 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Ranking LLMs: Mechanistic Interpretability in Information Retrieval
Oct 24, 2024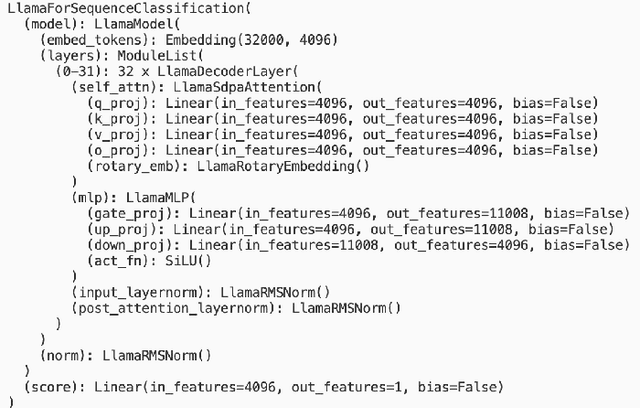


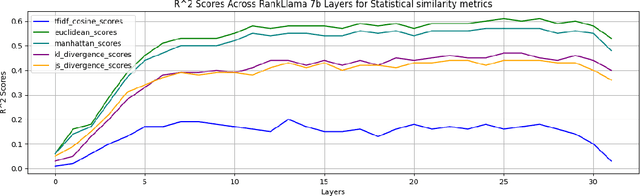
Transformer networks, especially those with performance on par with GPT models, are renowned for their powerful feature extraction capabilities. However, the nature and correlation of these features with human-engineered ones remain unclear. In this study, we delve into the mechanistic workings of state-of-the-art, fine-tuning-based passage-reranking transformer networks. Our approach involves a probing-based, layer-by-layer analysis of neurons within ranking LLMs to identify individual or groups of known human-engineered and semantic features within the network's activations. We explore a wide range of features, including lexical, document structure, query-document interaction, advanced semantic, interaction-based, and LLM-specific features, to gain a deeper understanding of the underlying mechanisms that drive ranking decisions in LLMs. Our results reveal a set of features that are prominently represented in LLM activations, as well as others that are notably absent. Additionally, we observe distinct behaviors of LLMs when processing low versus high relevance queries and when encountering out-of-distribution query and document sets. By examining these features within activations, we aim to enhance the interpretability and performance of LLMs in ranking tasks. Our findings provide valuable insights for the development of more effective and transparent ranking models, with significant implications for the broader information retrieval community. All scripts and code necessary to replicate our findings are made available.
RankSHAP: a Gold Standard Feature Attribution Method for the Ranking Task
May 03, 2024



Several works propose various post-hoc, model-agnostic explanations for the task of ranking, i.e. the task of ordering a set of documents, via feature attribution methods. However, these attributions are seen to weakly correlate and sometimes contradict each other. In classification/regression, several works focus on \emph{axiomatic characterization} of feature attribution methods, showing that a certain method uniquely satisfies a set of desirable properties. However, no such efforts have been taken in the space of feature attributions for the task of ranking. We take an axiomatic game-theoretic approach, popular in the feature attribution community, to identify candidate attribution methods for ranking tasks. We first define desirable axioms: Rank-Efficiency, Rank-Missingness, Rank-Symmetry and Rank-Monotonicity, all variants of the classical Shapley axioms. Next, we introduce Rank-SHAP, a feature attribution algorithm for the general ranking task, which is an extension to classical Shapley values. We identify a polynomial-time algorithm for computing approximate Rank-SHAP values and evaluate the computational efficiency and accuracy of our algorithm under various scenarios. We also evaluate its alignment with human intuition with a user study. Lastly, we theoretically examine popular rank attribution algorithms, EXS and Rank-LIME, and evaluate their capacity to satisfy the classical Shapley axioms.
Uncertainty in Additive Feature Attribution methods
Nov 29, 2023



In this work, we explore various topics that fall under the umbrella of Uncertainty in post-hoc Explainable AI (XAI) methods. We in particular focus on the class of additive feature attribution explanation methods. We first describe our specifications of uncertainty and compare various statistical and recent methods to quantify the same. Next, for a particular instance, we study the relationship between a feature's attribution and its uncertainty and observe little correlation. As a result, we propose a modification in the distribution from which perturbations are sampled in LIME-based algorithms such that the important features have minimal uncertainty without an increase in computational cost. Next, while studying how the uncertainty in explanations varies across the feature space of a classifier, we observe that a fraction of instances show near-zero uncertainty. We coin the term "stable instances" for such instances and diagnose factors that make an instance stable. Next, we study how an XAI algorithm's uncertainty varies with the size and complexity of the underlying model. We observe that the more complex the model, the more inherent uncertainty is exhibited by it. As a result, we propose a measure to quantify the relative complexity of a blackbox classifier. This could be incorporated, for example, in LIME-based algorithms' sampling densities, to help different explanation algorithms achieve tighter confidence levels. Together, the above measures would have a strong impact on making XAI models relatively trustworthy for the end-user as well as aiding scientific discovery.
Rank-LIME: Local Model-Agnostic Feature Attribution for Learning to Rank
Dec 24, 2022


Understanding why a model makes certain predictions is crucial when adapting it for real world decision making. LIME is a popular model-agnostic feature attribution method for the tasks of classification and regression. However, the task of learning to rank in information retrieval is more complex in comparison with either classification or regression. In this work, we extend LIME to propose Rank-LIME, a model-agnostic, local, post-hoc linear feature attribution method for the task of learning to rank that generates explanations for ranked lists. We employ novel correlation-based perturbations, differentiable ranking loss functions and introduce new metrics to evaluate ranking based additive feature attribution models. We compare Rank-LIME with a variety of competing systems, with models trained on the MS MARCO datasets and observe that Rank-LIME outperforms existing explanation algorithms in terms of Model Fidelity and Explain-NDCG. With this we propose one of the first algorithms to generate additive feature attributions for explaining ranked lists.
Corpora Evaluation and System Bias Detection in Multi-document Summarization
Oct 05, 2020
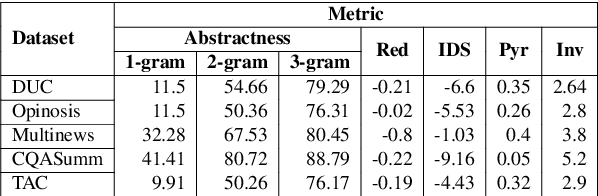

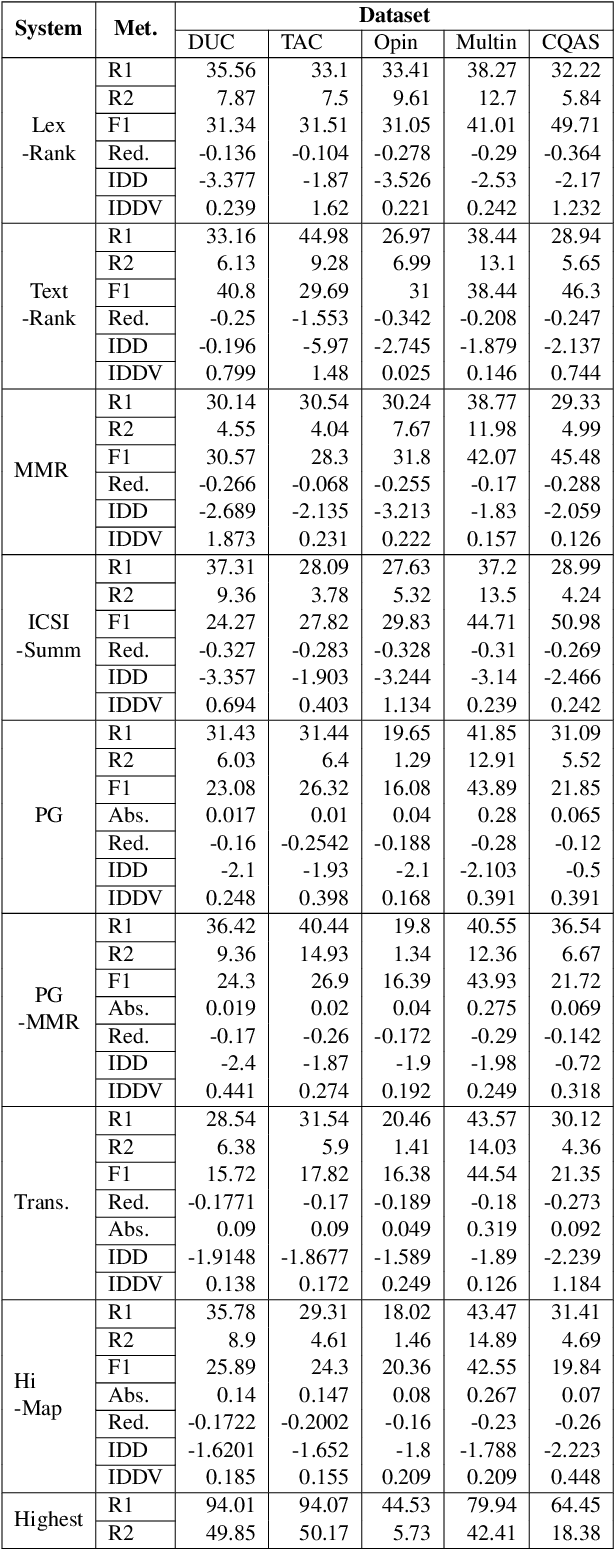
Multi-document summarization (MDS) is the task of reflecting key points from any set of documents into a concise text paragraph. In the past, it has been used to aggregate news, tweets, product reviews, etc. from various sources. Owing to no standard definition of the task, we encounter a plethora of datasets with varying levels of overlap and conflict between participating documents. There is also no standard regarding what constitutes summary information in MDS. Adding to the challenge is the fact that new systems report results on a set of chosen datasets, which might not correlate with their performance on the other datasets. In this paper, we study this heterogeneous task with the help of a few widely used MDS corpora and a suite of state-of-the-art models. We make an attempt to quantify the quality of summarization corpus and prescribe a list of points to consider while proposing a new MDS corpus. Next, we analyze the reason behind the absence of an MDS system which achieves superior performance across all corpora. We then observe the extent to which system metrics are influenced, and bias is propagated due to corpus properties. The scripts to reproduce the experiments in this work are available at https://github.com/LCS2-IIITD/summarization_bias.git.
Neural Abstractive Summarization with Structural Attention
Apr 21, 2020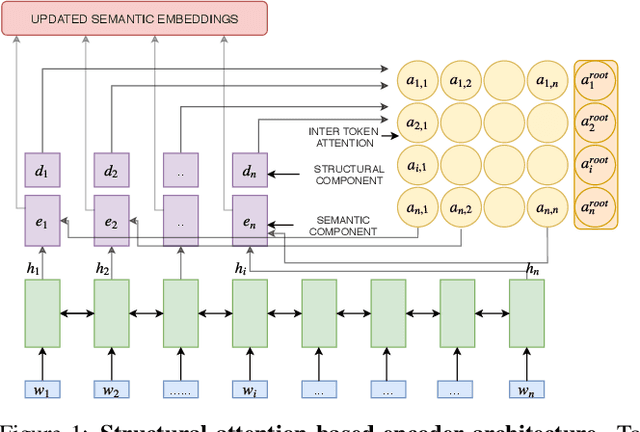
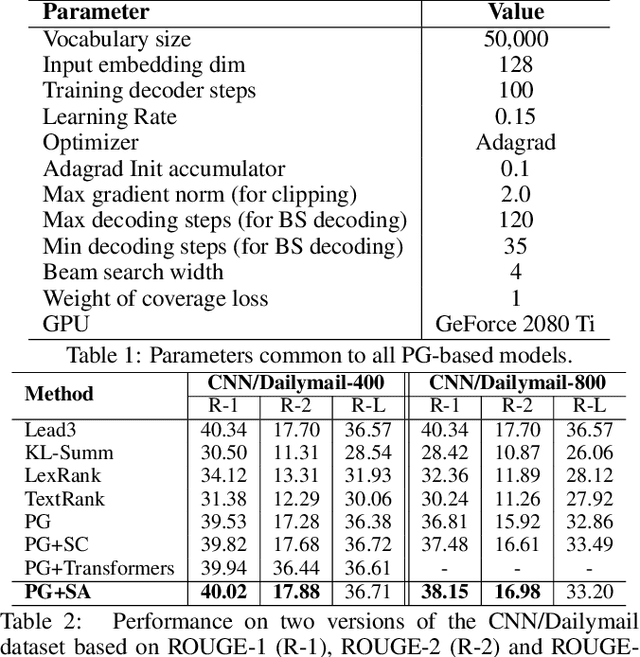
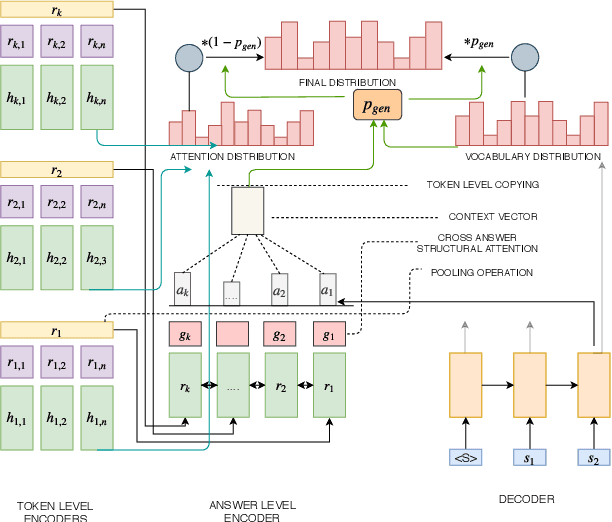
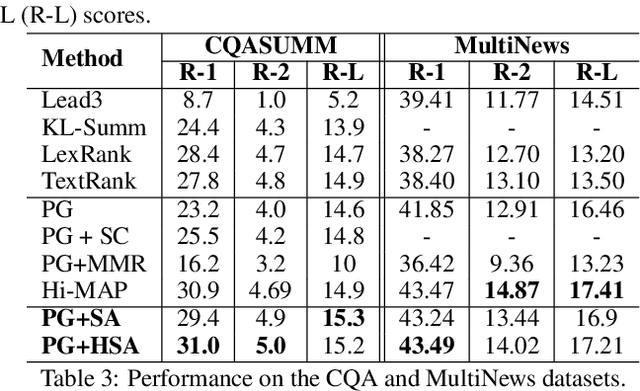
Attentional, RNN-based encoder-decoder architectures have achieved impressive performance on abstractive summarization of news articles. However, these methods fail to account for long term dependencies within the sentences of a document. This problem is exacerbated in multi-document summarization tasks such as summarizing the popular opinion in threads present in community question answering (CQA) websites such as Yahoo! Answers and Quora. These threads contain answers which often overlap or contradict each other. In this work, we present a hierarchical encoder based on structural attention to model such inter-sentence and inter-document dependencies. We set the popular pointer-generator architecture and some of the architectures derived from it as our baselines and show that they fail to generate good summaries in a multi-document setting. We further illustrate that our proposed model achieves significant improvement over the baselines in both single and multi-document summarization settings -- in the former setting, it beats the best baseline by 1.31 and 7.8 ROUGE-1 points on CNN and CQA datasets, respectively; in the latter setting, the performance is further improved by 1.6 ROUGE-1 points on the CQA dataset.
CQASUMM: Building References for Community Question Answering Summarization Corpora
Nov 12, 2018
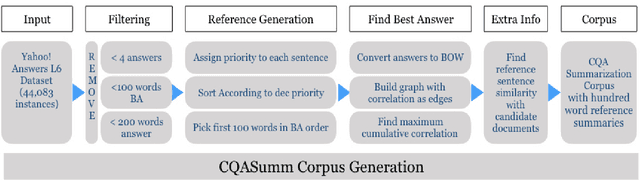
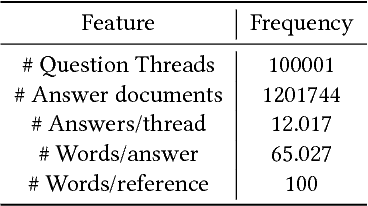

Community Question Answering forums such as Quora, Stackoverflow are rich knowledge resources, often catering to information on topics overlooked by major search engines. Answers submitted to these forums are often elaborated, contain spam, are marred by slurs and business promotions. It is difficult for a reader to go through numerous such answers to gauge community opinion. As a result summarization becomes a prioritized task for CQA forums. While a number of efforts have been made to summarize factoid CQA, little work exists in summarizing non-factoid CQA. We believe this is due to the lack of a considerably large, annotated dataset for CQA summarization. We create CQASUMM, the first huge annotated CQA summarization dataset by filtering the 4.4 million Yahoo! Answers L6 dataset. We sample threads where the best answer can double up as a reference summary and build hundred word summaries from them. We treat other answers as candidates documents for summarization. We provide a script to generate the dataset and introduce the new task of Community Question Answering Summarization. Multi document summarization has been widely studied with news article datasets, especially in the DUC and TAC challenges using news corpora. However documents in CQA have higher variance, contradicting opinion and lesser amount of overlap. We compare the popular multi document summarization techniques and evaluate their performance on our CQA corpora. We look into the state-of-the-art and understand the cases where existing multi document summarizers (MDS) fail. We find that most MDS workflows are built for the entirely factual news corpora, whereas our corpus has a fair share of opinion based instances too. We therefore introduce OpinioSumm, a new MDS which outperforms the best baseline by 4.6% w.r.t ROUGE-1 score.