 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateMirage: An Explainable Multi-Dimensional Dataset for Decoding Faux Hate and Subtle Online Abuse
Mar 03, 2026Subtle and indirect hate speech remains an underexplored challenge in online safety research, particularly when harmful intent is embedded within misleading or manipulative narratives. Existing hate speech datasets primarily capture overt toxicity, underrepresenting the nuanced ways misinformation can incite or normalize hate. To address this gap, we present HateMirage, a novel dataset of Faux Hate comments designed to advance reasoning and explainability research on hate emerging from fake or distorted narratives. The dataset was constructed by identifying widely debunked misinformation claims from fact-checking sources and tracing related YouTube discussions, resulting in 4,530 user comments. Each comment is annotated along three interpretable dimensions: Target (who is affected), Intent (the underlying motivation or goal behind the comment), and Implication (its potential social impact). Unlike prior explainability datasets such as HateXplain and HARE, which offer token-level or single-dimensional reasoning, HateMirage introduces a multi-dimensional explanation framework that captures the interplay between misinformation, harm, and social consequence. We benchmark multiple open-source language models on HateMirage using ROUGE-L F1 and Sentence-BERT similarity to assess explanation coherence. Results suggest that explanation quality may depend more on pretraining diversity and reasoning-oriented data rather than on model scale alone. By coupling misinformation reasoning with harm attribution, HateMirage establishes a new benchmark for interpretable hate detection and responsible AI research.
Sentiment-guided Commonsense-aware Response Generation for Mental Health Counseling
Jan 06, 2025



The crisis of mental health issues is escalating. Effective counseling serves as a critical lifeline for individuals suffering from conditions like PTSD, stress, etc. Therapists forge a crucial therapeutic bond with clients, steering them towards positivity. Unfortunately, the massive shortage of professionals, high costs, and mental health stigma pose significant barriers to consulting therapists. As a substitute, Virtual Mental Health Assistants (VMHAs) have emerged in the digital healthcare space. However, most existing VMHAs lack the commonsense to understand the nuanced sentiments of clients to generate effective responses. To this end, we propose EmpRes, a novel sentiment-guided mechanism incorporating commonsense awareness for generating responses. By leveraging foundation models and harnessing commonsense knowledge, EmpRes aims to generate responses that effectively shape the client's sentiment towards positivity. We evaluate the performance of EmpRes on HOPE, a benchmark counseling dataset, and observe a remarkable performance improvement compared to the existing baselines across a suite of qualitative and quantitative metrics. Moreover, our extensive empirical analysis and human evaluation show that the generation ability of EmpRes is well-suited and, in some cases, surpasses the gold standard. Further, we deploy EmpRes as a chat interface for users seeking mental health support. We address the deployed system's effectiveness through an exhaustive user study with a significant positive response. Our findings show that 91% of users find the system effective, 80% express satisfaction, and over 85.45% convey a willingness to continue using the interface and recommend it to others, demonstrating the practical applicability of EmpRes in addressing the pressing challenges of mental health support, emphasizing user feedback, and ethical considerations in a real-world context.
QUENCH: Measuring the gap between Indic and Non-Indic Contextual General Reasoning in LLMs
Dec 16, 2024



The rise of large language models (LLMs) has created a need for advanced benchmarking systems beyond traditional setups. To this end, we introduce QUENCH, a novel text-based English Quizzing Benchmark manually curated and transcribed from YouTube quiz videos. QUENCH possesses masked entities and rationales for the LLMs to predict via generation. At the intersection of geographical context and common sense reasoning, QUENCH helps assess world knowledge and deduction capabilities of LLMs via a zero-shot, open-domain quizzing setup. We perform an extensive evaluation on 7 LLMs and 4 metrics, investigating the influence of model size, prompting style, geographical context, and gold-labeled rationale generation. The benchmarking concludes with an error analysis to which the LLMs are prone.
No perspective, no perception!! Perspective-aware Healthcare Answer Summarization
Jun 13, 2024

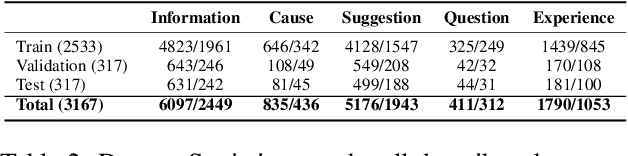

Healthcare Community Question Answering (CQA) forums offer an accessible platform for individuals seeking information on various healthcare-related topics. People find such platforms suitable for self-disclosure, seeking medical opinions, finding simplified explanations for their medical conditions, and answering others' questions. However, answers on these forums are typically diverse and prone to off-topic discussions. It can be challenging for readers to sift through numerous answers and extract meaningful insights, making answer summarization a crucial task for CQA forums. While several efforts have been made to summarize the community answers, most of them are limited to the open domain and overlook the different perspectives offered by these answers. To address this problem, this paper proposes a novel task of perspective-specific answer summarization. We identify various perspectives, within healthcare-related responses and frame a perspective-driven abstractive summary covering all responses. To achieve this, we annotate 3167 CQA threads with 6193 perspective-aware summaries in our PUMA dataset. Further, we propose PLASMA, a prompt-driven controllable summarization model. To encapsulate the perspective-specific conditions, we design an energy-controlled loss function for the optimization. We also leverage the prefix tuner to learn the intricacies of the health-care perspective summarization. Our evaluation against five baselines suggests the superior performance of PLASMA by a margin of 1.5-21% improvement. We supplement our experiments with ablation and qualitative analysis.
Overview of the HASOC Subtrack at FIRE 2023: Identification of Tokens Contributing to Explicit Hate in English by Span Detection
Nov 16, 2023As hate speech continues to proliferate on the web, it is becoming increasingly important to develop computational methods to mitigate it. Reactively, using black-box models to identify hateful content can perplex users as to why their posts were automatically flagged as hateful. On the other hand, proactive mitigation can be achieved by suggesting rephrasing before a post is made public. However, both mitigation techniques require information about which part of a post contains the hateful aspect, i.e., what spans within a text are responsible for conveying hate. Better detection of such spans can significantly reduce explicitly hateful content on the web. To further contribute to this research area, we organized HateNorm at HASOC-FIRE 2023, focusing on explicit span detection in English Tweets. A total of 12 teams participated in the competition, with the highest macro-F1 observed at 0.58.
MEMEX: Detecting Explanatory Evidence for Memes via Knowledge-Enriched Contextualization
May 25, 2023
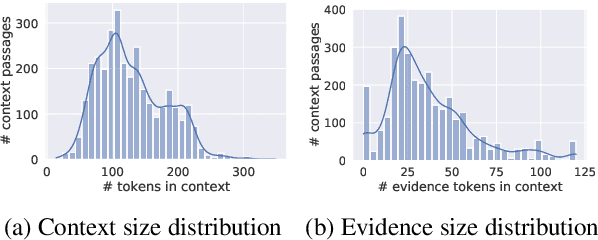


Memes are a powerful tool for communication over social media. Their affinity for evolving across politics, history, and sociocultural phenomena makes them an ideal communication vehicle. To comprehend the subtle message conveyed within a meme, one must understand the background that facilitates its holistic assimilation. Besides digital archiving of memes and their metadata by a few websites like knowyourmeme.com, currently, there is no efficient way to deduce a meme's context dynamically. In this work, we propose a novel task, MEMEX - given a meme and a related document, the aim is to mine the context that succinctly explains the background of the meme. At first, we develop MCC (Meme Context Corpus), a novel dataset for MEMEX. Further, to benchmark MCC, we propose MIME (MultImodal Meme Explainer), a multimodal neural framework that uses common sense enriched meme representation and a layered approach to capture the cross-modal semantic dependencies between the meme and the context. MIME surpasses several unimodal and multimodal systems and yields an absolute improvement of ~ 4% F1-score over the best baseline. Lastly, we conduct detailed analyses of MIME's performance, highlighting the aspects that could lead to optimal modeling of cross-modal contextual associations.
Counterspeeches up my sleeve! Intent Distribution Learning and Persistent Fusion for Intent-Conditioned Counterspeech Generation
May 23, 2023



Counterspeech has been demonstrated to be an efficacious approach for combating hate speech. While various conventional and controlled approaches have been studied in recent years to generate counterspeech, a counterspeech with a certain intent may not be sufficient in every scenario. Due to the complex and multifaceted nature of hate speech, utilizing multiple forms of counter-narratives with varying intents may be advantageous in different circumstances. In this paper, we explore intent-conditioned counterspeech generation. At first, we develop IntentCONAN, a diversified intent-specific counterspeech dataset with 6831 counterspeeches conditioned on five intents, i.e., informative, denouncing, question, positive, and humour. Subsequently, we propose QUARC, a two-stage framework for intent-conditioned counterspeech generation. QUARC leverages vector-quantized representations learned for each intent category along with PerFuMe, a novel fusion module to incorporate intent-specific information into the model. Our evaluation demonstrates that QUARC outperforms several baselines by an average of 10% across evaluation metrics. An extensive human evaluation supplements our hypothesis of better and more appropriate responses than comparative systems.
Response-act Guided Reinforced Dialogue Generation for Mental Health Counseling
Jan 30, 2023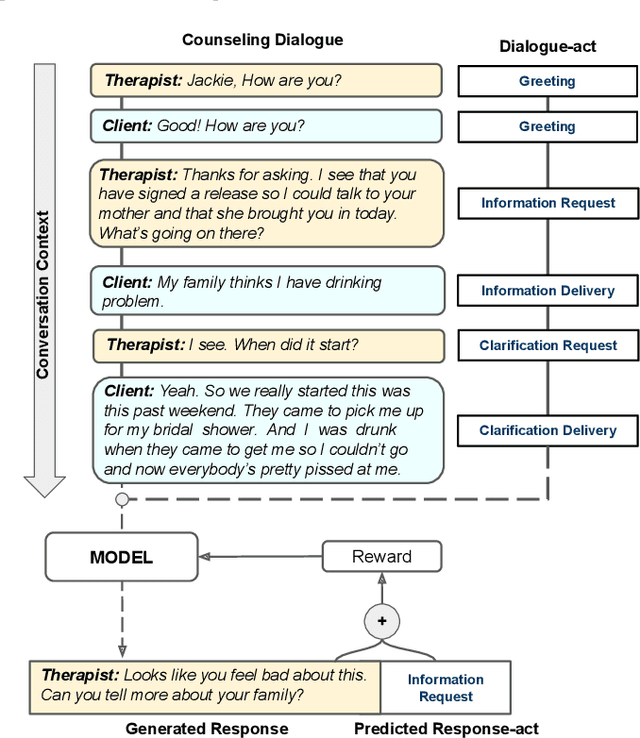
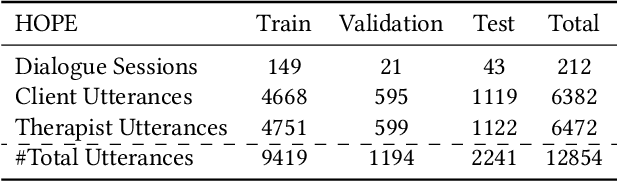
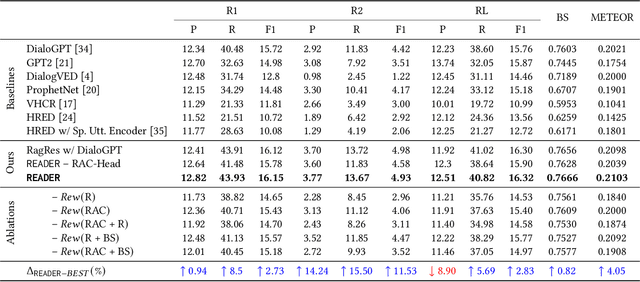
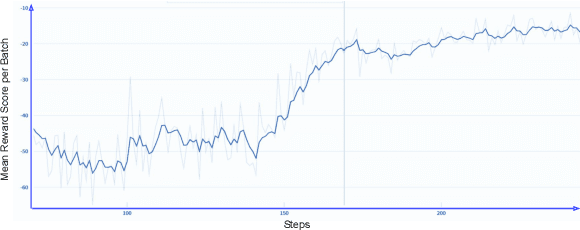
Virtual Mental Health Assistants (VMHAs) have become a prevalent method for receiving mental health counseling in the digital healthcare space. An assistive counseling conversation commences with natural open-ended topics to familiarize the client with the environment and later converges into more fine-grained domain-specific topics. Unlike other conversational systems, which are categorized as open-domain or task-oriented systems, VMHAs possess a hybrid conversational flow. These counseling bots need to comprehend various aspects of the conversation, such as dialogue-acts, intents, etc., to engage the client in an effective conversation. Although the surge in digital health research highlights applications of many general-purpose response generation systems, they are barely suitable in the mental health domain -- the prime reason is the lack of understanding in mental health counseling. Moreover, in general, dialogue-act guided response generators are either limited to a template-based paradigm or lack appropriate semantics. To this end, we propose READER -- a REsponse-Act guided reinforced Dialogue genERation model for the mental health counseling conversations. READER is built on transformer to jointly predict a potential dialogue-act d(t+1) for the next utterance (aka response-act) and to generate an appropriate response u(t+1). Through the transformer-reinforcement-learning (TRL) with Proximal Policy Optimization (PPO), we guide the response generator to abide by d(t+1) and ensure the semantic richness of the responses via BERTScore in our reward computation. We evaluate READER on HOPE, a benchmark counseling conversation dataset and observe that it outperforms several baselines across several evaluation metrics -- METEOR, ROUGE, and BERTScore. We also furnish extensive qualitative and quantitative analyses on results, including error analysis, human evaluation, etc.
Characterizing the Entities in Harmful Memes: Who is the Hero, the Villain, the Victim?
Jan 26, 2023



Memes can sway people's opinions over social media as they combine visual and textual information in an easy-to-consume manner. Since memes instantly turn viral, it becomes crucial to infer their intent and potentially associated harmfulness to take timely measures as needed. A common problem associated with meme comprehension lies in detecting the entities referenced and characterizing the role of each of these entities. Here, we aim to understand whether the meme glorifies, vilifies, or victimizes each entity it refers to. To this end, we address the task of role identification of entities in harmful memes, i.e., detecting who is the 'hero', the 'villain', and the 'victim' in the meme, if any. We utilize HVVMemes - a memes dataset on US Politics and Covid-19 memes, released recently as part of the CONSTRAINT@ACL-2022 shared-task. It contains memes, entities referenced, and their associated roles: hero, villain, victim, and other. We further design VECTOR (Visual-semantic role dEteCToR), a robust multi-modal framework for the task, which integrates entity-based contextual information in the multi-modal representation and compare it to several standard unimodal (text-only or image-only) or multi-modal (image+text) models. Our experimental results show that our proposed model achieves an improvement of 4% over the best baseline and 1% over the best competing stand-alone submission from the shared-task. Besides divulging an extensive experimental setup with comparative analyses, we finally highlight the challenges encountered in addressing the complex task of semantic role labeling within memes.
What do you MEME? Generating Explanations for Visual Semantic Role Labelling in Memes
Dec 20, 2022



Memes are powerful means for effective communication on social media. Their effortless amalgamation of viral visuals and compelling messages can have far-reaching implications with proper marketing. Previous research on memes has primarily focused on characterizing their affective spectrum and detecting whether the meme's message insinuates any intended harm, such as hate, offense, racism, etc. However, memes often use abstraction, which can be elusive. Here, we introduce a novel task - EXCLAIM, generating explanations for visual semantic role labeling in memes. To this end, we curate ExHVV, a novel dataset that offers natural language explanations of connotative roles for three types of entities - heroes, villains, and victims, encompassing 4,680 entities present in 3K memes. We also benchmark ExHVV with several strong unimodal and multimodal baselines. Moreover, we posit LUMEN, a novel multimodal, multi-task learning framework that endeavors to address EXCLAIM optimally by jointly learning to predict the correct semantic roles and correspondingly to generate suitable natural language explanations. LUMEN distinctly outperforms the best baseline across 18 standard natural language generation evaluation metrics. Our systematic evaluation and analyses demonstrate that characteristic multimodal cues required for adjudicating semantic roles are also helpful for generating suitable explanations.