 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture of Information Retrieval Research in the Age of Generative AI
Dec 03, 2024In the fast-evolving field of information retrieval (IR), the integration of generative AI technologies such as large language models (LLMs) is transforming how users search for and interact with information. Recognizing this paradigm shift at the intersection of IR and generative AI (IR-GenAI), a visioning workshop supported by the Computing Community Consortium (CCC) was held in July 2024 to discuss the future of IR in the age of generative AI. This workshop convened 44 experts in information retrieval, natural language processing, human-computer interaction, and artificial intelligence from academia, industry, and government to explore how generative AI can enhance IR and vice versa, and to identify the major challenges and opportunities in this rapidly advancing field. This report contains a summary of discussions as potentially important research topics and contains a list of recommendations for academics, industry practitioners, institutions, evaluation campaigns, and funding agencies.
Probing Ranking LLMs: Mechanistic Interpretability in Information Retrieval
Oct 24, 2024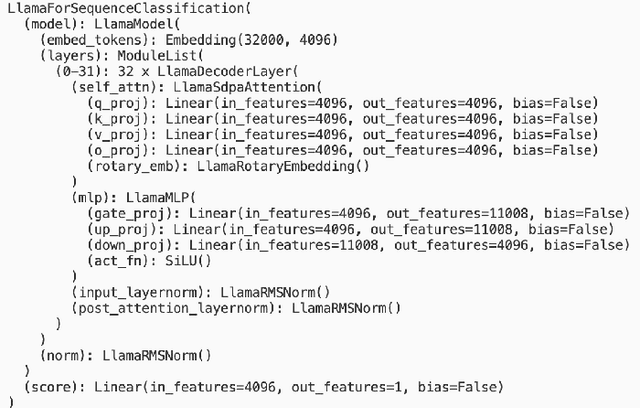


Transformer networks, especially those with performance on par with GPT models, are renowned for their powerful feature extraction capabilities. However, the nature and correlation of these features with human-engineered ones remain unclear. In this study, we delve into the mechanistic workings of state-of-the-art, fine-tuning-based passage-reranking transformer networks. Our approach involves a probing-based, layer-by-layer analysis of neurons within ranking LLMs to identify individual or groups of known human-engineered and semantic features within the network's activations. We explore a wide range of features, including lexical, document structure, query-document interaction, advanced semantic, interaction-based, and LLM-specific features, to gain a deeper understanding of the underlying mechanisms that drive ranking decisions in LLMs. Our results reveal a set of features that are prominently represented in LLM activations, as well as others that are notably absent. Additionally, we observe distinct behaviors of LLMs when processing low versus high relevance queries and when encountering out-of-distribution query and document sets. By examining these features within activations, we aim to enhance the interpretability and performance of LLMs in ranking tasks. Our findings provide valuable insights for the development of more effective and transparent ranking models, with significant implications for the broader information retrieval community. All scripts and code necessary to replicate our findings are made available.
Discovering Biases in Information Retrieval Models Using Relevance Thesaurus as Global Explanation
Oct 04, 2024



Most efforts in interpreting neural relevance models have focused on local explanations, which explain the relevance of a document to a query but are not useful in predicting the model's behavior on unseen query-document pairs. We propose a novel method to globally explain neural relevance models by constructing a "relevance thesaurus" containing semantically relevant query and document term pairs. This thesaurus is used to augment lexical matching models such as BM25 to approximate the neural model's predictions. Our method involves training a neural relevance model to score the relevance of partial query and document segments, which is then used to identify relevant terms across the vocabulary space. We evaluate the obtained thesaurus explanation based on ranking effectiveness and fidelity to the target neural ranking model. Notably, our thesaurus reveals the existence of brand name bias in ranking models, demonstrating one advantage of our explanation method.
Robust Claim Verification Through Fact Detection
Jul 25, 2024Claim verification can be a challenging task. In this paper, we present a method to enhance the robustness and reasoning capabilities of automated claim verification through the extraction of short facts from evidence. Our novel approach, FactDetect, leverages Large Language Models (LLMs) to generate concise factual statements from evidence and label these facts based on their semantic relevance to the claim and evidence. The generated facts are then combined with the claim and evidence. To train a lightweight supervised model, we incorporate a fact-detection task into the claim verification process as a multitasking approach to improve both performance and explainability. We also show that augmenting FactDetect in the claim verification prompt enhances performance in zero-shot claim verification using LLMs. Our method demonstrates competitive results in the supervised claim verification model by 15% on the F1 score when evaluated for challenging scientific claim verification datasets. We also demonstrate that FactDetect can be augmented with claim and evidence for zero-shot prompting (AugFactDetect) in LLMs for verdict prediction. We show that AugFactDetect outperforms the baseline with statistical significance on three challenging scientific claim verification datasets with an average of 17.3% performance gain compared to the best performing baselines.
RankSHAP: a Gold Standard Feature Attribution Method for the Ranking Task
May 03, 2024Several works propose various post-hoc, model-agnostic explanations for the task of ranking, i.e. the task of ordering a set of documents, via feature attribution methods. However, these attributions are seen to weakly correlate and sometimes contradict each other. In classification/regression, several works focus on \emph{axiomatic characterization} of feature attribution methods, showing that a certain method uniquely satisfies a set of desirable properties. However, no such efforts have been taken in the space of feature attributions for the task of ranking. We take an axiomatic game-theoretic approach, popular in the feature attribution community, to identify candidate attribution methods for ranking tasks. We first define desirable axioms: Rank-Efficiency, Rank-Missingness, Rank-Symmetry and Rank-Monotonicity, all variants of the classical Shapley axioms. Next, we introduce Rank-SHAP, a feature attribution algorithm for the general ranking task, which is an extension to classical Shapley values. We identify a polynomial-time algorithm for computing approximate Rank-SHAP values and evaluate the computational efficiency and accuracy of our algorithm under various scenarios. We also evaluate its alignment with human intuition with a user study. Lastly, we theoretically examine popular rank attribution algorithms, EXS and Rank-LIME, and evaluate their capacity to satisfy the classical Shapley axioms.
Target Span Detection for Implicit Harmful Content
Mar 28, 2024



Identifying the targets of hate speech is a crucial step in grasping the nature of such speech and, ultimately, in improving the detection of offensive posts on online forums. Much harmful content on online platforms uses implicit language especially when targeting vulnerable and protected groups such as using stereotypical characteristics instead of explicit target names, making it harder to detect and mitigate the language. In this study, we focus on identifying implied targets of hate speech, essential for recognizing subtler hate speech and enhancing the detection of harmful content on digital platforms. We define a new task aimed at identifying the targets even when they are not explicitly stated. To address that task, we collect and annotate target spans in three prominent implicit hate speech datasets: SBIC, DynaHate, and IHC. We call the resulting merged collection Implicit-Target-Span. The collection is achieved using an innovative pooling method with matching scores based on human annotations and Large Language Models (LLMs). Our experiments indicate that Implicit-Target-Span provides a challenging test bed for target span detection methods.
Uncertainty in Additive Feature Attribution methods
Nov 29, 2023



In this work, we explore various topics that fall under the umbrella of Uncertainty in post-hoc Explainable AI (XAI) methods. We in particular focus on the class of additive feature attribution explanation methods. We first describe our specifications of uncertainty and compare various statistical and recent methods to quantify the same. Next, for a particular instance, we study the relationship between a feature's attribution and its uncertainty and observe little correlation. As a result, we propose a modification in the distribution from which perturbations are sampled in LIME-based algorithms such that the important features have minimal uncertainty without an increase in computational cost. Next, while studying how the uncertainty in explanations varies across the feature space of a classifier, we observe that a fraction of instances show near-zero uncertainty. We coin the term "stable instances" for such instances and diagnose factors that make an instance stable. Next, we study how an XAI algorithm's uncertainty varies with the size and complexity of the underlying model. We observe that the more complex the model, the more inherent uncertainty is exhibited by it. As a result, we propose a measure to quantify the relative complexity of a blackbox classifier. This could be incorporated, for example, in LIME-based algorithms' sampling densities, to help different explanation algorithms achieve tighter confidence levels. Together, the above measures would have a strong impact on making XAI models relatively trustworthy for the end-user as well as aiding scientific discovery.
Soft Prompt Decoding for Multilingual Dense Retrieval
May 15, 2023
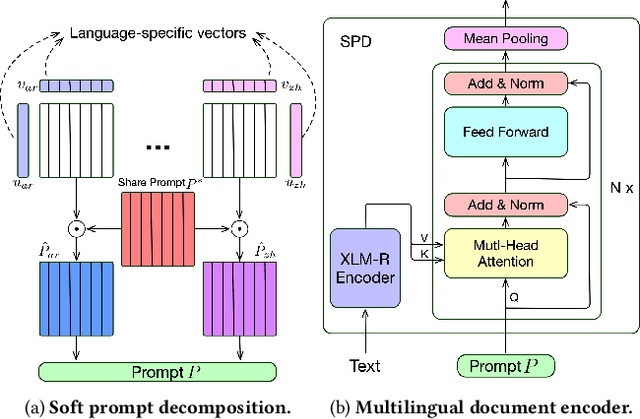
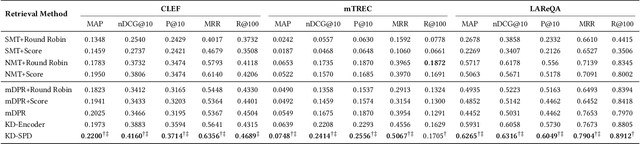
In this work, we explore a Multilingual Information Retrieval (MLIR) task, where the collection includes documents in multiple languages. We demonstrate that applying state-of-the-art approaches developed for cross-lingual information retrieval to MLIR tasks leads to sub-optimal performance. This is due to the heterogeneous and imbalanced nature of multilingual collections -- some languages are better represented in the collection and some benefit from large-scale training data. To address this issue, we present KD-SPD, a novel soft prompt decoding approach for MLIR that implicitly "translates" the representation of documents in different languages into the same embedding space. To address the challenges of data scarcity and imbalance, we introduce a knowledge distillation strategy. The teacher model is trained on rich English retrieval data, and by leveraging bi-text data, our distillation framework transfers its retrieval knowledge to the multilingual document encoder. Therefore, our approach does not require any multilingual retrieval training data. Extensive experiments on three MLIR datasets with a total of 15 languages demonstrate that KD-SPD significantly outperforms competitive baselines in all cases. We conduct extensive analyses to show that our method has less language bias and better zero-shot transfer ability towards new languages.
Evaluating the Robustness of Conversational Recommender Systems by Adversarial Examples
Mar 09, 2023Conversational recommender systems (CRSs) are improving rapidly, according to the standard recommendation accuracy metrics. However, it is essential to make sure that these systems are robust in interacting with users including regular and malicious users who want to attack the system by feeding the system modified input data. In this paper, we propose an adversarial evaluation scheme including four scenarios in two categories and automatically generate adversarial examples to evaluate the robustness of these systems in the face of different input data. By executing these adversarial examples we can compare the ability of different conversational recommender systems to satisfy the user's preferences. We evaluate three CRSs by the proposed adversarial examples on two datasets. Our results show that none of these systems are robust and reliable to the adversarial examples.
Cross-lingual Knowledge Transfer via Distillation for Multilingual Information Retrieval
Feb 26, 2023In this paper, we introduce the approach behind our submission for the MIRACL challenge, a WSDM 2023 Cup competition that centers on ad-hoc retrieval across 18 diverse languages. Our solution contains two neural-based models. The first model is a bi-encoder re-ranker, on which we apply a cross-lingual distillation technique to transfer ranking knowledge from English to the target language space. The second model is a cross-encoder re-ranker trained on multilingual retrieval data generated using neural machine translation. We further fine-tune both models using MIRACL training data and ensemble multiple rank lists to obtain the final result. According to the MIRACL leaderboard, our approach ranks 8th for the Test-A set and 2nd for the Test-B set among the 16 known languages.