 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Editing with Graph-Based External Memory
May 23, 2025Large language models (LLMs) have revolutionized natural language processing, yet their practical utility is often limited by persistent issues of hallucinations and outdated parametric knowledge. Although post-training model editing offers a pathway for dynamic updates, existing methods frequently suffer from overfitting and catastrophic forgetting. To tackle these challenges, we propose a novel framework that leverages hyperbolic geometry and graph neural networks for precise and stable model edits. We introduce HYPE (HYperbolic Parameter Editing), which comprises three key components: (i) Hyperbolic Graph Construction, which uses Poincar\'e embeddings to represent knowledge triples in hyperbolic space, preserving hierarchical relationships and preventing unintended side effects by ensuring that edits to parent concepts do not inadvertently affect child concepts; (ii) M\"obius-Transformed Updates, which apply hyperbolic addition to propagate edits while maintaining structural consistency within the hyperbolic manifold, unlike conventional Euclidean updates that distort relational distances; and (iii) Dual Stabilization, which combines gradient masking and periodic GNN parameter resetting to prevent catastrophic forgetting by focusing updates on critical parameters and preserving long-term knowledge. Experiments on CounterFact, CounterFact+, and MQuAKE with GPT-J and GPT2-XL demonstrate that HYPE significantly enhances edit stability, factual accuracy, and multi-hop reasoning.
Continually Self-Improving Language Models for Bariatric Surgery Question--Answering
May 22, 2025While bariatric and metabolic surgery (MBS) is considered the gold standard treatment for severe and morbid obesity, its therapeutic efficacy hinges upon active and longitudinal engagement with multidisciplinary providers, including surgeons, dietitians/nutritionists, psychologists, and endocrinologists. This engagement spans the entire patient journey, from preoperative preparation to long-term postoperative management. However, this process is often hindered by numerous healthcare disparities, such as logistical and access barriers, which impair easy patient access to timely, evidence-based, clinician-endorsed information. To address these gaps, we introduce bRAGgen, a novel adaptive retrieval-augmented generation (RAG)-based model that autonomously integrates real-time medical evidence when response confidence dips below dynamic thresholds. This self-updating architecture ensures that responses remain current and accurate, reducing the risk of misinformation. Additionally, we present bRAGq, a curated dataset of 1,302 bariatric surgery--related questions, validated by an expert bariatric surgeon. bRAGq constitutes the first large-scale, domain-specific benchmark for comprehensive MBS care. In a two-phase evaluation, bRAGgen is benchmarked against state-of-the-art models using both large language model (LLM)--based metrics and expert surgeon review. Across all evaluation dimensions, bRAGgen demonstrates substantially superior performance in generating clinically accurate and relevant responses.
Exploiting Representation Bias for Data Distillation in Abstractive Text Summarization
Dec 20, 2023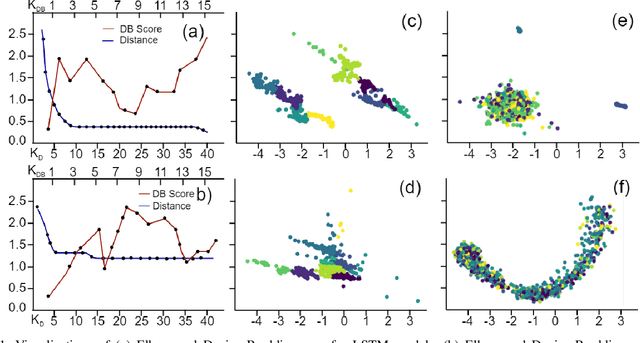
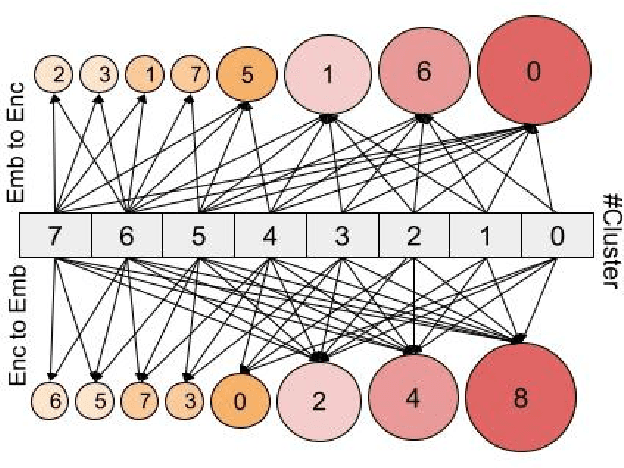
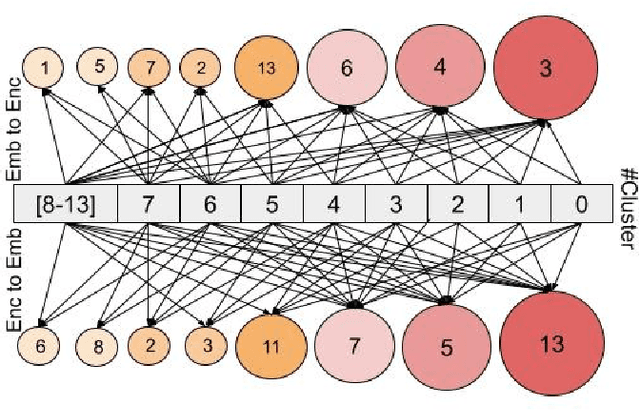
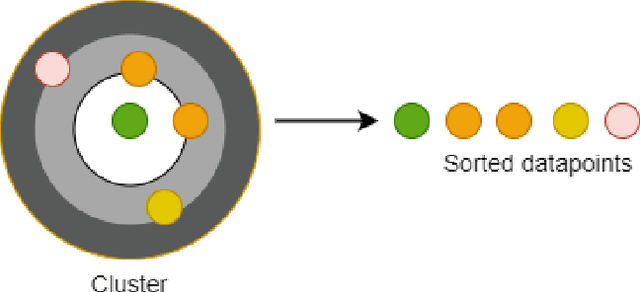
Abstractive text summarization is surging with the number of training samples to cater to the needs of the deep learning models. These models tend to exploit the training data representations to attain superior performance by improving the quantitative element of the resultant summary. However, increasing the size of the training set may not always be the ideal solution to maximize the performance, and therefore, a need to revisit the quality of training samples and the learning protocol of deep learning models is a must. In this paper, we aim to discretize the vector space of the abstractive text summarization models to understand the characteristics learned between the input embedding space and the models' encoder space. We show that deep models fail to capture the diversity of the input space. Further, the distribution of data points on the encoder space indicates that an unchecked increase in the training samples does not add value; rather, a tear-down of data samples is highly needed to make the models focus on variability and faithfulness. We employ clustering techniques to learn the diversity of a model's sample space and how data points are mapped from the embedding space to the encoder space and vice versa. Further, we devise a metric to filter out redundant data points to make the model more robust and less data hungry. We benchmark our proposed method using quantitative metrics, such as Rouge, and qualitative metrics, such as BERTScore, FEQA and Pyramid score. We also quantify the reasons that inhibit the models from learning the diversity from the varied input samples.
Fusing Multimodal Signals on Hyper-complex Space for Extreme Abstractive Text Summarization (TL;DR) of Scientific Contents
Jun 24, 2023



The realm of scientific text summarization has experienced remarkable progress due to the availability of annotated brief summaries and ample data. However, the utilization of multiple input modalities, such as videos and audio, has yet to be thoroughly explored. At present, scientific multimodal-input-based text summarization systems tend to employ longer target summaries like abstracts, leading to an underwhelming performance in the task of text summarization. In this paper, we deal with a novel task of extreme abstractive text summarization (aka TL;DR generation) by leveraging multiple input modalities. To this end, we introduce mTLDR, a first-of-its-kind dataset for the aforementioned task, comprising videos, audio, and text, along with both author-composed summaries and expert-annotated summaries. The mTLDR dataset accompanies a total of 4,182 instances collected from various academic conference proceedings, such as ICLR, ACL, and CVPR. Subsequently, we present mTLDRgen, an encoder-decoder-based model that employs a novel dual-fused hyper-complex Transformer combined with a Wasserstein Riemannian Encoder Transformer, to dexterously capture the intricacies between different modalities in a hyper-complex latent geometric space. The hyper-complex Transformer captures the intrinsic properties between the modalities, while the Wasserstein Riemannian Encoder Transformer captures the latent structure of the modalities in the latent space geometry, thereby enabling the model to produce diverse sentences. mTLDRgen outperforms 20 baselines on mTLDR as well as another non-scientific dataset (How2) across three Rouge-based evaluation measures. Furthermore, based on the qualitative metrics, BERTScore and FEQA, and human evaluations, we demonstrate that the summaries generated by mTLDRgen are fluent and congruent to the original source material.
Inline Citation Classification using Peripheral Context and Time-evolving Augmentation
Mar 01, 2023



Citation plays a pivotal role in determining the associations among research articles. It portrays essential information in indicative, supportive, or contrastive studies. The task of inline citation classification aids in extrapolating these relationships; However, existing studies are still immature and demand further scrutiny. Current datasets and methods used for inline citation classification only use citation-marked sentences constraining the model to turn a blind eye to domain knowledge and neighboring contextual sentences. In this paper, we propose a new dataset, named 3Cext, which along with the cited sentences, provides discourse information using the vicinal sentences to analyze the contrasting and entailing relationships as well as domain information. We propose PeriCite, a Transformer-based deep neural network that fuses peripheral sentences and domain knowledge. Our model achieves the state-of-the-art on the 3Cext dataset by +0.09 F1 against the best baseline. We conduct extensive ablations to analyze the efficacy of the proposed dataset and model fusion methods.
Assessing the Quality of the Datasets by Identifying Mislabeled Samples
Sep 10, 2021

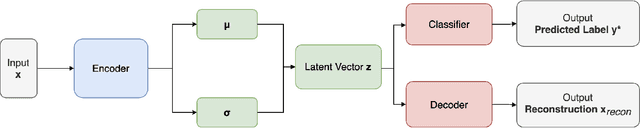
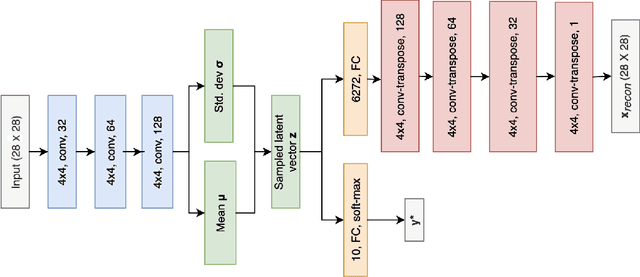
Due to the over-emphasize of the quantity of data, the data quality has often been overlooked. However, not all training data points contribute equally to learning. In particular, if mislabeled, it might actively damage the performance of the model and the ability to generalize out of distribution, as the model might end up learning spurious artifacts present in the dataset. This problem gets compounded by the prevalence of heavily parameterized and complex deep neural networks, which can, with their high capacity, end up memorizing the noise present in the dataset. This paper proposes a novel statistic -- noise score, as a measure for the quality of each data point to identify such mislabeled samples based on the variations in the latent space representation. In our work, we use the representations derived by the inference network of data quality supervised variational autoencoder (AQUAVS). Our method leverages the fact that samples belonging to the same class will have similar latent representations. Therefore, by identifying the outliers in the latent space, we can find the mislabeled samples. We validate our proposed statistic through experimentation by corrupting MNIST, FashionMNIST, and CIFAR10/100 datasets in different noise settings for the task of identifying mislabelled samples. We further show significant improvements in accuracy for the classification task for each dataset.
See, Hear, Read: Leveraging Multimodality with Guided Attention for Abstractive Text Summarization
May 20, 2021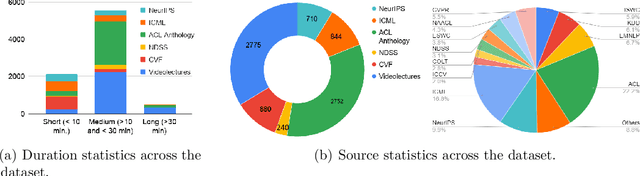
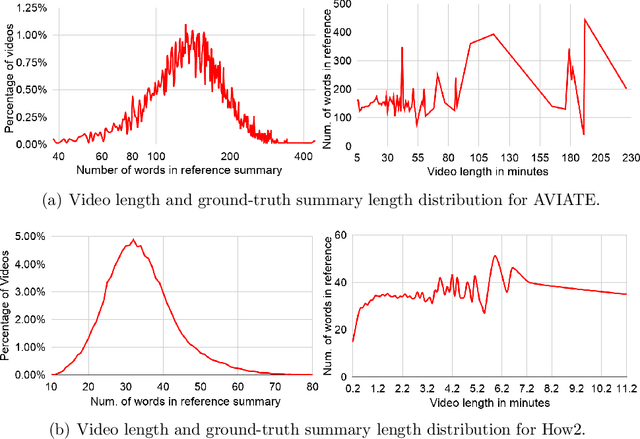
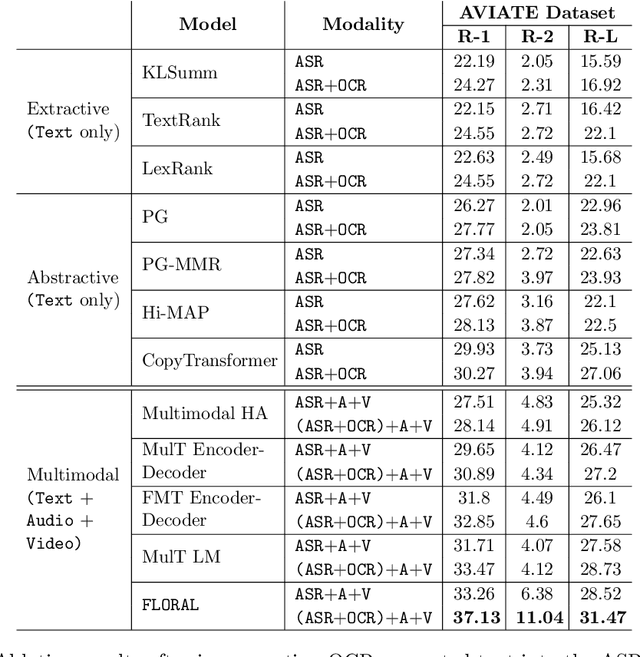
In recent years, abstractive text summarization with multimodal inputs has started drawing attention due to its ability to accumulate information from different source modalities and generate a fluent textual summary. However, existing methods use short videos as the visual modality and short summary as the ground-truth, therefore, perform poorly on lengthy videos and long ground-truth summary. Additionally, there exists no benchmark dataset to generalize this task on videos of varying lengths. In this paper, we introduce AVIATE, the first large-scale dataset for abstractive text summarization with videos of diverse duration, compiled from presentations in well-known academic conferences like NDSS, ICML, NeurIPS, etc. We use the abstract of corresponding research papers as the reference summaries, which ensure adequate quality and uniformity of the ground-truth. We then propose {\name}, a factorized multi-modal Transformer based decoder-only language model, which inherently captures the intra-modal and inter-modal dynamics within various input modalities for the text summarization task. {\name} utilizes an increasing number of self-attentions to capture multimodality and performs significantly better than traditional encoder-decoder based networks. Extensive experiments illustrate that {\name} achieves significant improvement over the baselines in both qualitative and quantitative evaluations on the existing How2 dataset for short videos and newly introduced AVIATE dataset for videos with diverse duration, beating the best baseline on the two datasets by $1.39$ and $2.74$ ROUGE-L points respectively.
Corpora Evaluation and System Bias Detection in Multi-document Summarization
Oct 05, 2020
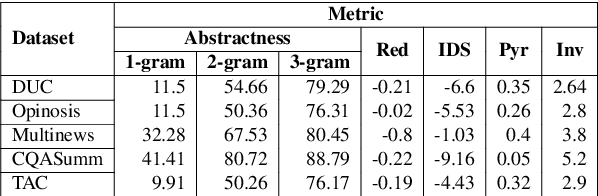

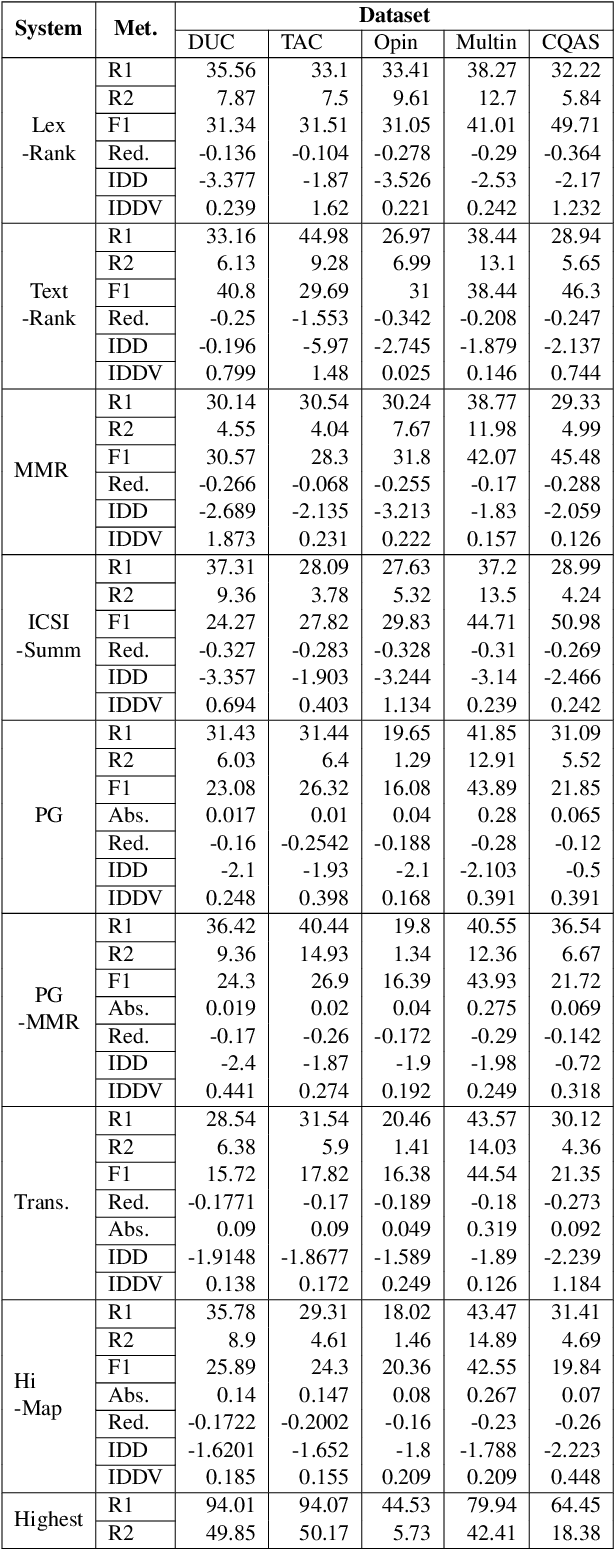
Multi-document summarization (MDS) is the task of reflecting key points from any set of documents into a concise text paragraph. In the past, it has been used to aggregate news, tweets, product reviews, etc. from various sources. Owing to no standard definition of the task, we encounter a plethora of datasets with varying levels of overlap and conflict between participating documents. There is also no standard regarding what constitutes summary information in MDS. Adding to the challenge is the fact that new systems report results on a set of chosen datasets, which might not correlate with their performance on the other datasets. In this paper, we study this heterogeneous task with the help of a few widely used MDS corpora and a suite of state-of-the-art models. We make an attempt to quantify the quality of summarization corpus and prescribe a list of points to consider while proposing a new MDS corpus. Next, we analyze the reason behind the absence of an MDS system which achieves superior performance across all corpora. We then observe the extent to which system metrics are influenced, and bias is propagated due to corpus properties. The scripts to reproduce the experiments in this work are available at https://github.com/LCS2-IIITD/summarization_bias.git.