 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Representation Bias for Data Distillation in Abstractive Text Summarization
Paper and Code
Dec 20, 2023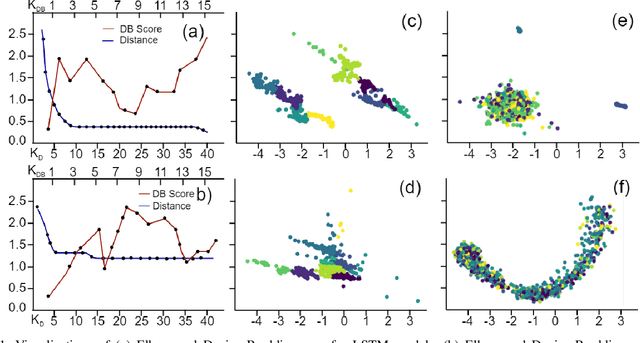
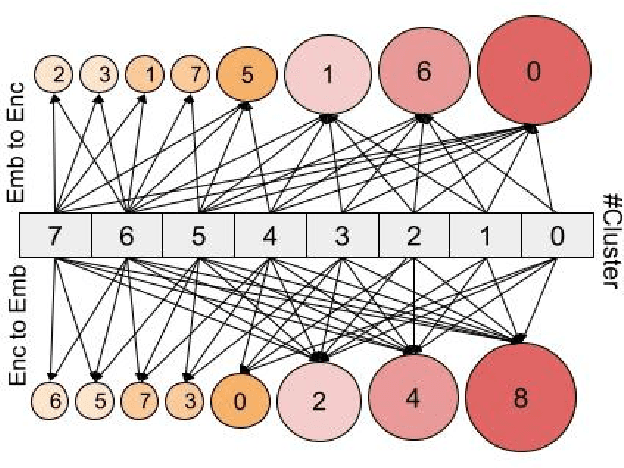
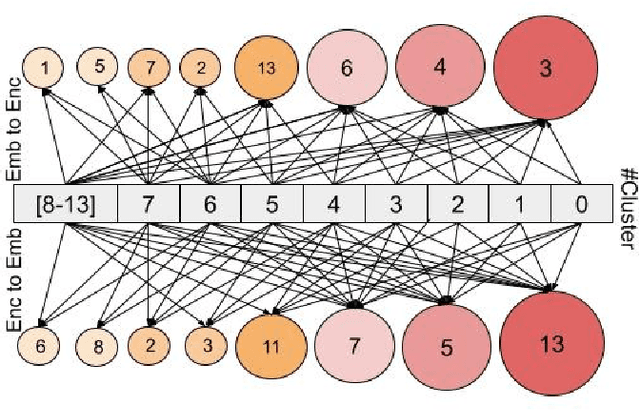
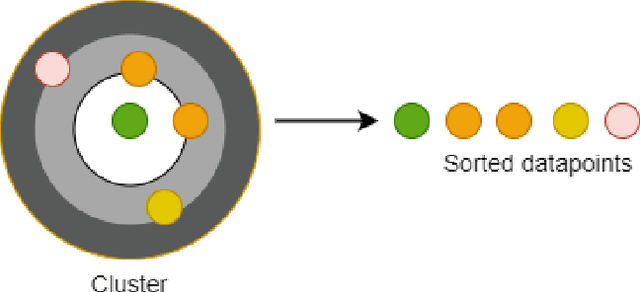
Abstractive text summarization is surging with the number of training samples to cater to the needs of the deep learning models. These models tend to exploit the training data representations to attain superior performance by improving the quantitative element of the resultant summary. However, increasing the size of the training set may not always be the ideal solution to maximize the performance, and therefore, a need to revisit the quality of training samples and the learning protocol of deep learning models is a must. In this paper, we aim to discretize the vector space of the abstractive text summarization models to understand the characteristics learned between the input embedding space and the models' encoder space. We show that deep models fail to capture the diversity of the input space. Further, the distribution of data points on the encoder space indicates that an unchecked increase in the training samples does not add value; rather, a tear-down of data samples is highly needed to make the models focus on variability and faithfulness. We employ clustering techniques to learn the diversity of a model's sample space and how data points are mapped from the embedding space to the encoder space and vice versa. Further, we devise a metric to filter out redundant data points to make the model more robust and less data hungry. We benchmark our proposed method using quantitative metrics, such as Rouge, and qualitative metrics, such as BERTScore, FEQA and Pyramid score. We also quantify the reasons that inhibit the models from learning the diversity from the varied input samples.