 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientSign: An Attention-Enhanced Lightweight Architecture for Indian Sign Language Recognition
Apr 09, 2026How do you build a sign language recognizer that works on a phone? That question drove this work. We built EfficientSign, a lightweight model which takes EfficientNet-B0 and focuses on two attention modules (Squeeze-and-Excitation for channel focus, and a spatial attention layer that focuses on the hand gestures). We tested it against five other approaches on 12,637 images of Indian Sign Language alphabets, all 26 classes, using 5-fold cross-validation. EfficientSign achieves the accuracy of 99.94% (+/-0.05%), which matches the performance of ResNet18's 99.97% accuracy, but with 62% fewer parameters (4.2M vs 11.2M). We also experimented with feeding deep features (1,280-dimensional vectors pulled from EfficientNet-B0's pooling layer) into classical classifiers. SVM achieved the accuracy of 99.63%, Logistic Regression achieved the accuracy of 99.03% and KNN achieved accuracy of 96.33%. All of these blow past the 92% that SURF-based methods managed on a similar dataset back in 2015. Our results show that attention-enhanced learning model provides an efficient and deployable solution for ISL recognition without requiring a massive model or hand-tuned feature pipelines anymore.
Spectral methods: crucial for machine learning, natural for quantum computers?
Mar 25, 2026This article presents an argument for why quantum computers could unlock new methods for machine learning. We argue that spectral methods, in particular those that learn, regularise, or otherwise manipulate the Fourier spectrum of a machine learning model, are often natural for quantum computers. For example, if a generative machine learning model is represented by a quantum state, the Quantum Fourier Transform allows us to manipulate the Fourier spectrum of the state using the entire toolbox of quantum routines, an operation that is usually prohibitive for classical models. At the same time, spectral methods are surprisingly fundamental to machine learning: A spectral bias has recently been hypothesised to be the core principle behind the success of deep learning; support vector machines have been known for decades to regularise in Fourier space, and convolutional neural nets build filters in the Fourier space of images. Could, then, quantum computing open fundamentally different, much more direct and resource-efficient ways to design the spectral properties of a model? We discuss this potential in detail here, hoping to stimulate a direction in quantum machine learning research that puts the question of ``why quantum?'' first.
An Evaluation of Context Length Extrapolation in Long Code via Positional Embeddings and Efficient Attention
Feb 25, 2026The rapid advancement of large language models (LLMs) has led to a significant increase in automated tools in the software engineering, capable of performing various code-related tasks such as code generation, completion, and translation. Despite these advancements, its effectiveness is constrained by fixed context lengths, limiting its ability to generalize across long, domain-specific code sequences. To address this challenge, we investigate zero-shot, inference-only methods aimed at improving position encodings and optimizing attention mechanisms. Our goal is to provide a thorough analysis of current approaches that facilitate context length extrapolation in code, particularly in the context of long code completion tasks.
ReXCL: A Tool for Requirement Document Extraction and Classification
Apr 10, 2025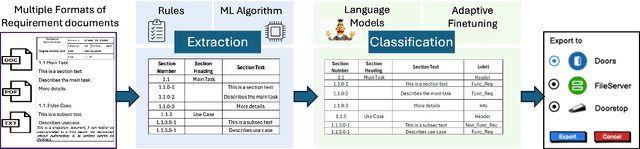
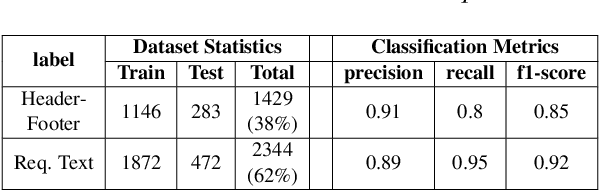
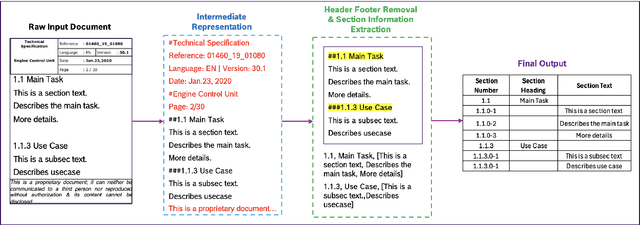
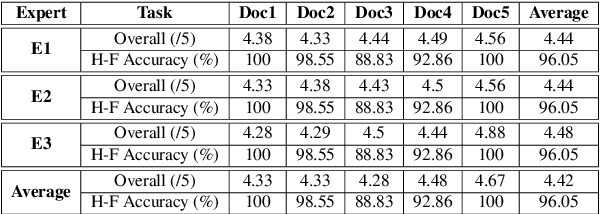
This paper presents the ReXCL tool, which automates the extraction and classification processes in requirement engineering, enhancing the software development lifecycle. The tool features two main modules: Extraction, which processes raw requirement documents into a predefined schema using heuristics and predictive modeling, and Classification, which assigns class labels to requirements using adaptive fine-tuning of encoder-based models. The final output can be exported to external requirement engineering tools. Performance evaluations indicate that ReXCL significantly improves efficiency and accuracy in managing requirements, marking a novel approach to automating the schematization of semi-structured requirement documents.
MAIDS: Malicious Agent Identification-based Data Security Model for Cloud Environments
Dec 19, 2024With the vigorous development of cloud computing, most organizations have shifted their data and applications to the cloud environment for storage, computation, and sharing purposes. During storage and data sharing across the participating entities, a malicious agent may gain access to outsourced data from the cloud environment. A malicious agent is an entity that deliberately breaches the data. This information accessed might be misused or revealed to unauthorized parties. Therefore, data protection and prediction of malicious agents have become a demanding task that needs to be addressed appropriately. To deal with this crucial and challenging issue, this paper presents a Malicious Agent Identification-based Data Security (MAIDS) Model which utilizes XGBoost machine learning classification algorithm for securing data allocation and communication among different participating entities in the cloud system. The proposed model explores and computes intended multiple security parameters associated with online data communication or transactions. Correspondingly, a security-focused knowledge database is produced for developing the XGBoost Classifier-based Malicious Agent Prediction (XC-MAP) unit. Unlike the existing approaches, which only identify malicious agents after data leaks, MAIDS proactively identifies malicious agents by examining their eligibility for respective data access. In this way, the model provides a comprehensive solution to safeguard crucial data from both intentional and non-intentional breaches, by granting data to authorized agents only by evaluating the agents behavior and predicting the malicious agent before granting data.
* 28 pages, 10 figures
Selective Shot Learning for Code Explanation
Dec 17, 2024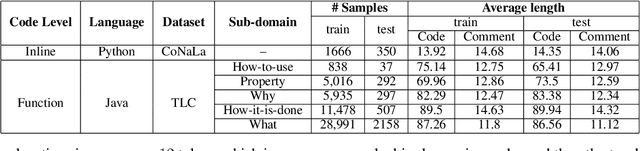
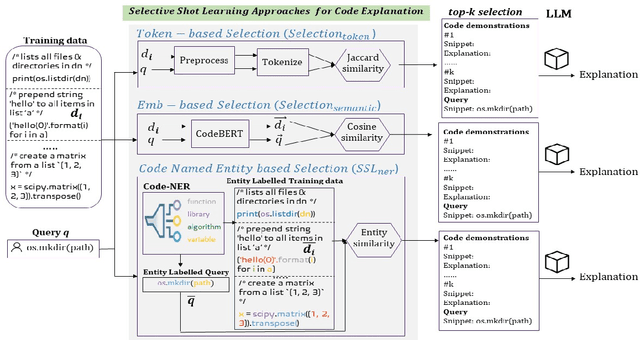
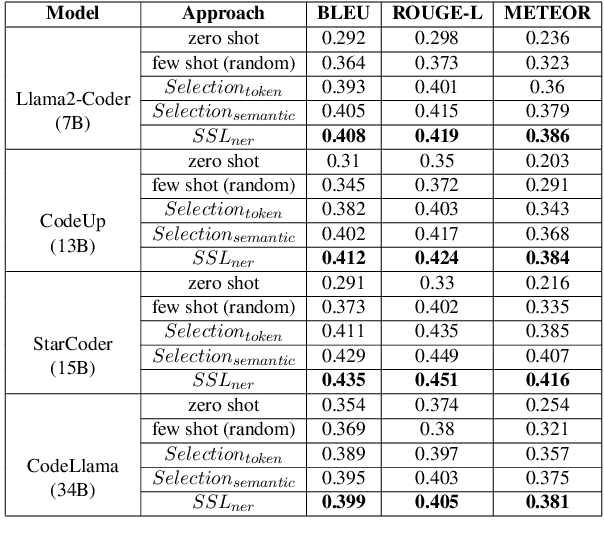
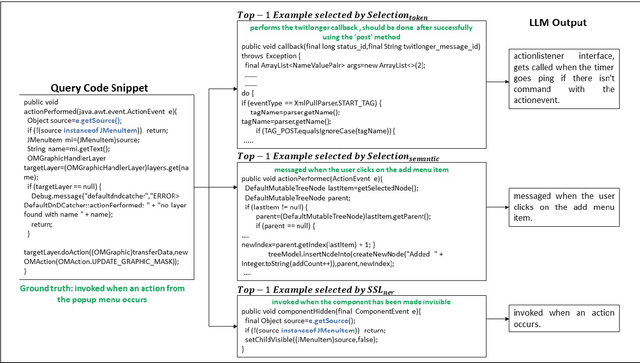
Code explanation plays a crucial role in the software engineering domain, aiding developers in grasping code functionality efficiently. Recent work shows that the performance of LLMs for code explanation improves in a few-shot setting, especially when the few-shot examples are selected intelligently. State-of-the-art approaches for such Selective Shot Learning (SSL) include token-based and embedding-based methods. However, these SSL approaches have been evaluated on proprietary LLMs, without much exploration on open-source Code-LLMs. Additionally, these methods lack consideration for programming language syntax. To bridge these gaps, we present a comparative study and propose a novel SSL method (SSL_ner) that utilizes entity information for few-shot example selection. We present several insights and show the effectiveness of SSL_ner approach over state-of-the-art methods across two datasets. To the best of our knowledge, this is the first systematic benchmarking of open-source Code-LLMs while assessing the performances of the various few-shot examples selection approaches for the code explanation task.
Digital Twin Generators for Disease Modeling
May 02, 2024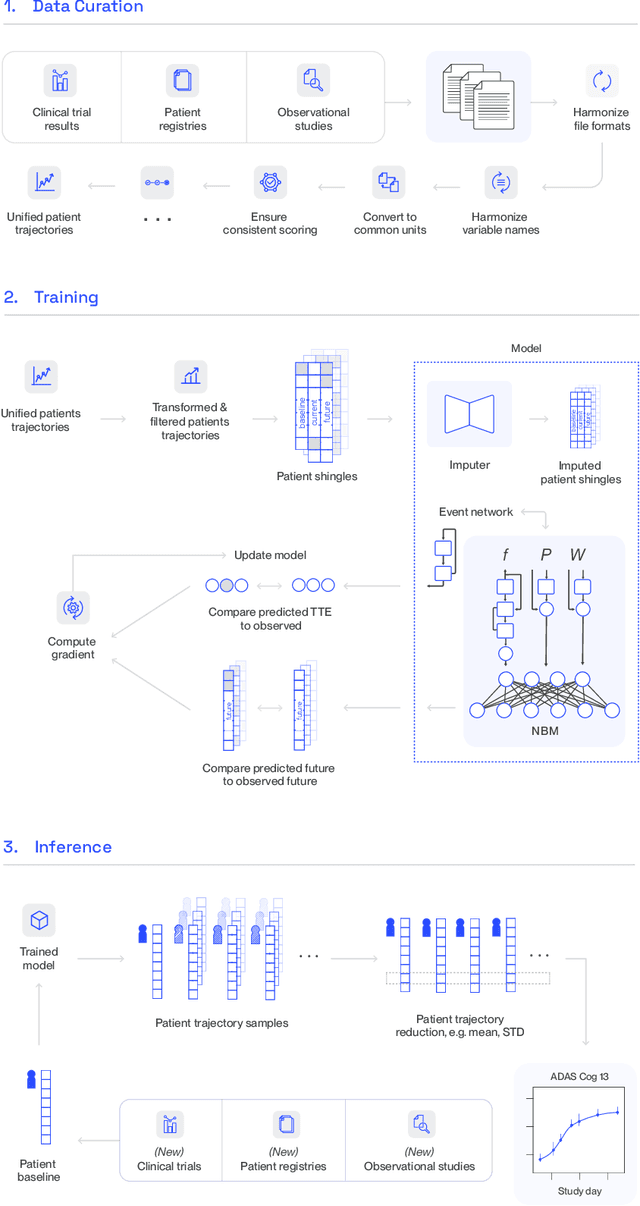
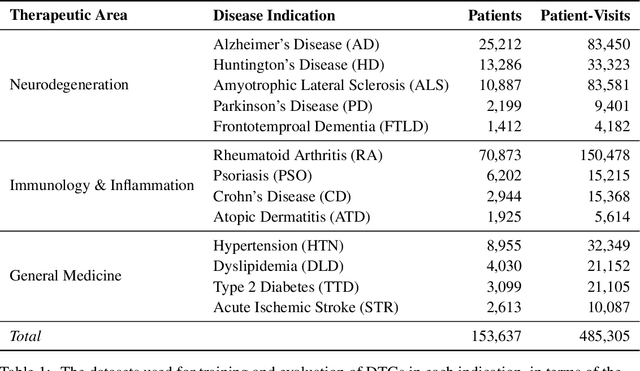
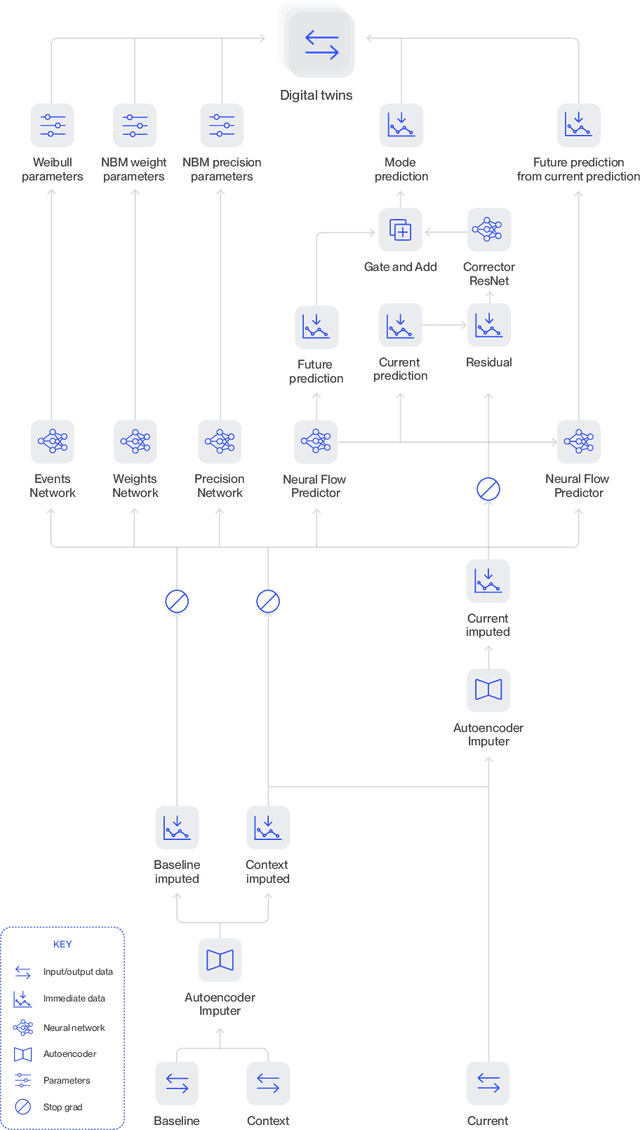
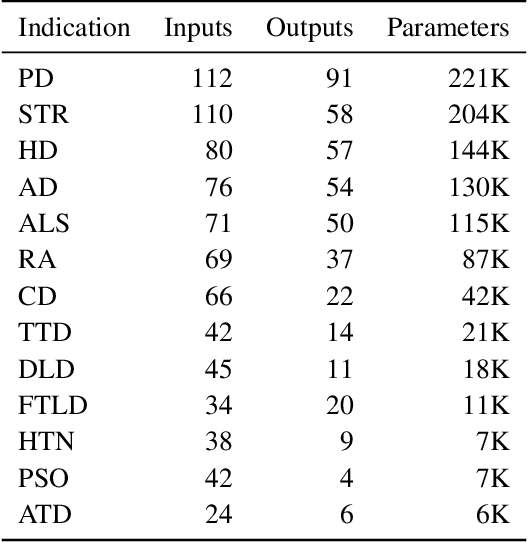
A patient's digital twin is a computational model that describes the evolution of their health over time. Digital twins have the potential to revolutionize medicine by enabling individual-level computer simulations of human health, which can be used to conduct more efficient clinical trials or to recommend personalized treatment options. Due to the overwhelming complexity of human biology, machine learning approaches that leverage large datasets of historical patients' longitudinal health records to generate patients' digital twins are more tractable than potential mechanistic models. In this manuscript, we describe a neural network architecture that can learn conditional generative models of clinical trajectories, which we call Digital Twin Generators (DTGs), that can create digital twins of individual patients. We show that the same neural network architecture can be trained to generate accurate digital twins for patients across 13 different indications simply by changing the training set and tuning hyperparameters. By introducing a general purpose architecture, we aim to unlock the ability to scale machine learning approaches to larger datasets and across more indications so that a digital twin could be created for any patient in the world.
Deep Learning Based Named Entity Recognition Models for Recipes
Feb 27, 2024


Food touches our lives through various endeavors, including flavor, nourishment, health, and sustainability. Recipes are cultural capsules transmitted across generations via unstructured text. Automated protocols for recognizing named entities, the building blocks of recipe text, are of immense value for various applications ranging from information extraction to novel recipe generation. Named entity recognition is a technique for extracting information from unstructured or semi-structured data with known labels. Starting with manually-annotated data of 6,611 ingredient phrases, we created an augmented dataset of 26,445 phrases cumulatively. Simultaneously, we systematically cleaned and analyzed ingredient phrases from RecipeDB, the gold-standard recipe data repository, and annotated them using the Stanford NER. Based on the analysis, we sampled a subset of 88,526 phrases using a clustering-based approach while preserving the diversity to create the machine-annotated dataset. A thorough investigation of NER approaches on these three datasets involving statistical, fine-tuning of deep learning-based language models and few-shot prompting on large language models (LLMs) provides deep insights. We conclude that few-shot prompting on LLMs has abysmal performance, whereas the fine-tuned spaCy-transformer emerges as the best model with macro-F1 scores of 95.9%, 96.04%, and 95.71% for the manually-annotated, augmented, and machine-annotated datasets, respectively.
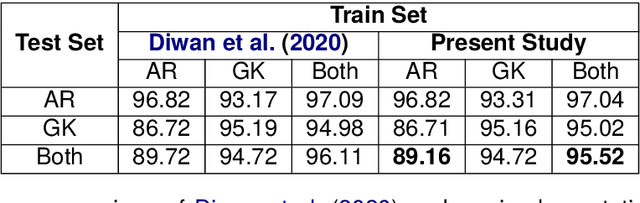
Sparse Graph Representations for Procedural Instructional Documents
Feb 06, 2024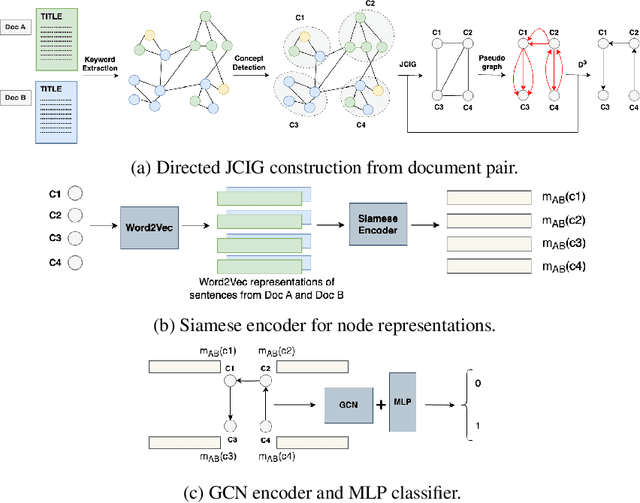

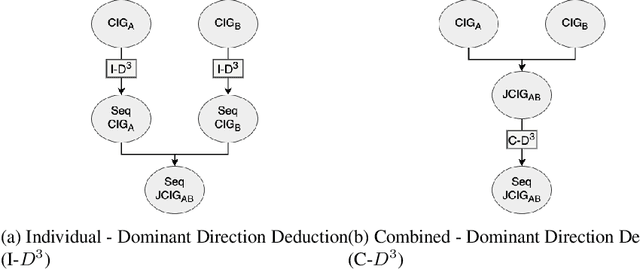
Computation of document similarity is a critical task in various NLP domains that has applications in deduplication, matching, and recommendation. Traditional approaches for document similarity computation include learning representations of documents and employing a similarity or a distance function over the embeddings. However, pairwise similarities and differences are not efficiently captured by individual representations. Graph representations such as Joint Concept Interaction Graph (JCIG) represent a pair of documents as a joint undirected weighted graph. JCIGs facilitate an interpretable representation of document pairs as a graph. However, JCIGs are undirected, and don't consider the sequential flow of sentences in documents. We propose two approaches to model document similarity by representing document pairs as a directed and sparse JCIG that incorporates sequential information. We propose two algorithms inspired by Supergenome Sorting and Hamiltonian Path that replace the undirected edges with directed edges. Our approach also sparsifies the graph to $O(n)$ edges from JCIG's worst case of $O(n^2)$. We show that our sparse directed graph model architecture consisting of a Siamese encoder and GCN achieves comparable results to the baseline on datasets not containing sequential information and beats the baseline by ten points on an instructional documents dataset containing sequential information.
Exploring Large Language Models for Code Explanation
Oct 25, 2023


Automating code documentation through explanatory text can prove highly beneficial in code understanding. Large Language Models (LLMs) have made remarkable strides in Natural Language Processing, especially within software engineering tasks such as code generation and code summarization. This study specifically delves into the task of generating natural-language summaries for code snippets, using various LLMs. The findings indicate that Code LLMs outperform their generic counterparts, and zero-shot methods yield superior results when dealing with datasets with dissimilar distributions between training and testing sets.