 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Ranking LLMs: Mechanistic Interpretability in Information Retrieval
Paper and Code
Oct 24, 2024


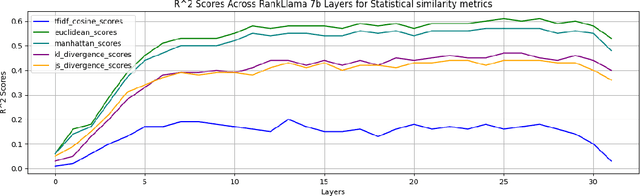
Transformer networks, especially those with performance on par with GPT models, are renowned for their powerful feature extraction capabilities. However, the nature and correlation of these features with human-engineered ones remain unclear. In this study, we delve into the mechanistic workings of state-of-the-art, fine-tuning-based passage-reranking transformer networks. Our approach involves a probing-based, layer-by-layer analysis of neurons within ranking LLMs to identify individual or groups of known human-engineered and semantic features within the network's activations. We explore a wide range of features, including lexical, document structure, query-document interaction, advanced semantic, interaction-based, and LLM-specific features, to gain a deeper understanding of the underlying mechanisms that drive ranking decisions in LLMs. Our results reveal a set of features that are prominently represented in LLM activations, as well as others that are notably absent. Additionally, we observe distinct behaviors of LLMs when processing low versus high relevance queries and when encountering out-of-distribution query and document sets. By examining these features within activations, we aim to enhance the interpretability and performance of LLMs in ranking tasks. Our findings provide valuable insights for the development of more effective and transparent ranking models, with significant implications for the broader information retrieval community. All scripts and code necessary to replicate our findings are made available.