 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning
Dec 19, 2023



Large Language Models (LLM) exhibit zero-shot mathematical reasoning capacity as a behavior emergent with scale, commonly manifesting as chain-of-thoughts (CoT) reasoning. However, multiple empirical findings suggest that this prowess is exclusive to LLMs with exorbitant sizes (beyond 50 billion parameters). Meanwhile, educational neuroscientists suggest that symbolic algebraic manipulation be introduced around the same time as arithmetic word problems to modularize language-to-formulation, symbolic manipulation of the formulation, and endgame arithmetic. In this paper, we start with the hypothesis that much smaller LMs, which are weak at multi-step reasoning, can achieve reasonable arithmetic reasoning if arithmetic word problems are posed as a formalize-then-solve task. In our architecture, which we call SYRELM, the LM serves the role of a translator to map natural language arithmetic questions into a formal language (FL) description. A symbolic solver then evaluates the FL expression to obtain the answer. A small frozen LM, equipped with an efficient low-rank adapter, is capable of generating FL expressions that incorporate natural language descriptions of the arithmetic problem (e.g., variable names and their purposes, formal expressions combining variables, etc.). We adopt policy-gradient reinforcement learning to train the adapted LM, informed by the non-differentiable symbolic solver. This marks a sharp departure from the recent development in tool-augmented LLMs, in which the external tools (e.g., calculator, Web search, etc.) are essentially detached from the learning phase of the LM. SYRELM shows massive improvements (e.g., +30.65 absolute point improvement in accuracy on the SVAMP dataset using GPT-J 6B model) over base LMs, while keeping our testbed easy to diagnose, interpret and within reach of most researchers.
Response-act Guided Reinforced Dialogue Generation for Mental Health Counseling
Jan 30, 2023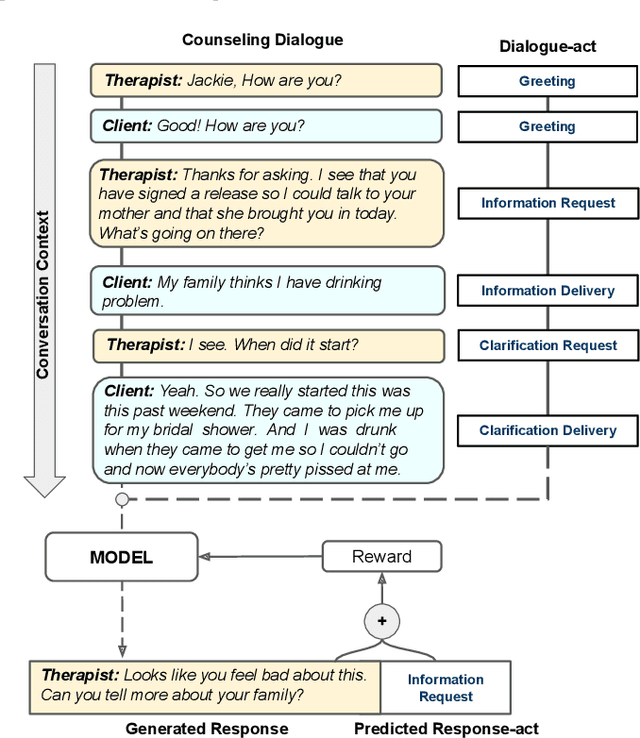
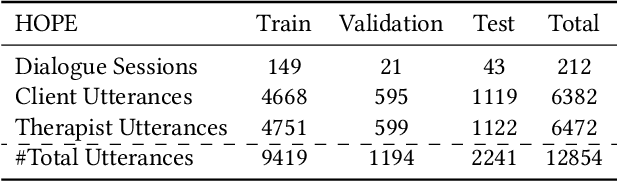
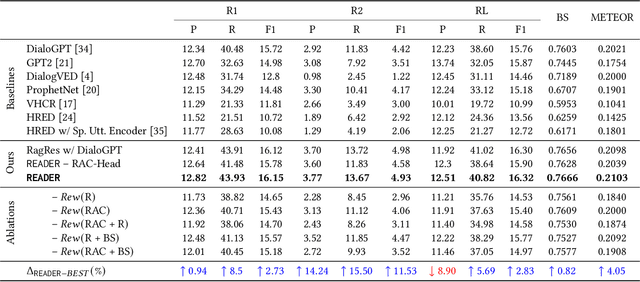
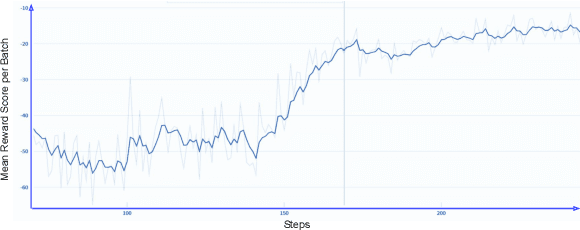
Virtual Mental Health Assistants (VMHAs) have become a prevalent method for receiving mental health counseling in the digital healthcare space. An assistive counseling conversation commences with natural open-ended topics to familiarize the client with the environment and later converges into more fine-grained domain-specific topics. Unlike other conversational systems, which are categorized as open-domain or task-oriented systems, VMHAs possess a hybrid conversational flow. These counseling bots need to comprehend various aspects of the conversation, such as dialogue-acts, intents, etc., to engage the client in an effective conversation. Although the surge in digital health research highlights applications of many general-purpose response generation systems, they are barely suitable in the mental health domain -- the prime reason is the lack of understanding in mental health counseling. Moreover, in general, dialogue-act guided response generators are either limited to a template-based paradigm or lack appropriate semantics. To this end, we propose READER -- a REsponse-Act guided reinforced Dialogue genERation model for the mental health counseling conversations. READER is built on transformer to jointly predict a potential dialogue-act d(t+1) for the next utterance (aka response-act) and to generate an appropriate response u(t+1). Through the transformer-reinforcement-learning (TRL) with Proximal Policy Optimization (PPO), we guide the response generator to abide by d(t+1) and ensure the semantic richness of the responses via BERTScore in our reward computation. We evaluate READER on HOPE, a benchmark counseling conversation dataset and observe that it outperforms several baselines across several evaluation metrics -- METEOR, ROUGE, and BERTScore. We also furnish extensive qualitative and quantitative analyses on results, including error analysis, human evaluation, etc.