 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIDS: Malicious Agent Identification-based Data Security Model for Cloud Environments
Dec 19, 2024With the vigorous development of cloud computing, most organizations have shifted their data and applications to the cloud environment for storage, computation, and sharing purposes. During storage and data sharing across the participating entities, a malicious agent may gain access to outsourced data from the cloud environment. A malicious agent is an entity that deliberately breaches the data. This information accessed might be misused or revealed to unauthorized parties. Therefore, data protection and prediction of malicious agents have become a demanding task that needs to be addressed appropriately. To deal with this crucial and challenging issue, this paper presents a Malicious Agent Identification-based Data Security (MAIDS) Model which utilizes XGBoost machine learning classification algorithm for securing data allocation and communication among different participating entities in the cloud system. The proposed model explores and computes intended multiple security parameters associated with online data communication or transactions. Correspondingly, a security-focused knowledge database is produced for developing the XGBoost Classifier-based Malicious Agent Prediction (XC-MAP) unit. Unlike the existing approaches, which only identify malicious agents after data leaks, MAIDS proactively identifies malicious agents by examining their eligibility for respective data access. In this way, the model provides a comprehensive solution to safeguard crucial data from both intentional and non-intentional breaches, by granting data to authorized agents only by evaluating the agents behavior and predicting the malicious agent before granting data.
* 28 pages, 10 figures
A Global Cybersecurity Standardization Framework for Healthcare Informatics
Oct 06, 2024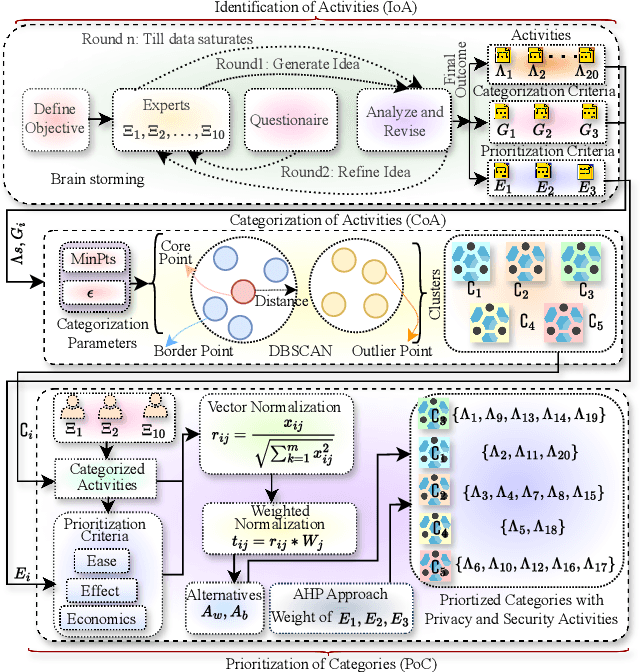
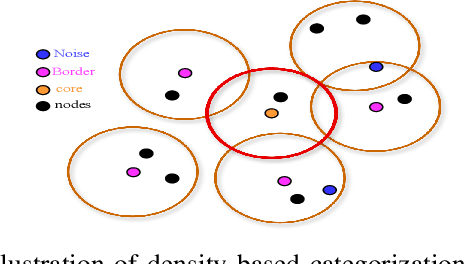
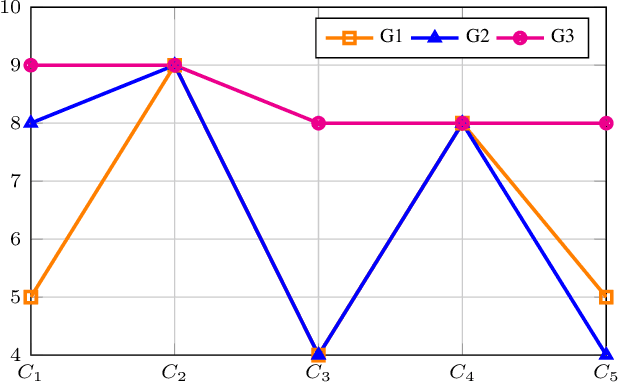
Healthcare has witnessed an increased digitalization in the post-COVID world. Technologies such as the medical internet of things and wearable devices are generating a plethora of data available on the cloud anytime from anywhere. This data can be analyzed using advanced artificial intelligence techniques for diagnosis, prognosis, or even treatment of disease. This advancement comes with a major risk to protecting and securing protected health information (PHI). The prevailing regulations for preserving PHI are neither comprehensive nor easy to implement. The study first identifies twenty activities crucial for privacy and security, then categorizes them into five homogeneous categories namely: $\complement_1$ (Policy and Compliance Management), $\complement_2$ (Employee Training and Awareness), $\complement_3$ (Data Protection and Privacy Control), $\complement_4$ (Monitoring and Response), and $\complement_5$ (Technology and Infrastructure Security) and prioritizes these categories to provide a framework for the implementation of privacy and security in a wise manner. The framework utilized the Delphi Method to identify activities, criteria for categorization, and prioritization. Categorization is based on the Density-Based Spatial Clustering of Applications with Noise (DBSCAN), and prioritization is performed using a Technique for Order of Preference by Similarity to the Ideal Solution (TOPSIS). The outcomes conclude that $\complement_3$ activities should be given first preference in implementation and followed by $\complement_1$ and $\complement_2$ activities. Finally, $\complement_4$ and $\complement_5$ should be implemented. The prioritized view of identified clustered healthcare activities related to security and privacy, are useful for healthcare policymakers and healthcare informatics professionals.
A Global Medical Data Security and Privacy Preserving Standards Identification Framework for Electronic Healthcare Consumers
Oct 04, 2024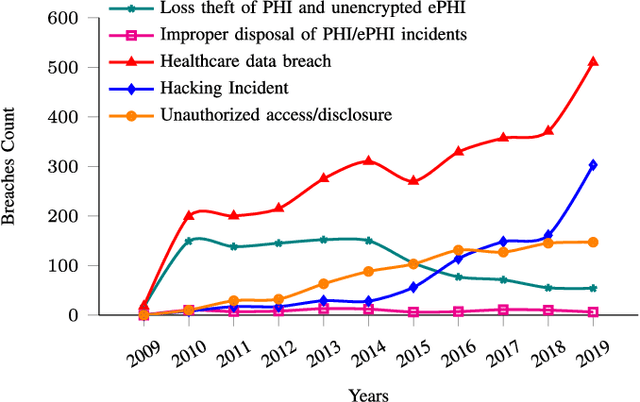
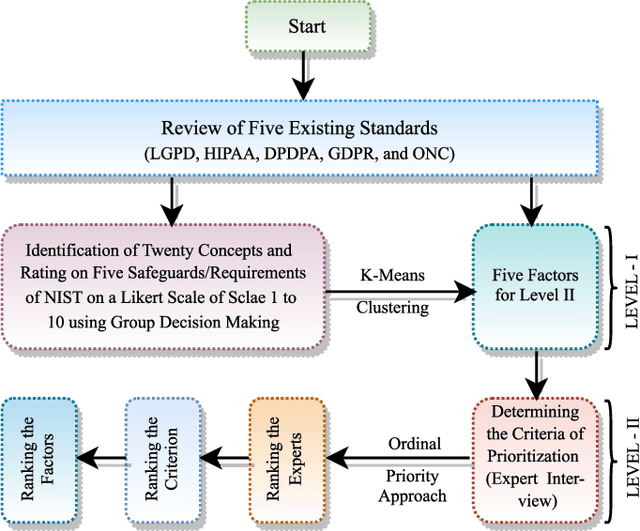
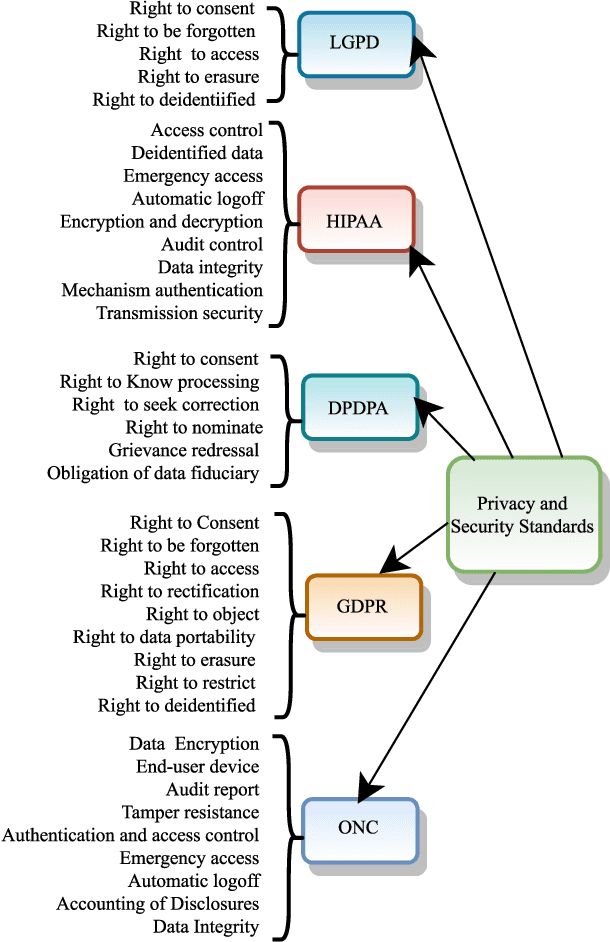
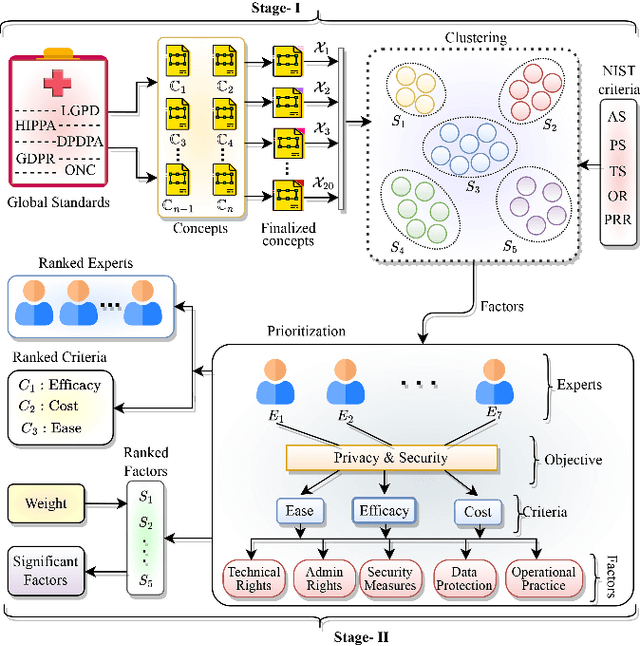
Electronic Health Records (EHR) are crucial for the success of digital healthcare, with a focus on putting consumers at the center of this transformation. However, the digitalization of healthcare records brings along security and privacy risks for personal data. The major concern is that different countries have varying standards for the security and privacy of medical data. This paper proposed a novel and comprehensive framework to standardize these rules globally, bringing them together on a common platform. To support this proposal, the study reviews existing literature to understand the research interest in this issue. It also examines six key laws and standards related to security and privacy, identifying twenty concepts. The proposed framework utilized K-means clustering to categorize these concepts and identify five key factors. Finally, an Ordinal Priority Approach is applied to determine the preferred implementation of these factors in the context of EHRs. The proposed study provides a descriptive then prescriptive framework for the implementation of privacy and security in the context of electronic health records. Therefore, the findings of the proposed framework are useful for professionals and policymakers in improving the security and privacy associated with EHRs.
A Forecasting-Based DLP Approach for Data Security
Dec 21, 2023Sensitive data leakage is the major growing problem being faced by enterprises in this technical era. Data leakage causes severe threats for organization of data safety which badly affects the reputation of organizations. Data leakage is the flow of sensitive data/information from any data holder to an unauthorized destination. Data leak prevention (DLP) is set of techniques that try to alleviate the threats which may hinder data security. DLP unveils guilty user responsible for data leakage and ensures that user without appropriate permission cannot access sensitive data and also provides protection to sensitive data if sensitive data is shared accidentally. In this paper, data leakage prevention (DLP) model is used to restrict/grant data access permission to user, based on the forecast of their access to data. This study provides a DLP solution using data statistical analysis to forecast the data access possibilities of any user in future based on the access to data in the past. The proposed approach makes use of renowned simple piecewise linear function for learning/training to model. The results show that the proposed DLP approach with high level of precision can correctly classify between users even in cases of extreme data access.
A Learning oriented DLP System based on Classification Model
Dec 21, 2023Data is the key asset for organizations and data sharing is lifeline for organization growth; which may lead to data loss. Data leakage is the most critical issue being faced by organizations. In order to mitigate the data leakage issues data leakage prevention systems (DLPSs) are deployed at various levels by the organizations. DLPSs are capable to protect all kind of data i.e. DAR, DIM/DIT, DIU. Statistical analysis, regular expression, data fingerprinting are common approaches exercised in DLP system. Out of these techniques; statistical analysis approach is most appropriate for proposed DLP model of data security. This paper defines a statistical DLP model for document classification. Model uses various statistical approaches like TF-IDF (Term Frequency- Inverse Document Frequency) a renowned term count/weighing function, Vectorization, Gradient boosting document classification etc. to classify the documents before allowing any access to it. Machine learning is used to test and train the model. Proposed model also introduces an extremely efficient and more accurate approach; IGBCA (Improvised Gradient Boosting Classification Algorithm); for document classification, to prevent them from possible data leakage. Results depicts that proposed model can classify documents with high accuracy and on basis of which data can be prevented from being loss.