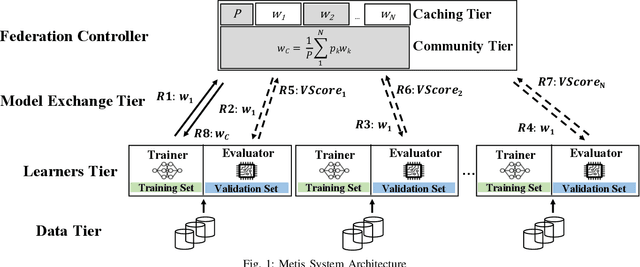
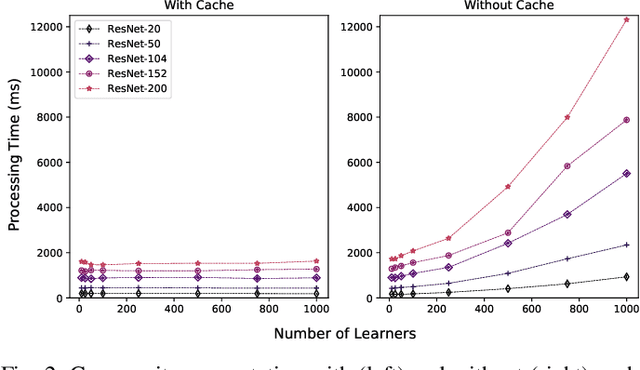
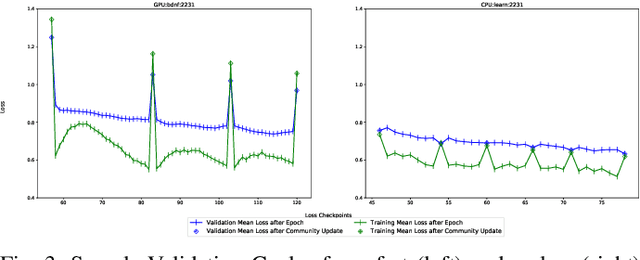
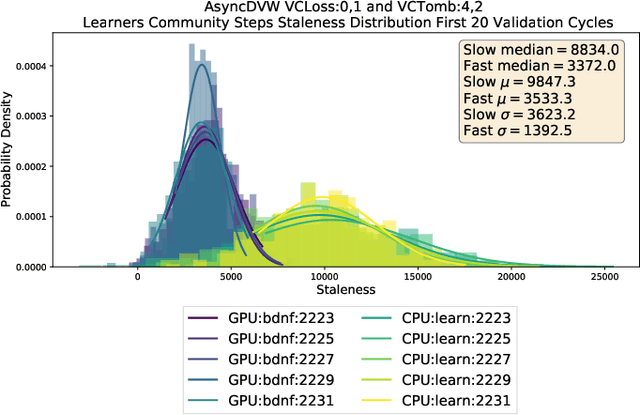
There are situations where data relevant to a machine learning problem are distributed among multiple locations that cannot share the data due to regulatory, competitiveness, or privacy reasons. For example, data present in users' cellphones, manufacturing data of companies in a given industrial sector, or medical records located at different hospitals. Moreover, participating sites often have different data distributions and computational capabilities. Federated Learning provides an approach to learn a joint model over all the available data in these environments. In this paper, we introduce a novel distributed validation weighting scheme (DVW), which evaluates the performance of a learner in the federation against a distributed validation set. Each learner reserves a small portion (e.g., 5%) of its local training examples as a validation dataset and allows other learners models to be evaluated against it. We empirically show that DVW results in better performance compared to established methods, such as FedAvg, both under synchronous and asynchronous communication protocols in data and computationally heterogeneous environments.