 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISSECT: Diagnosing Where Vision Ends and Language Priors Begin in Scientific VLMs
Apr 06, 2026When asked to describe a molecular diagram, a Vision-Language Model correctly identifies ``a benzene ring with an -OH group.'' When asked to reason about the same image, it answers incorrectly. The model can see but it cannot think about what it sees. We term this the perception-integration gap: a failure where visual information is successfully extracted but lost during downstream reasoning, invisible to single-configuration benchmarks that conflate perception with integration under one accuracy number. To systematically expose such failures, we introduce DISSECT, a 12,000-question diagnostic benchmark spanning Chemistry (7,000) and Biology (5,000). Every question is evaluated under five input modes -- Vision+Text, Text-Only, Vision-Only, Human Oracle, and a novel Model Oracle in which the VLM first verbalizes the image and then reasons from its own description -- yielding diagnostic gaps that decompose performance into language-prior exploitation, visual extraction, perception fidelity, and integration effectiveness. Evaluating 18~VLMs, we find that: (1) Chemistry exhibits substantially lower language-prior exploitability than Biology, confirming molecular visual content as a harder test of genuine visual reasoning; (2) Open-source models consistently score higher when reasoning from their own verbalized descriptions than from raw images, exposing a systematic integration bottleneck; and (3) Closed-source models show no such gap, indicating that bridging perception and integration is the frontier separating open-source from closed-source multimodal capability. The Model Oracle protocol is both model and benchmark agnostic, applicable post-hoc to any VLM evaluation to diagnose integration failures.
Public Profile Matters: A Scalable Integrated Approach to Recommend Citations in the Wild
Mar 18, 2026Proper citation of relevant literature is essential for contextualising and validating scientific contributions. While current citation recommendation systems leverage local and global textual information, they often overlook the nuances of the human citation behaviour. Recent methods that incorporate such patterns improve performance but incur high computational costs and introduce systematic biases into downstream rerankers. To address this, we propose Profiler, a lightweight, non-learnable module that captures human citation patterns efficiently and without bias, significantly enhancing candidate retrieval. Furthermore, we identify a critical limitation in current evaluation protocol: the systems are assessed in a transductive setting, which fails to reflect real-world scenarios. We introduce a rigorous Inductive evaluation setting that enforces strict temporal constraints, simulating the recommendation of citations for newly authored papers in the wild. Finally, we present DAVINCI, a novel reranking model that integrates profiler-derived confidence priors with semantic information via an adaptive vector-gating mechanism. Our system achieves new state-of-the-art results across multiple benchmark datasets, demonstrating superior efficiency and generalisability.
Tox-BART: Leveraging Toxicity Attributes for Explanation Generation of Implicit Hate Speech
Jun 06, 2024



Employing language models to generate explanations for an incoming implicit hate post is an active area of research. The explanation is intended to make explicit the underlying stereotype and aid content moderators. The training often combines top-k relevant knowledge graph (KG) tuples to provide world knowledge and improve performance on standard metrics. Interestingly, our study presents conflicting evidence for the role of the quality of KG tuples in generating implicit explanations. Consequently, simpler models incorporating external toxicity signals outperform KG-infused models. Compared to the KG-based setup, we observe a comparable performance for SBIC (LatentHatred) datasets with a performance variation of +0.44 (+0.49), +1.83 (-1.56), and -4.59 (+0.77) in BLEU, ROUGE-L, and BERTScore. Further human evaluation and error analysis reveal that our proposed setup produces more precise explanations than zero-shot GPT-3.5, highlighting the intricate nature of the task.
SymTax: Symbiotic Relationship and Taxonomy Fusion for Effective Citation Recommendation
May 26, 2024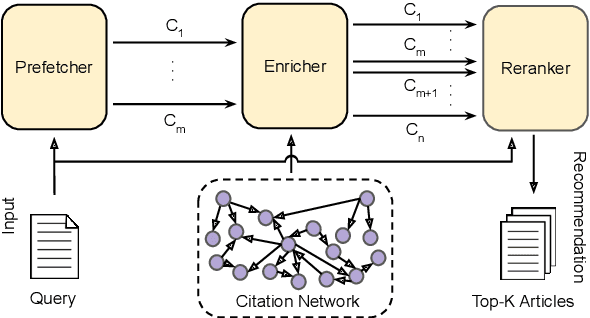



Citing pertinent literature is pivotal to writing and reviewing a scientific document. Existing techniques mainly focus on the local context or the global context for recommending citations but fail to consider the actual human citation behaviour. We propose SymTax, a three-stage recommendation architecture that considers both the local and the global context, and additionally the taxonomical representations of query-candidate tuples and the Symbiosis prevailing amongst them. SymTax learns to embed the infused taxonomies in the hyperbolic space and uses hyperbolic separation as a latent feature to compute query-candidate similarity. We build a novel and large dataset ArSyTa containing 8.27 million citation contexts and describe the creation process in detail. We conduct extensive experiments and ablation studies to demonstrate the effectiveness and design choice of each module in our framework. Also, combinatorial analysis from our experiments shed light on the choice of language models (LMs) and fusion embedding, and the inclusion of section heading as a signal. Our proposed module that captures the symbiotic relationship solely leads to performance gains of 26.66% and 39.25% in Recall@5 w.r.t. SOTA on ACL-200 and RefSeer datasets, respectively. The complete framework yields a gain of 22.56% in Recall@5 wrt SOTA on our proposed dataset. The code and dataset are available at https://github.com/goyalkaraniit/SymTax
Probing Critical Learning Dynamics of PLMs for Hate Speech Detection
Feb 03, 2024Despite the widespread adoption, there is a lack of research into how various critical aspects of pretrained language models (PLMs) affect their performance in hate speech detection. Through five research questions, our findings and recommendations lay the groundwork for empirically investigating different aspects of PLMs' use in hate speech detection. We deep dive into comparing different pretrained models, evaluating their seed robustness, finetuning settings, and the impact of pretraining data collection time. Our analysis reveals early peaks for downstream tasks during pretraining, the limited benefit of employing a more recent pretraining corpus, and the significance of specific layers during finetuning. We further call into question the use of domain-specific models and highlight the need for dynamic datasets for benchmarking hate speech detection.
Exploiting Representation Bias for Data Distillation in Abstractive Text Summarization
Dec 20, 2023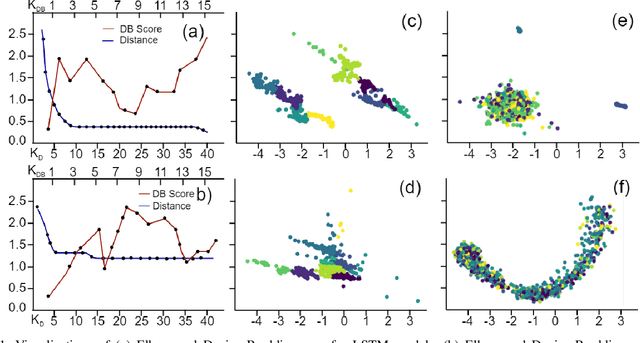
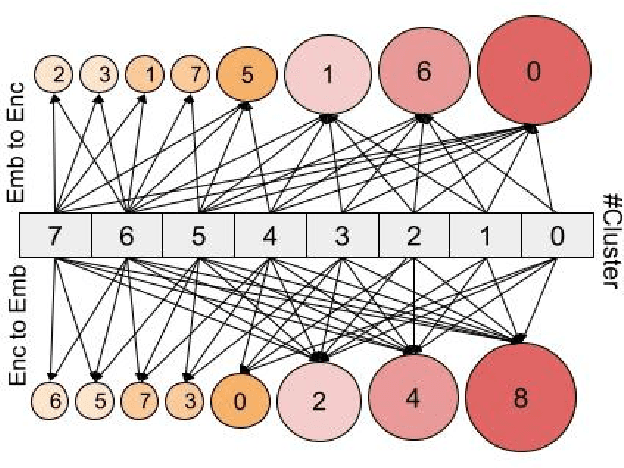
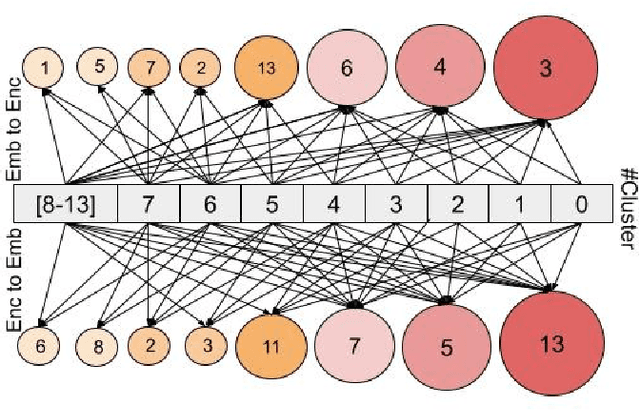
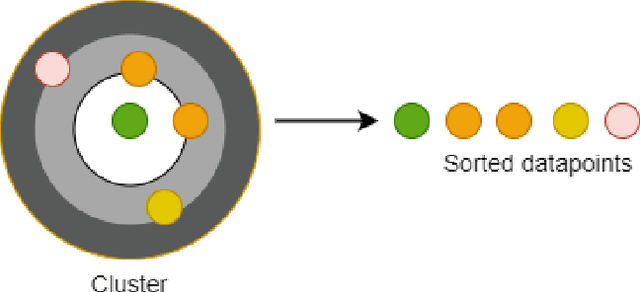
Abstractive text summarization is surging with the number of training samples to cater to the needs of the deep learning models. These models tend to exploit the training data representations to attain superior performance by improving the quantitative element of the resultant summary. However, increasing the size of the training set may not always be the ideal solution to maximize the performance, and therefore, a need to revisit the quality of training samples and the learning protocol of deep learning models is a must. In this paper, we aim to discretize the vector space of the abstractive text summarization models to understand the characteristics learned between the input embedding space and the models' encoder space. We show that deep models fail to capture the diversity of the input space. Further, the distribution of data points on the encoder space indicates that an unchecked increase in the training samples does not add value; rather, a tear-down of data samples is highly needed to make the models focus on variability and faithfulness. We employ clustering techniques to learn the diversity of a model's sample space and how data points are mapped from the embedding space to the encoder space and vice versa. Further, we devise a metric to filter out redundant data points to make the model more robust and less data hungry. We benchmark our proposed method using quantitative metrics, such as Rouge, and qualitative metrics, such as BERTScore, FEQA and Pyramid score. We also quantify the reasons that inhibit the models from learning the diversity from the varied input samples.
Army of Thieves: Enhancing Black-Box Model Extraction via Ensemble based sample selection
Nov 08, 2023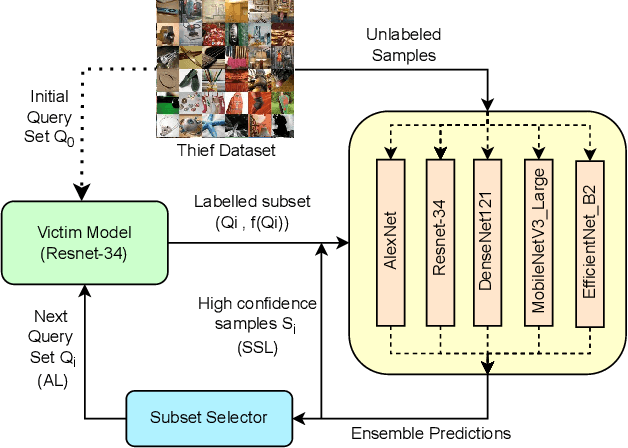
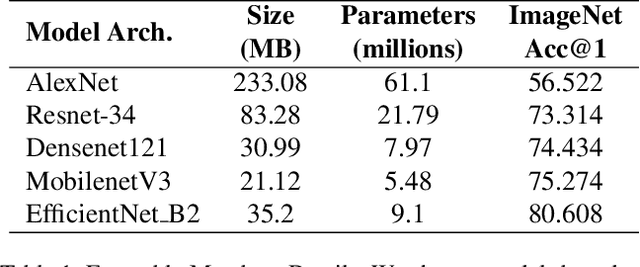

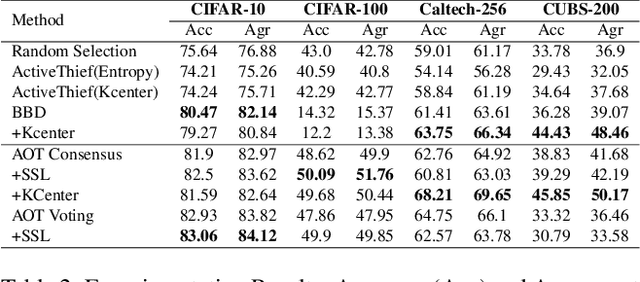
Machine Learning (ML) models become vulnerable to Model Stealing Attacks (MSA) when they are deployed as a service. In such attacks, the deployed model is queried repeatedly to build a labelled dataset. This dataset allows the attacker to train a thief model that mimics the original model. To maximize query efficiency, the attacker has to select the most informative subset of data points from the pool of available data. Existing attack strategies utilize approaches like Active Learning and Semi-Supervised learning to minimize costs. However, in the black-box setting, these approaches may select sub-optimal samples as they train only one thief model. Depending on the thief model's capacity and the data it was pretrained on, the model might even select noisy samples that harm the learning process. In this work, we explore the usage of an ensemble of deep learning models as our thief model. We call our attack Army of Thieves(AOT) as we train multiple models with varying complexities to leverage the crowd's wisdom. Based on the ensemble's collective decision, uncertain samples are selected for querying, while the most confident samples are directly included in the training data. Our approach is the first one to utilize an ensemble of thief models to perform model extraction. We outperform the base approaches of existing state-of-the-art methods by at least 3% and achieve a 21% higher adversarial sample transferability than previous work for models trained on the CIFAR-10 dataset.
MWPRanker: An Expression Similarity Based Math Word Problem Retriever
Jul 03, 2023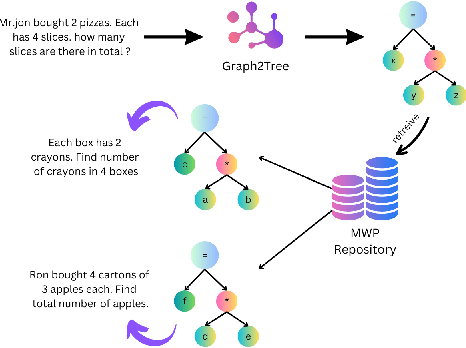
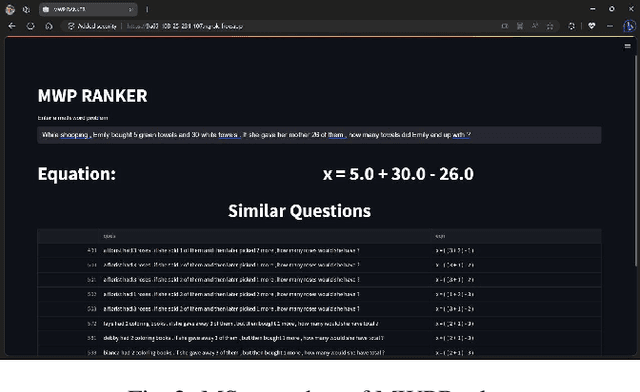
Math Word Problems (MWPs) in online assessments help test the ability of the learner to make critical inferences by interpreting the linguistic information in them. To test the mathematical reasoning capabilities of the learners, sometimes the problem is rephrased or the thematic setting of the original MWP is changed. Since manual identification of MWPs with similar problem models is cumbersome, we propose a tool in this work for MWP retrieval. We propose a hybrid approach to retrieve similar MWPs with the same problem model. In our work, the problem model refers to the sequence of operations to be performed to arrive at the solution. We demonstrate that our tool is useful for the mentioned tasks and better than semantic similarity-based approaches, which fail to capture the arithmetic and logical sequence of the MWPs. A demo of the tool can be found at https://www.youtube.com/watch?v=gSQWP3chFIs
Fusing Multimodal Signals on Hyper-complex Space for Extreme Abstractive Text Summarization (TL;DR) of Scientific Contents
Jun 24, 2023



The realm of scientific text summarization has experienced remarkable progress due to the availability of annotated brief summaries and ample data. However, the utilization of multiple input modalities, such as videos and audio, has yet to be thoroughly explored. At present, scientific multimodal-input-based text summarization systems tend to employ longer target summaries like abstracts, leading to an underwhelming performance in the task of text summarization. In this paper, we deal with a novel task of extreme abstractive text summarization (aka TL;DR generation) by leveraging multiple input modalities. To this end, we introduce mTLDR, a first-of-its-kind dataset for the aforementioned task, comprising videos, audio, and text, along with both author-composed summaries and expert-annotated summaries. The mTLDR dataset accompanies a total of 4,182 instances collected from various academic conference proceedings, such as ICLR, ACL, and CVPR. Subsequently, we present mTLDRgen, an encoder-decoder-based model that employs a novel dual-fused hyper-complex Transformer combined with a Wasserstein Riemannian Encoder Transformer, to dexterously capture the intricacies between different modalities in a hyper-complex latent geometric space. The hyper-complex Transformer captures the intrinsic properties between the modalities, while the Wasserstein Riemannian Encoder Transformer captures the latent structure of the modalities in the latent space geometry, thereby enabling the model to produce diverse sentences. mTLDRgen outperforms 20 baselines on mTLDR as well as another non-scientific dataset (How2) across three Rouge-based evaluation measures. Furthermore, based on the qualitative metrics, BERTScore and FEQA, and human evaluations, we demonstrate that the summaries generated by mTLDRgen are fluent and congruent to the original source material.
Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment
Jun 15, 2023



Social media is awash with hateful content, much of which is often veiled with linguistic and topical diversity. The benchmark datasets used for hate speech detection do not account for such divagation as they are predominantly compiled using hate lexicons. However, capturing hate signals becomes challenging in neutrally-seeded malicious content. Thus, designing models and datasets that mimic the real-world variability of hate warrants further investigation. To this end, we present GOTHate, a large-scale code-mixed crowdsourced dataset of around 51k posts for hate speech detection from Twitter. GOTHate is neutrally seeded, encompassing different languages and topics. We conduct detailed comparisons of GOTHate with the existing hate speech datasets, highlighting its novelty. We benchmark it with 10 recent baselines. Our extensive empirical and benchmarking experiments suggest that GOTHate is hard to classify in a text-only setup. Thus, we investigate how adding endogenous signals enhances the hate speech detection task. We augment GOTHate with the user's timeline information and ego network, bringing the overall data source closer to the real-world setup for understanding hateful content. Our proposed solution HEN-mBERT is a modular, multilingual, mixture-of-experts model that enriches the linguistic subspace with latent endogenous signals from history, topology, and exemplars. HEN-mBERT transcends the best baseline by 2.5% and 5% in overall macro-F1 and hate class F1, respectively. Inspired by our experiments, in partnership with Wipro AI, we are developing a semi-automated pipeline to detect hateful content as a part of their mission to tackle online harm.